Wie war dieser Inhalt?
- Lernen
- Skalierbare KI-Agenten entwickeln – mit ereignisgesteuerten Architekturen die Benutzerzahl auf 10 000 erhöhen
Skalierbare KI-Agenten entwickeln – mit ereignisgesteuerten Architekturen die Benutzerzahl auf 10 000 erhöhen

Die Skalierung von KI-Anwendungen von Hunderten auf Tausende von Benutzern offenbart einen wichtigen architektonischen Wendepunkt. Die synchrone Architektur, die eine schnelle Entwicklung von Prototypen ermöglicht, wird zum Engpass, der das Wachstum behindert. Für Startups, die KI-Anwendungen in AWS entwickeln – sei es zur Analyse von Dokumenten, zur Generierung von Inhalten oder zur Anreicherung von Daten –, kann die Verarbeitung von Workloads pro Anfrage Sekunden oder gar Minuten in Anspruch nehmen. Multipliziert man das mit Hunderten von gleichzeitig aktiven Benutzern, führen synchrone Architekturen dazu, dass Verbindungspools erschöpft werden, Timeout-Schwellenwerte überschritten werden und die Bereitstellung verlangsamt wird.
Im vorliegenden Artikel wird dargelegt, wie sich die KI-gestützte Dokumentenverarbeitung mithilfe ereignisgesteuerter Architekturen in AWS von 100 auf 10 000 Benutzer skalieren lässt. Dabei dient die intelligente Dokumentenverarbeitung (IDP) durchgehend als Hauptbeispiel. Die betreffenden Muster gelten jedoch für alle KI-Workloads, die eine mehrstufige Verarbeitung erfordern.
Wann monolithische Lösungen funktionieren (und wann nicht)
Bei einigen hundert Benutzern ist eine monolithische Pipeline zur Dokumentenverarbeitung oft die richtige Wahl. Eine einzelne Rechen-Instance empfängt hochgeladene Dokumente über eine API, ruft Amazon Textract auf (einen Machine-Learning-Service, der automatisch Text, Handschrift und Daten aus gescannten Dokumenten extrahiert), um strukturierte Daten zu extrahieren. Anschließend validiert sie die Ergebnisse anhand von Geschäftsregeln, reichert die Daten mit zusätzlichem Kontext an und schreibt die endgültige Ausgabe in eine Datenbank. Der gesamte Workflow wird synchron in einem einzigen Anfrage-Antwort-Zyklus ausgeführt. Für ein junges Startup bietet diese Architektur wesentliche Vorteile: Sie ist konzeptionell einfach, leicht zu debuggen und erfordert nur einen minimalen betrieblichen Aufwand.
Diese Architektur basiert jedoch auf Annahmen, die bei größeren Umfängen zum Nachteil werden. Bei der synchronen Verarbeitung wird von drei Annahmen ausgegangen: dass jeder Schritt schnell genug abgeschlossen wird, um eine HTTP-Verbindung offen zu halten; dass eine Zunahme der hochgeladenen Dokumente den Validierungsschritt, der unter Umständen rechenintensiv ist, nicht überlastet; und dass ein Fehler in der Anreicherungsphase keine komplette Neuverarbeitung des gesamten Dokuments erfordert. Diese Annahmen gelten bei einigen hundert Benutzern. Bei größeren Zahlen treten jedoch erste Probleme auf.
Die Bruchstelle
Bei 1 000 Benutzern zeigen sich die ersten Risse. Die Extraktion durch Textract, die pro Dokument 2 bis 3 Sekunden dauern kann, führt in Spitzenzeiten zu einem Rückstau. Der Validierungsschritt, der im selben Prozess ausgeführt wird, lässt sich nicht unabhängig skalieren. Bei langsamer Extraktion wartet die Validierung. und bei langsamer Validierung wartet die Anreicherung. Die gesamte Pipeline wird so langsam wie ihre langsamste Komponente. Verbindungs-Timeouts nehmen zu. Den Benutzern wird per Symbol angezeigt, dass die Verarbeitung läuft, aber das entsprechende Symbol verschwindet nie. Das Technik-Team fügt weitere Instances hinzu, doch das verzögert das Problem nur, statt den architektonischen Engpass zu beheben.
