このコンテンツはいかがでしたか?
- 学ぶ
- スケールする AI エージェントを構築: イベントドリブンアーキテクチャを使用して 1 万人のユーザーに拡大
スケールする AI エージェントを構築: イベントドリブンアーキテクチャを使用して 1 万人のユーザーに拡大

AI アプリケーションを数百人から数千人のユーザーにスケールする際には、アーキテクチャ上の重要な転換点が明らかになります。迅速なプロトタイピングを可能にする同期アーキテクチャが、成長を阻害するボトルネックとなるのです。AWS 上で AI アプリケーションを構築するスタートアップにとって、ドキュメント分析、コンテンツ生成、データエンリッチメントなど、ワークロードの処理には、リクエストごとに数秒から数分かかる場合があります。これが数百人の同時ユーザーによって実行されると、同期アーキテクチャでは接続プールが枯渇し、タイムアウトしきい値を超え、デプロイ速度が阻害されます。
この記事では、AWS 上でイベントドリブンアーキテクチャを使用して、AI ドキュメント処理を 100 人のユーザーから 1 万人のユーザーまでスケールする方法について概説します。インテリジェントドキュメント処理 (IDP) を主な例として本書全体を通じて取り上げますが、これらのパターンは、複数ステップの処理を必要とするあらゆる AI ワークロードに適用できます。
モノリスが適切である場合 (および適切でない場合)
数百人のユーザー規模では、モノリシックなドキュメント処理パイプラインが適切な選択肢であることがよくあります。単一のコンピューティングインスタンスが API 経由でドキュメントアップロードを受け取り、Amazon Textract (スキャンされたドキュメントから、テキスト、手書き文字、データを自動的に抽出する機械学習サービス) を呼び出して構造化データを抽出し、ビジネスルールに照らして結果を検証するとともに、追加のコンテキストでデータをエンリッチ化して、最終出力をデータベースに書き込みます。ワークフロー全体は、単一のリクエスト/応答サイクル内で同期的に実行されます。アーリーステージのスタートアップにとって、このアーキテクチャには大きな利点があります。その利点とは、概念的にシンプルで、デバッグが容易であり、運用上のオーバーヘッドも最小限で済むということです。
しかし、このアーキテクチャには、規模が大きくなると問題となる前提があります。同期処理は、各ステップが HTTP 接続を維持できる程度に十分な速さで完了することを前提としています。また、ドキュメントアップロードの急増が、CPU 負荷が高くなる可能性のある検証ステップを過負荷にしないことを前提としています。さらに、エンリッチメントステージでの失敗が、ドキュメント全体を最初から再処理する必要性を生じさせないことを前提としています。これらの前提は、数百ユーザーの規模では成り立ちますが、規模が大きくなると破綻し始めます。
