How was this content?
- Learn
- Build AI agents that scale: Grow to 10k users with event-driven architectures
Build AI agents that scale: Grow to 10k users with event-driven architectures

Scaling AI applications from hundreds to thousands of users reveals a critical architectural inflection point. The synchronous architecture that enables rapid prototyping becomes the bottleneck preventing growth. For startups building AI applications on AWS, whether analyzing documents, generating content, or enriching data, processing workloads can take seconds or minutes per request. Multiply that by hundreds of concurrent users, and synchronous architectures exhaust connection pools, exceed timeout thresholds, and block deployment velocity.
This article outlines how to scale AI document processing from 100 to 10,000 users using event-driven architectures on AWS. Intelligent Document Processing (IDP) serves as the primary example throughout, though these patterns apply to any AI workload requiring multi-step processing.
When monoliths work (and when they don't)
At a few hundred users, a monolithic document processing pipeline is often the right choice. A single compute instance receives document uploads through an API, calls Amazon Textract (a machine learning service that automatically extracts text, handwriting, and data from scanned documents) to extract structured data, validates the results against business rules, enriches the data with additional context, and writes the final output to a database. The entire workflow executes synchronously within a single request-response cycle. For an early-stage startup, this architecture has meaningful advantages: it's conceptually simple, easy to debug, and requires minimal operational overhead.
But this architecture carries assumptions that become liabilities at scale. Synchronous processing assumes that each step completes quickly enough to hold an HTTP connection open. It assumes that a spike in document uploads won't overwhelm the validation step, which may be CPU-intensive. It assumes that a failure in the enrichment stage doesn't require reprocessing the entire document from scratch. These assumptions hold at a few hundred users. At scale, they begin to fracture.
The breaking point
At 1,000 users, the first cracks appear. Textract extraction, which might take 2-3 seconds per document, starts to create a backlog during peak hours. The validation step, running in the same process, can't be scaled independently. If extraction is slow, validation waits. If validation is slow, enrichment waits. The entire pipeline becomes as slow as its slowest component. Connection timeouts increase. Users see "processing" spinners that never resolve. The engineering team adds more instances, but this only delays the problem, rather than solving the architectural bottleneck.
By 5,000 users, the monolith is untenable. A single failure in the enrichment step cascades backward, blocking validation and extraction. The team can't deploy updates to the validation logic without restarting the entire pipeline. Scaling extraction independently of validation is impossible, as they're coupled in the same codebase, running in the same process. At 10,000 users, you need a different approach.
Moving to event-driven architectures
Event-driven architectures resolve this constraint by replacing synchronous calls with asynchronous events. Instead of one component directly invoking the next, each component publishes an event when it completes its work and subscribes to events that signal when it should begin. The document upload API publishes an event when a document arrives. The document upload API publishes an event when a document arrives. Each subsequent component, from extraction through validation to enrichment, subscribes to the previous event, does its work, and publishes the next one.
This pattern introduces a layer of indirection: an event bus like Amazon EventBridge (a serverless service that connects applications using events) that sits between producers and consumers. Producers and consumers have no direct knowledge of each other. This decoupling is the architectural shift that enables independent scaling, failure isolation, and deployment velocity.