Bei 5 000 Benutzern ist die monolithische Lösung nicht mehr tragbar. Ein einziger Fehler im Anreicherungsschritt hat rückwirkende Folgen und blockiert die Validierung und die Extraktion. Das Team kann keine Aktualisierungen an der Validierungslogik vornehmen, ohne die gesamte Pipeline neu zu starten. Eine von der Validierung unabhängige Skalierung der Extraktion ist unmöglich, da beide Vorgänge in derselben Codebasis gekoppelt sind und im selben Prozess ausgeführt werden. Bei 10 000 Benutzern ist eine andere Herangehensweise erforderlich.
Auf ereignisgesteuerte Architekturen umstellen
Ereignisgesteuerte Architekturen beheben diesen Engpass, indem sie synchrone Aufrufe durch asynchrone Ereignisse ersetzen. Statt dass eine Komponente die nächste direkt aufruft, veröffentlicht jede Komponente nach Abschluss ihrer Arbeit ein Ereignis und abonniert Ereignisse, die signalisieren, wann sie beginnen soll. Die API zum Hochladen von Dokumenten veröffentlicht ein Ereignis, sobald ein Dokument eintrifft. Alle nachfolgenden Komponenten – von der Extraktion über die Validierung bis hin zur Anreicherung – abonnieren jeweils das vorherige Ereignis, führen ihre Aufgabe aus und veröffentlichen das nächste Ereignis.
Durch dieses Muster wird eine Vermittlungsschicht eingeführt: ein Event Bus wie Amazon EventBridge (ein Serverless-Service, der Anwendungen mithilfe von Ereignissen miteinander verbindet), der zwischen Produzenten und Konsumenten sitzt. Produzenten und Konsumenten haben keine direkte Kenntnis voneinander. Diese Entkopplung ist der architektonische Wandel, der eine unabhängige Skalierung, die Isolierung von Fehlern und eine schnelle Bereitstellung ermöglicht.
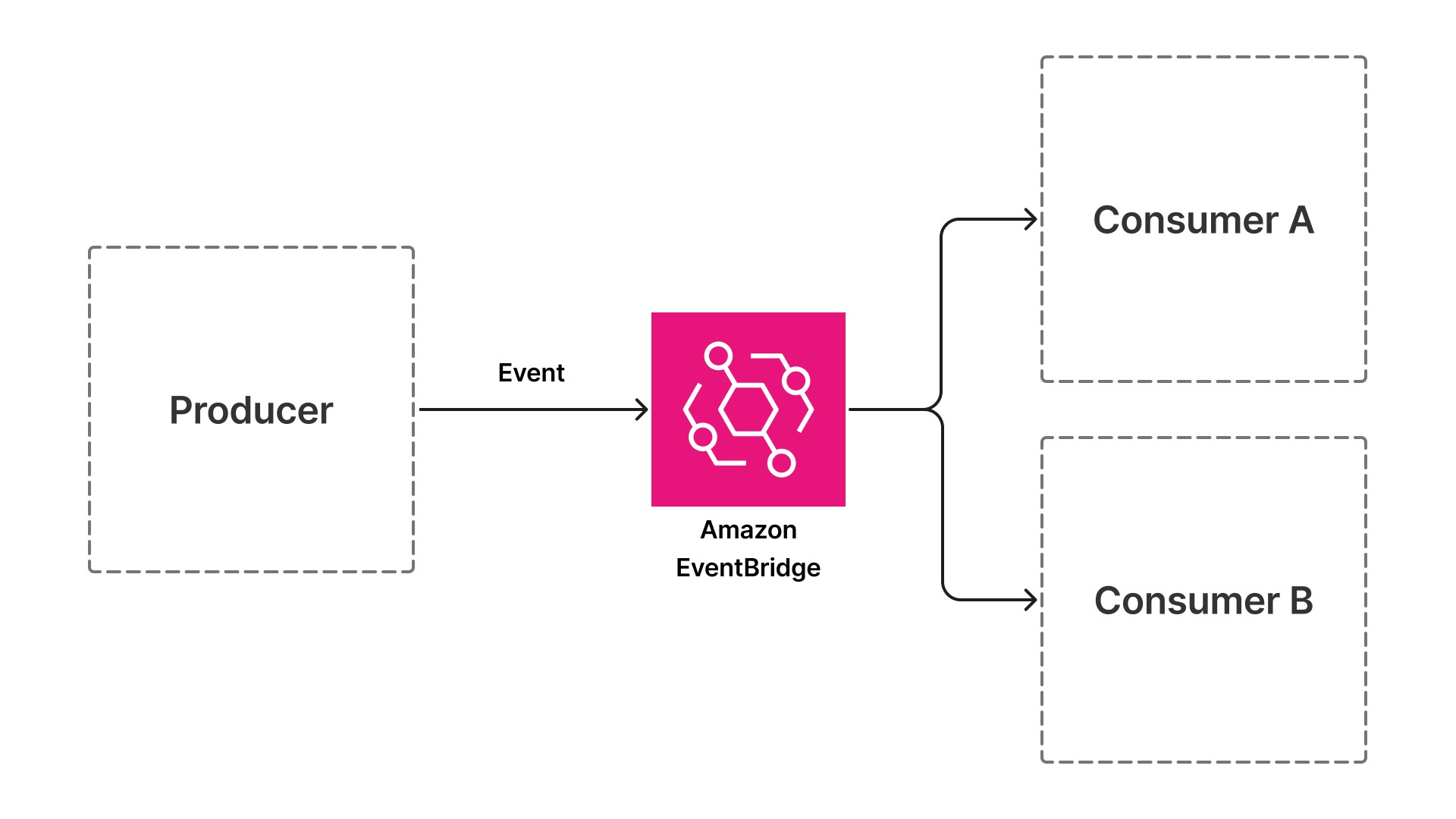
Warum das für KI-Workloads so wichtig ist