限界点
ユーザーが 1,000 人に達すると、最初の亀裂が生じます。ドキュメントあたり 2~3 秒かかる場合がある Textract 抽出は、ピーク時にバックログの作成を開始します。同じプロセスで実行される検証ステップは、独立してスケールできません。抽出が遅いと検証が待機し、検証が遅いとエンリッチメントが待機します。パイプライン全体の処理速度は、最も遅いコンポーネントの速度に左右されます。接続タイムアウトが増加します。ユーザーはいつまでも消えない「処理中」の表示を見続けることになります。エンジニアリングチームはインスタンスをさらに追加しますが、これはアーキテクチャ上のボトルネックを解消するのではなく、問題を先送りするだけです。
ユーザー数が 5,000 人に達すると、モノリスは維持不能になります。エンリッチメントステップでの単一の障害が連鎖的に影響を及ぼし、検証と抽出をブロックします。チームは、パイプライン全体を再起動せずに検証ロジックの更新をデプロイできません。抽出と検証は同じコードベースで結合され、同じプロセスで実行されているため、検証とは独立して抽出をスケールすることは不可能です。ユーザー数が 10,000 人に達すると、別のアプローチが必要になります。
イベントドリブンアーキテクチャへの移行
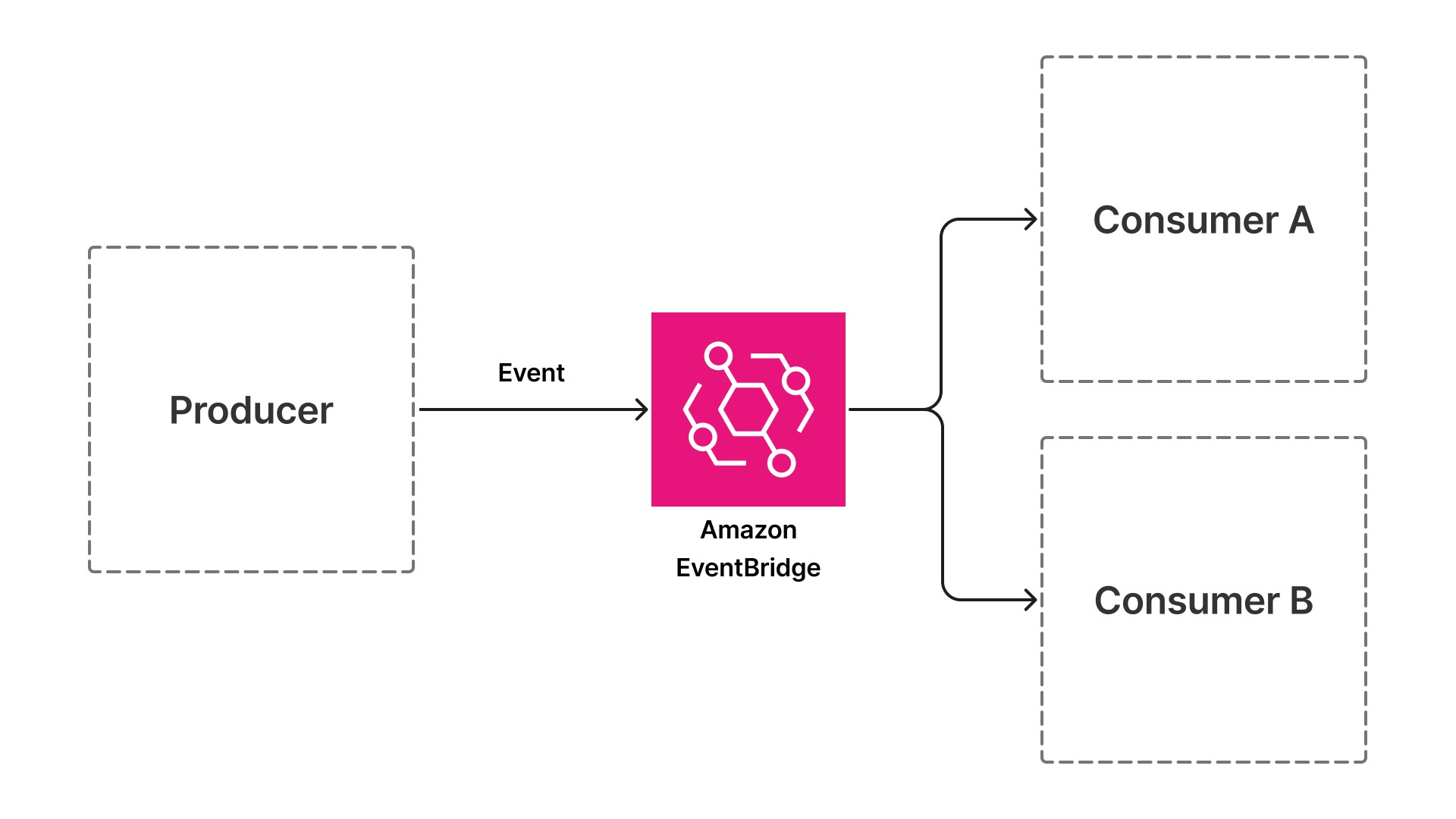
イベントドリブンアーキテクチャは、同期呼び出しを非同期イベントに置き換えることで、この制約を解消します。あるコンポーネントが次のコンポーネントを直接呼び出すのではなく、各コンポーネントは、処理が完了したときにイベントを発行し、処理を開始すべきタイミングを示すイベントをサブスクライブします。ドキュメントアップロード API は、ドキュメントが到達したときにイベントを発行します。ドキュメントアップロード API は、ドキュメントが到達するとイベントを発行します。抽出から検証、エンリッチメントに至るまで、後続の各コンポーネントは前のイベントをサブスクライブし、処理を実行して次のイベントを発行します。
このパターンでは、プロデューサーとコンシューマーの間に、間接レイヤー、すなわち、Amazon EventBridge (イベントを使用してアプリケーションを接続するサーバーレスサービス) などのイベントバスが導入されます。プロデューサーとコンシューマーは相互の直接的な知識を持ちません。このデカップリングこそが、独立したスケーリング、障害分離、迅速なデプロイを可能にするアーキテクチャ上の転換点です。
AI ワークロードにとってこれが重要な理由