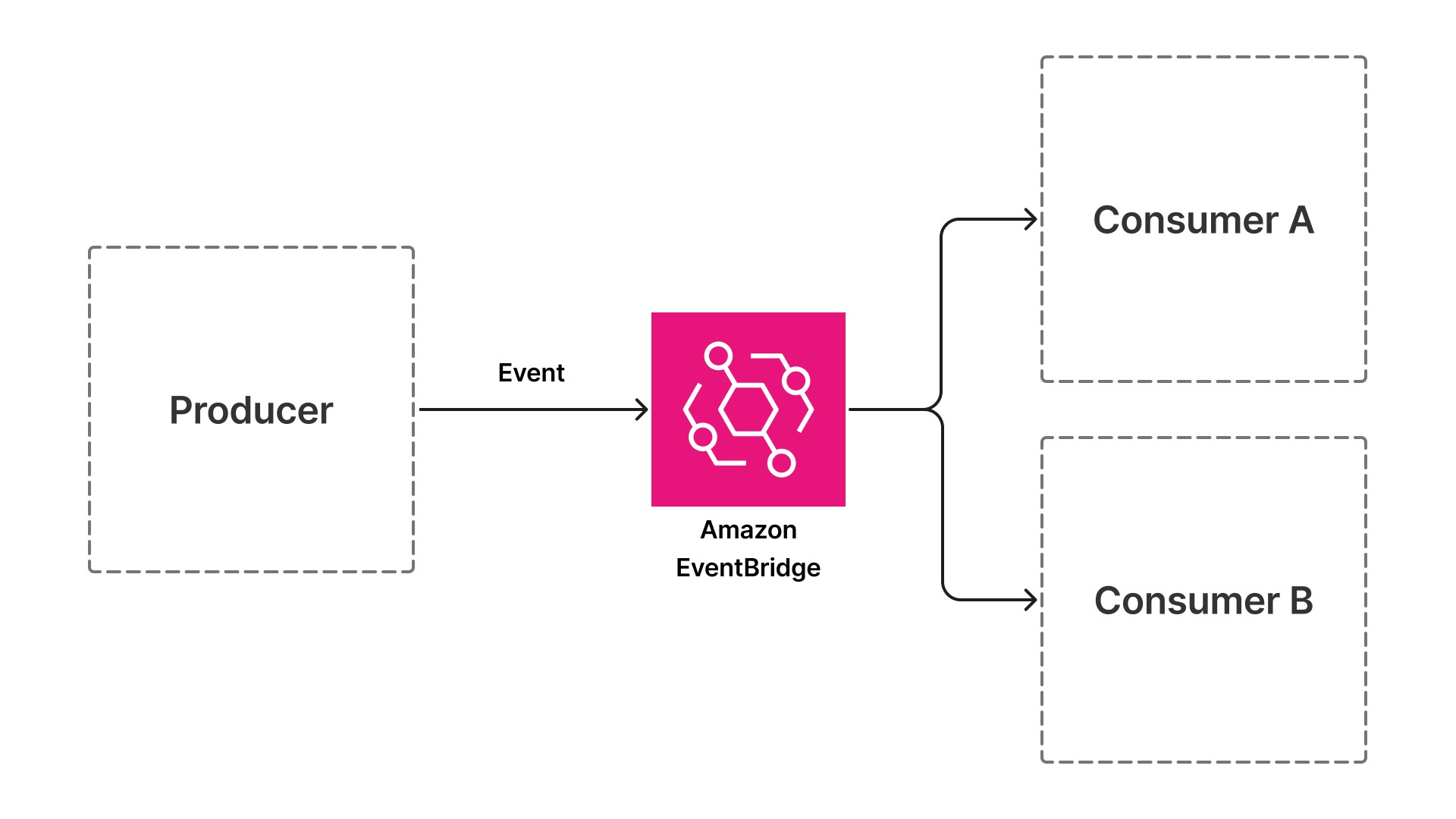
Why this matters for AI workloads
AI workloads benefit particularly from this pattern. Textract extraction might take 2 seconds for a simple invoice and 30 seconds for a complex contract. Amazon Bedrock enrichment might take 1 second for classification and 10 seconds for entity extraction with a large language model. In a synchronous architecture, these variable processing times create unpredictable latency. In an event-driven architecture, each step processes at its own pace, publishing events when complete. The pipeline's throughput is determined by the independent scaling behavior of each stage, not constrained by its slowest component. For bursty AI workloads, this also means paying only for what you use rather than provisioning for peak capacity.
When to make the transition
This pattern becomes essential when a startup reaches a specific inflection point: when the cost of synchronous bottlenecks (lost customers, engineering time spent firefighting, inability to deploy updates safely) exceeds the cost of managing asynchronous complexity. You've reached this point when you start seeing these signs:
- Connection timeout errors appear in logs during peak hours
- A single deployment requires coordinating changes across multiple teams
- You can't scale individual processing steps independently
- Failed processing requires reprocessing entire documents from scratch
- Your error rate increases proportionally with traffic
For early-stage startups with fewer than 500 users, event-driven architectures are often premature, as the operational overhead outweighs the benefits. For startups scaling from 1,000 to 10,000 users, it's a necessary transition.