KI-Workloads profitieren in besonderem Maße von diesem Muster. Die Extraktion durch Textract kann bei einer einfachen Rechnung 2 Sekunden und bei einem komplexen Vertrag 30 Sekunden dauern. Die Anreicherung mit Amazon Bedrock kann bei der Klassifizierung 1 Sekunde und bei der Extraktion von Entitäten mit einem großen Sprachmodell 10 Sekunden in Anspruch nehmen. In einer synchronen Architektur führen diese variablen Verarbeitungszeiten zu einer unvorhersehbaren Latenz. In einer ereignisgesteuerten Architektur wird jeder Schritt im eigenen Tempo verarbeitet und nach dessen Abschluss werden entsprechende Ereignisse veröffentlicht. Der Durchsatz der Pipeline richtet sich nicht nach der langsamsten Komponente, sondern wird durch das unabhängige Skalierungsverhalten jeder einzelnen Phase bestimmt. Bei KI-Workloads mit stark schwankender Auslastung bedeutet das auch, dass Sie nur für die tatsächlich genutzte Rechenleistung bezahlen, anstatt Kapazitäten für Spitzenauslastungen vorhalten zu müssen.
Wann die Umstellung vollzogen werden sollte
Dieses Muster wird dann zu einem entscheidenden Faktor, wenn ein Startup einen bestimmten Wendepunkt erreicht: nämlich dann, wenn die Kosten synchroner Engpässe (verlorene Kundinnen und Kunden, Zeit für die technische Behebung akuter Probleme, Unfähigkeit, Updates sicher bereitzustellen) die Kosten für die Bewältigung asynchroner Komplexität übersteigen. Diese Punkt ist dann erreicht, wenn Sie folgende Anzeichen bemerken:
- In den Protokollen werden zu Spitzenzeiten Fehler wegen Verbindungs-Timeouts aufgeführt.
- Eine einzige Bereitstellung erfordert die Koordination von Änderungen in mehreren Teams.
- Einzelne Verarbeitungsschritte lassen sich nicht unabhängig voneinander skalieren.
- Bei einer fehlgeschlagenen Verarbeitung müssen ganze Dokumente komplett neu verarbeitet werden.
- Die Fehlerrate steigt proportional zum Datenverkehr.
Für junge Startups mit weniger als 500 Benutzern kommen ereignisgesteuerte Architekturen meist noch nicht in Frage, da der betriebliche Aufwand die Vorteile überwiegt. Für Startups, die von 1 000 auf 10 000 Benutzer skalieren, ist die Umstellung dagegen ein unverzichtbarer Schritt.