AI ワークロードは、このパターンから特に大きなメリットを得られます。Textract による抽出では、単純な請求書で 2 秒、複雑な契約書で 30 秒かかる場合があります。大規模言語モデル (LLM) を使用した Amazon Bedrock エンリッチメントでは、分類に 1 秒、エンティティ抽出に 10 秒かかる場合があります。同期アーキテクチャでは、これらの処理時間のばらつきが予測不能なレイテンシーを引き起こします。イベントドリブンアーキテクチャでは、各ステップが独自のペースで処理し、完了時にイベントを発行します。パイプラインのスループットは、最も低速なコンポーネントに制約されるのではなく、各ステージの独立したスケーリング動作によって決まります。また、負荷の変動が激しい AI ワークロードの場合、これは、ピーク時のキャパシティに合わせてプロビジョニングするのではなく、実際に使用した分の料金のみを支払えばよいことを意味します。
移行のタイミング
このパターンは、スタートアップがある特定の転換点に達したときに不可欠となります。その転換点とは、同期処理のボトルネックによるコスト (顧客の喪失、トラブル対応に費やされるエンジニアリング作業にかかる時間、アップデートを安全にデプロイできないことなど) が、非同期処理の複雑さを管理するコストを上回る時点です。次の兆候を目にするようになったら、この時点に達したと言えます:
- ピーク時において、ログに接続タイムアウトエラーが表示される
- 単一のデプロイを行うために、複数のチーム間での変更の調整が必要になる
- 個々の処理ステップを独立してスケールできない
- 処理に失敗すると、ドキュメント全体を最初から再処理する必要がある
- トラフィックの増加に比例してエラー率が上昇する
ユーザー数が 500 人未満であるアーリーステージのスタートアップにとって、イベントドリブンアーキテクチャは時期尚早であることが多いでしょう。なぜなら、運用上のオーバーヘッドがメリットを上回ってしまうからです。1,000 人のユーザーから 10,000 人のユーザーにスケールする段階にあるスタートアップにとっては、必要な移行と言えます。
イベントドリブンドキュメント処理の実践
このパターンが IDP にどのように適用されるのかを考えてみましょう。リーガルテック分野で契約書分析プラットフォームを構築しているフィンテックスタートアップは、NDA、雇用契約、ベンダー契約といった数百の契約書を日々受け取っています。各ドキュメントは、アップロード、抽出、検証、エンリッチメント、保存というマルチステップワークフローを経ます。イベントドリブンアーキテクチャでは、各ステップは、イベントによってトリガーされる独立したコンポーネントとなります。