Event-driven document processing in practice
Consider how this pattern applies to IDP. A fintech startup building a contract analysis platform for legal tech receives hundreds of contracts daily: NDAs, employment agreements, vendor contracts. Each document follows a multi-step workflow: upload, extraction, validation, enrichment, and storage. In an event-driven architecture, each step is an independent component triggered by events.
The workflow begins when a user uploads a contract to an Amazon Simple Storage Service (S3) bucket. S3 publishes an event (Object Created) to the EventBridge default bus. A component subscribed to this event retrieves the document and calls Textract to extract text, tables, and key-value pairs. Textract processes the document asynchronously (this is critical for large PDFs that might take 20-30 seconds to process) and when extraction completes, the component publishes an extraction.complete event with the extracted data.
A second component, subscribed to extraction.complete, validates the extracted data against business rules. Does the contract include required clauses? Are the dates formatted correctly? Is the counterparty name present? If validation passes, the component publishes a validation.passed event. If validation fails, it publishes a validation.failed event and routes the document to a manual review queue (an Amazon SQS queue consumed by a human in the loop workflow).
A third component, subscribed to validation.passed, enriches the contract data using Bedrock. It might classify the contract type (NDA, employment, vendor), extract entities (company names, dates, monetary amounts), or summarize key terms using a large language model like Anthropic's Claude. Bedrock's serverless inference means the component doesn't need to manage GPU infrastructure, it simply calls the Bedrock API and receives structured output. When enrichment completes, the component publishes an enrichment.finished event and writes the final structured data toAmazon DynamoDB(a serverless NoSQL database with millisecond latency at any scale).
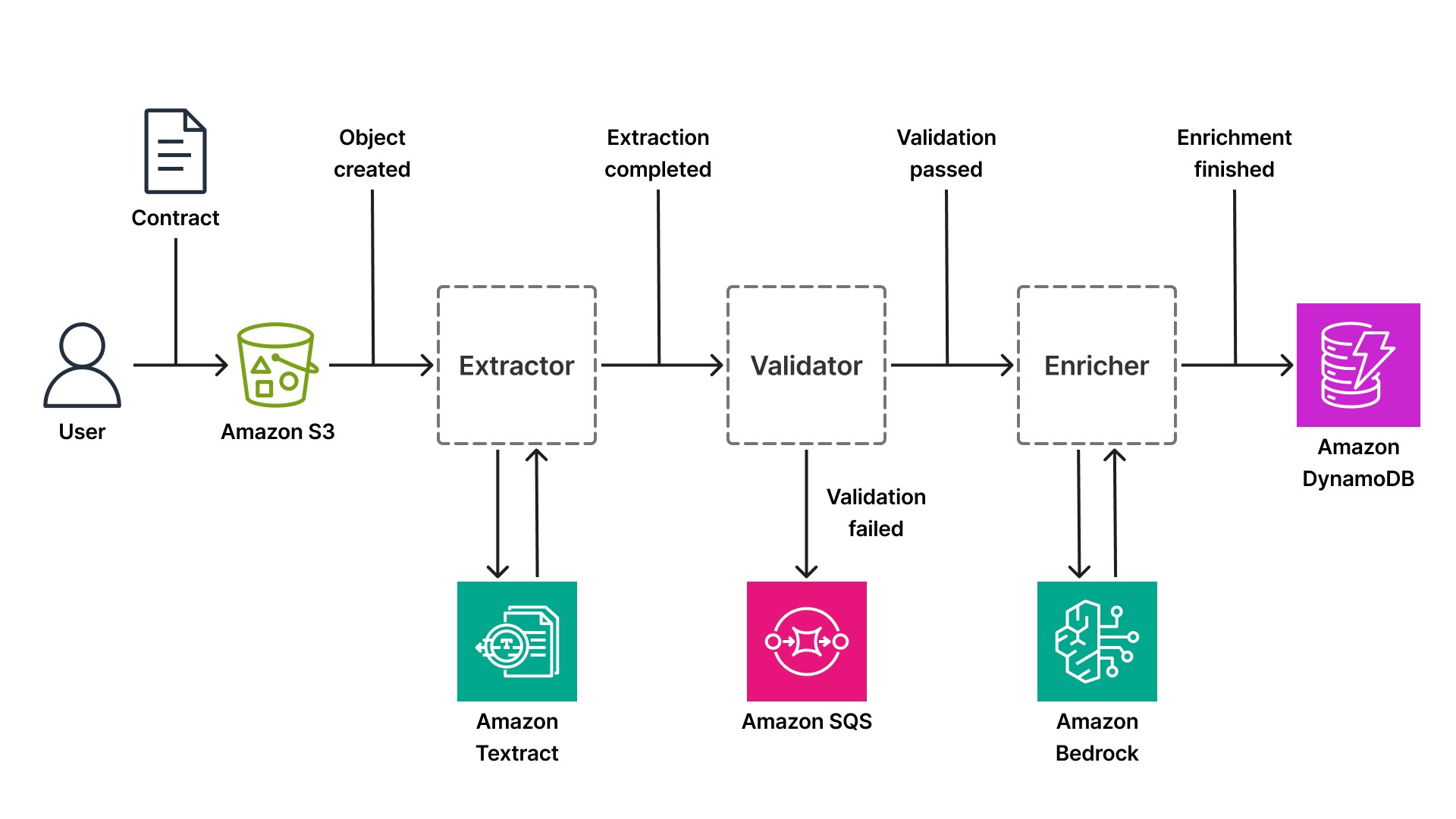
Whether the pipeline processes contracts, medical records, or financial statements, the event-driven pattern remains the same. Only the AI service at each step changes. A medical records pipeline might use Amazon Comprehend Medical for entity extraction instead of Bedrock. A financial statement pipeline might use Textract's specialized AnalyzeExpense API. The architectural principle holds: each step publishes events, scales independently, and can be deployed without affecting other stages.
For developers building these pipelines, AWS has released Model Context Protocol (MCP) servers that integrate with AI coding assistants. The AWS Serverless MCP Server provides expertise to streamline how developers build serverless applications directly within the coding environment, reducing the time spent searching documentation.
The business case for decoupling