Die ereignisgesteuerte Dokumentenverarbeitung in der Praxis
Sehen wir uns an, wie sich dieses Muster auf die intelligente Dokumentenverarbeitung anwenden lässt. Ein Fintech-Startup, das eine Plattform zur Vertragsanalyse für den Legal-Tech-Bereich entwickelt, erhält täglich Hunderte von Verträgen: Geheimhaltungsvereinbarungen, Arbeitsverträge und Lieferantenverträge. Jedes Dokument durchläuft einen mehrstufigen Workflow: Hochladen, Extrahieren, Validieren, Anreichern und Speichern. In einer ereignisgesteuerten Architektur stellt jeder Schritt eine unabhängige, durch Ereignisse ausgelöste Komponente dar.
Der Workflow beginnt, wenn eine Benutzerin einen Vertrag in einen Bucket von Amazon Simple Storage Service (S3) hochlädt. S3 übermittelt ein Ereignis (Objekt erstellt) an den EventBridge-Standardbus. Eine Komponente, die dieses Ereignis abonniert hat, ruft das Dokument ab und ruft Textract auf, um Text, Tabellen und Schlüssel-Wert-Paare zu extrahieren. Textract verarbeitet das Dokument asynchron (wichtig bei großen PDF-Dateien, deren Verarbeitung 20 bis 30 Sekunden dauern kann). Nach Abschluss der Extraktion veröffentlicht die Komponente ein extraction.complete-Ereignis mit den extrahierten Daten.
Eine zweite Komponente, die das Ereignis extraction.complete abonniert hat, validiert die extrahierten Daten anhand von Geschäftsregeln. Enthält der Vertrag die erforderlichen Klauseln? Sind die Datumsangaben richtig formatiert? Ist der Name der Gegenpartei vorhanden? Bei erfolgreicher Validierung veröffentlicht die Komponente ein validation.passed-Ereignis. Schlägt die Validierung fehl, veröffentlicht sie ein validation.failed-Ereignis und leitet das Dokument an eine Warteschlange für die manuelle Überprüfung weiter (eine Amazon-SQS-Warteschlange, die von einem Mitarbeitenden im Rahmen eines Human-in-the-Loop-Workflows überprüft wird).
Eine dritte Komponente, die das Ereignis validation.passed abonniert hat, reichert die Vertragsdaten mithilfe von Bedrock an. Sie kann beispielsweise die Vertragsart klassifizieren (Geheimhaltungsvereinbarung, Arbeitsvertrag, Lieferantenvertrag), Entitäten extrahieren (Firmennamen, Datumsangaben, Geldbeträge) oder Schlüsselbegriffe mithilfe eines großen Sprachmodells wie Claude von Anthropic zusammenfassen. Dank der Serverless-Inferenz