ワークフローは、ユーザーが契約書を Amazon Simple Storage Service (S3) バケットにアップロードしたときに開始されます。S3 は、イベント (Object Created) を EventBridge のデフォルトバスに発行します。このイベントをサブスクライブしているコンポーネントがドキュメントを取得し、Textract を呼び出して、テキスト、テーブル、key-value ペアを抽出します。Textract はドキュメントを非同期で処理します (これは、処理に 20~30 秒かかる可能性のある大きな PDF ファイルにとって重要です)。抽出が完了すると、コンポーネントは、抽出されたデータを含む extraction.complete イベントを発行します。
extraction.complete イベントをサブスクライブしている 2 番目のコンポーネントは、抽出されたデータをビジネスルールに照らして検証します。契約書に必須の条項が含まれているか、日付の形式が正しいか、取引相手の名称が記載されているか、といった点を確認します。検証に合格した場合、コンポーネントは validation.passed イベントを発行します。検証に失敗した場合は validation.failed イベントを発行し、ドキュメントを手動レビュー用のキュー (Human-in-the-Loop ワークフローで使用される Amazon SQS キュー) にルーティングします。
validation.passed をサブスクライブしている 3 番目のコンポーネントは、Bedrock を使用して契約データをエンリッチ化します。例えば、Anthropic の Claude などの大規模言語モデルを使用して、契約タイプ (NDA、雇用契約、ベンダー契約) の分類、エンティティ (企業名、日付、金額) の抽出、主要な条件の要約を行います。Bedrock のサーバーレス推論機能により、コンポーネントは GPU インフラストラクチャを管理する必要はなく、単に Bedrock API を呼び出して構造化された出力を受け取るだけで済みます。エンリッチメントが完了すると、コンポーネントは enrichment.finished イベントを発行し、最終的な構造化データを Amazon DynamoDB (あらゆる規模でミリ秒のレイテンシーを実現するサーバーレス NoSQL データベース) に書き込みます。
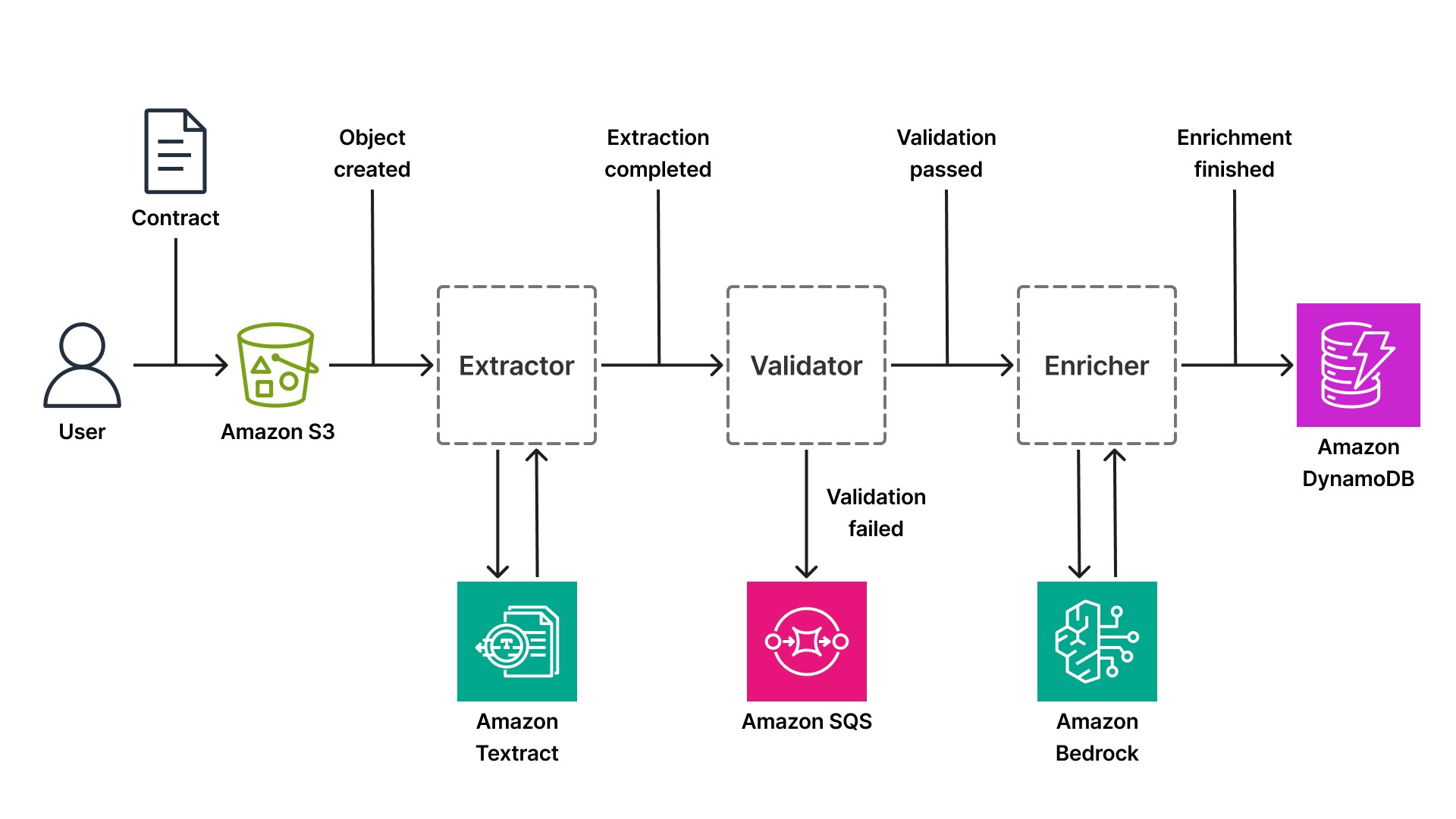
パイプラインの処理対象が契約書、医療記録、財務諸表のいずれであっても、イベントドリブンのパターンは変わりません。各ステップで使用される AI サービスのみが異なります。医療記録パイプラインでは、Bedrock の代わりに Amazon Comprehend Medical を使用してエンティティを抽出する場合があります。財務諸表パイプラインでは、Textract の特化型 AnalyzeExpense API を使用する場合があります。ここでのアーキテクチャの原則は一貫しています。すなわち、各ステップはイベントを発行し、独立してスケールして、他のステージに影響を及ぼすことなくデプロイできるということです。