The business consequences of this architecture extend beyond technical elegance. Event-driven architectures shift costs from fixed to variable. In a monolithic architecture running on compute instances, a startup pays for capacity 24/7 regardless of document volume. In an event-driven architecture using AWS Lambda, the startup pays only for actual compute usage based on the number of executions, their duration, and memory allocated. For workloads with variable traffic, processing 50 documents at 2am and 500 documents at 2pm, this can reduce infrastructure costs significantly.
Resilience improves through failure isolation. In a monolithic pipeline, a bug in the validation logic can crash the entire process, blocking extraction and enrichment. But in an event-driven pipeline, a validation failure affects only the validation stage. Extraction continues processing new documents, and enrichment continues processing validated documents. Failed events can be routed to dead-letter queues for later analysis, and the team can deploy a fix to the validation component without restarting the entire pipeline.
Deployment velocity increases because each component can be deployed independently. The team can update the Bedrock enrichment logic, perhaps switching from Claude Sonnet to Claude Opus for higher accuracy, without touching the extraction or validation code. This reduces deployment risk and allows the team to iterate faster. For startups where time-to-market is a competitive advantage, this matters.
Getting started
The transition from monolithic to event-driven architecture doesn't require rewriting the entire application. Start by decoupling a single asynchronous workflow, such as document extraction, from the rest of the pipeline. Configure S3 to publish events to EventBridge when documents are uploaded. Create a Lambda function that subscribes to S3 events and calls Textract. The Lambda function then publishes an extraction.complete event when done. Keep the rest of the pipeline synchronous. Then measure the impact on processing latency and deployment velocity. Key metrics to track include P99 latency, error rate, cost per document, and deployment frequency. If the benefits justify the operational complexity, expand the pattern to validation and enrichment.
AWS provides comprehensive guidance for building event-driven architectures, including reference architectures for IDP and best practices from the AWS Well-Architected Serverless Applications Lens. For startups building AI on AWS, these patterns are not theoretical. They’re proven approaches used by companies scaling from hundreds to millions of users.
Ready to start building event-driven AI applications on AWS? AWS Activate provides credits to offset the cost of Lambda, EventBridge, Bedrock, and the other services covered in this article. Founders in the AWS Activate community also benefit from specialist resources, technical support, business mentorship, and direct connections with the global startup community. Join today and start building production-grade AI on AWS.
How was this content?