von Bedrock muss die Komponente keine GPU-Infrastruktur verwalten, sondern ruft einfach die Bedrock-API auf und erhält eine strukturierte Ausgabe. Nach Abschluss der Anreicherung veröffentlicht die Komponente ein enrichment.finished-Ereignis und schreibt die endgültigen strukturierten Daten in Amazon DynamoDB (eine Serverless-NoSQL-Datenbank, die bei jeder Größenordnung eine Latenz im Millisekundenbereich aufweist).
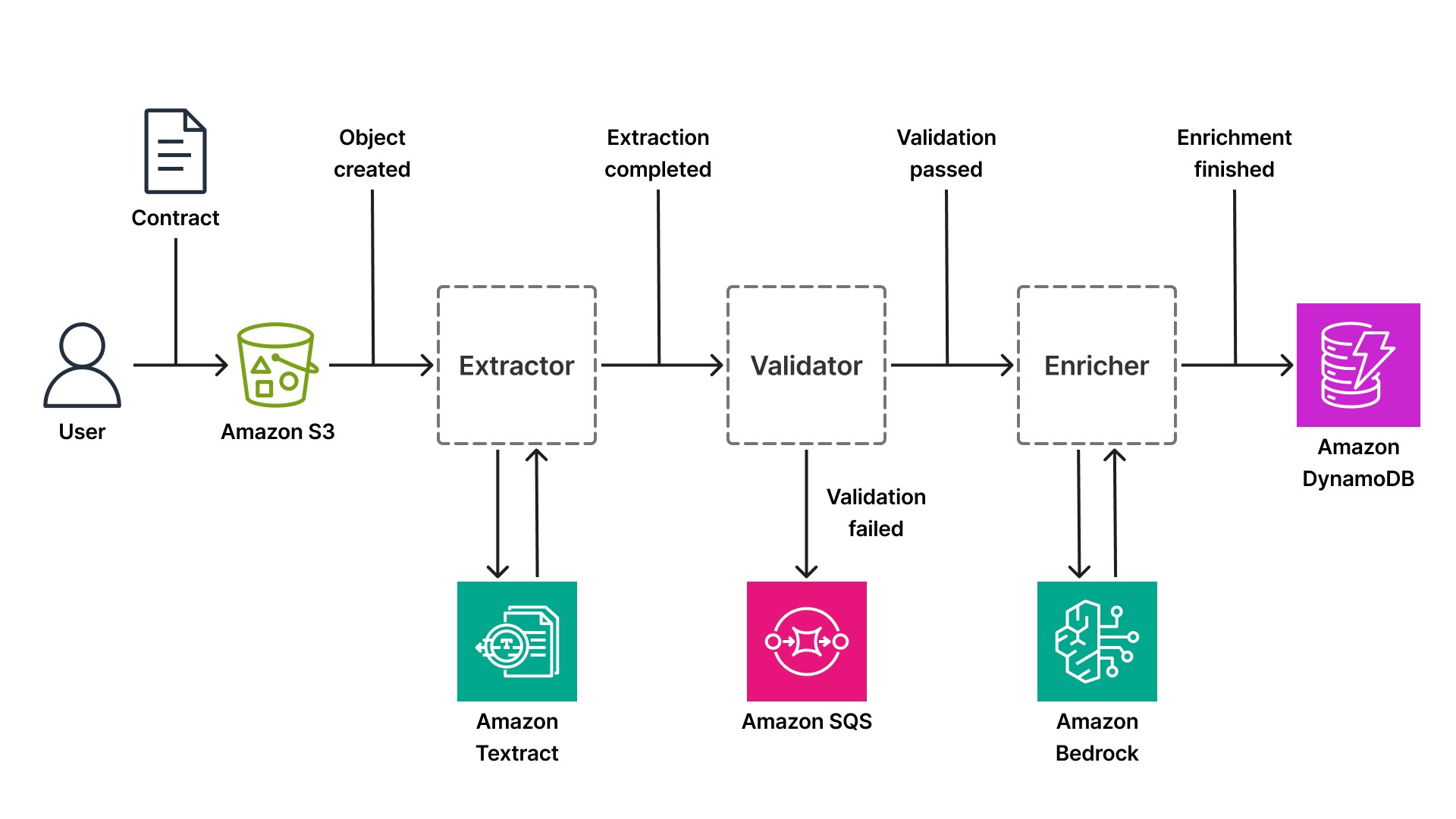
Das ereignisgesteuerte Muster bleibt unabhängig davon, ob die Pipeline Verträge, Krankenakten oder Finanzberichte verarbeitet, immer gleich. Lediglich der KI-Service ändert sich bei den einzelnen Schritten. Eine Pipeline für Krankenakten könnte zur Extraktion von Entitäten zum Beispiel Amazon Comprehend Medical anstelle von Bedrock nutzen. Bei einer Pipeline für Finanzberichte könnte die spezialisierte AnalyzeExpense-API von Textract zum Einsatz kommen. Das architektonische Prinzip bleibt dabei unverändert: Jeder Schritt veröffentlicht Ereignisse, skaliert unabhängig und kann bereitgestellt werden, ohne andere Phasen zu beeinträchtigen.
Für die Entwickler dieser Pipelines hat AWS MCP-Server (Model Context Protocol) herausgebracht, die sich in KI-Codierungsassistenten integrieren lassen. Der Serverless-MCP-Server von AWS bietet das entsprechende Fachwissen, um die Entwicklung von Serverless-Anwendungen direkt in der Codierungsumgebung zu optimieren. Dadurch wird der Zeitaufwand für die Suche in der Dokumentation verringert.
Der Business Case für die Entkopplung
Die geschäftlichen Konsequenzen dieser Architektur gehen über die technische Eleganz hinaus. Bei ereignisgesteuerten Architekturen sind die Kosten nicht mehr fix, sondern variabel. Bei einer monolithischen Architektur, die auf Rechen-Instances ausgeführt wird, zahlt ein Startup unabhängig vom Dokumentenvolumen rund um die Uhr für Kapazität. Bei einer ereignisgesteuerten Architektur mit AWS Lambda zahlt das Startup nur für die tatsächlich genutzte Rechenleistung, und zwar auf Grundlage der Anzahl der Ausführungen, ihrer Dauer und des zugewiesenen Speichers. Dadurch können die Infrastrukturkosten bei Workloads mit schwankendem Datenverkehr (zum Beispiel 50 verarbeitete Dokumente um 2 Uhr und 500 Dokumente um 14 Uhr) erheblich gesenkt werden.
Die Widerstandsfähigkeit wird durch die Isolierung von Fehlern verbessert. In einer monolithischen Pipeline kann ein Fehler in der Validierungslogik den gesamten Prozess zum Absturz bringen und die Extraktion und Anreicherung blockieren. In einer ereignisgesteuerten Pipeline hingegen wirkt sich ein Validierungsfehler nur auf die Validierungsphase aus. Die Extraktion verarbeitet weiterhin neue Dokumente und die Anreicherung setzt die Verarbeitung validierter Dokumente fort. Fehlgeschlagene Ereignisse können zur späteren Analyse an Warteschlangen für unzustellbare Nachrichten weitergeleitet werden. Das Team kann eine Korrektur für die Validierungskomponente bereitstellen, ohne die gesamte Pipeline neu starten zu müssen.
Das Bereitstellungstempo steigt, da sich die einzelnen Komponenten unabhängig voneinander bereitstellen lassen. Das Team kann die Bedrock-Anreicherungslogik aktualisieren und zur Erzielung einer höheren Genauigkeit beispielsweise von Claude Sonnet zu Claude Opus wechseln – ohne dabei den Extraktions- oder Validierungscode ändern zu müssen. Das verringert das Bereitstellungsrisiko und ermöglicht es dem Team, schneller zu iterieren. Für Startups, denen eine schnelle Markteinführung einen Wettbewerbsvorteil bringt, ist das von großer Bedeutung.
Erste Schritte
Die Umstellung von einer monolithischen auf eine ereignisgesteuerte Architektur erfordert keine Neuprogrammierung der gesamten Anwendung.Entkoppeln Sie zunächst einen einzelnen asynchronen Workflow, z. B. die Dokumentenextraktion, vom Rest der Pipeline. Konfigurieren Sie S3 so, dass beim Hochladen von Dokumenten Ereignisse an EventBridge übermittelt werden. Erstellen Sie eine Lambda-Funktion, die S3-Ereignisse abonniert und Textract aufruft. Die Lambda-Funktion veröffentlicht anschließend ein extraction.complete-Ereignis, sobald die Extraktion abgeschlossen ist. Halten Sie den Rest der Pipeline synchron. Messen Sie danach die Auswirkungen auf die Verarbeitungslatenz und das Bereitstellungstempo. Zu den wichtigsten zu verfolgenden Metriken gehören die P99-Latenz, die Fehlerquote, die Kosten pro Dokument und die Bereitstellungshäufigkeit. Wenn die Vorteile den betrieblichen Mehraufwand rechtfertigen, sollten Sie das Muster auch für die Validierung und Anreicherung nutzen.
AWS bietet umfassende Hilfestellung für die Entwicklung ereignisgesteuerter Architekturen, darunter Referenzarchitekturen für die intelligente Dokumentenverarbeitung und bewährte Vorgehensweisen aus dem AWS-Well-Architected-Fokusbereich für Serverless-Anwendungen. Für Startups, die KI-Lösungen in AWS entwickeln, sind diese Muster keine bloße Theorie. Vielmehr handelt es sich um bewährte Herangehensweisen, mit deren Hilfe Unternehmen von mehreren Hundert auf Millionen von Benutzern skalieren.
Sind Sie bereit, mit der Entwicklung ereignisgesteuerter KI-Anwendungen in AWS zu beginnen? AWS Activate stellt Guthaben bereit, um die Kosten für Lambda, EventBridge, Bedrock und die anderen in diesem Artikel behandelten Service zu kompensieren. Gründerinnen und Gründer aus der AWS-Activate-Community profitieren außerdem von Fachressourcen, technischem Support, geschäftlicher Beratung und direkten Verbindungen zur weltweiten Startup-Community. Melden Sie sich noch heute an und beginnen Sie mit der Entwicklung von produktionsreifer KI in AWS.
Wie war dieser Inhalt?