これらのパイプラインを構築するデベロッパー向けに、AWS は AI コーディングアシスタントと統合するモデルコンテキストプロトコル (MCP) サーバーをリリースしました。AWS Serverless MCP Server は、デベロッパーがコーディング環境内で直接サーバーレスアプリケーションを構築する方法を効率化し、ドキュメントの検索に費やす時間を短縮するための専門知識を提供します。
デカップリングのビジネス上のメリット
このアーキテクチャのビジネス上の影響は、技術的な洗練度にとどまりません。イベントドリブンアーキテクチャは、コストを固定費から変動費に移行させます。コンピューティングインスタンス上で実行されるモノリシックアーキテクチャでは、スタートアップは、ドキュメント量にかかわらず、24 時間年中無休で発生するキャパシティ料金を支払うことになります。AWS Lambda を使用するイベントドリブンアーキテクチャでは、スタートアップは、実行回数、実行時間、割り当てられたメモリに基づいて、実際のコンピューティング使用量についての料金のみを支払うことで済みます。これにより、トラフィックが変動するワークロード (例えば午前 2 時に 50 件のドキュメントを処理し、午後 2 時に 500 件のドキュメントを処理する場合) では、インフラストラクチャコストを大幅に削減できる場合があります。
障害分離により回復力が高まります。モノリシックパイプラインでは、検証ロジックのバグによってプロセス全体がクラッシュし、抽出とエンリッチメントがブロックされる可能性があります。しかし、イベントドリブンパイプラインでは、検証の失敗は検証ステージのみに影響します。抽出は新規ドキュメントの処理を継続し、エンリッチメントは検証済みドキュメントの処理を継続します。失敗したイベントは、後で分析するためにデッドレターキューにルーティングでき、チームはパイプライン全体を再起動することなく、検証コンポーネントに修正をデプロイできます。
各コンポーネントを独立してデプロイできるため、デプロイ速度が向上します。チームは、抽出や検証コードに手を加えることなく、Bedrock エンリッチメントロジックを更新し、例えば精度を高めるために Claude Sonnet から Claude Opus に切り替えることができます。これにより、デプロイのリスクが軽減され、チームはより迅速にイテレーションできます。市場投入までの時間が競争優位性となるスタートアップにとって、これは重要です。
開始方法
モノリシックアーキテクチャからイベントドリブンアーキテクチャへの移行のために、アプリケーション全体を書き直す必要はありません。まず、ドキュメント抽出などの単一の非同期ワークフローを、パイプラインの他の部分からデカップリングすることから始めます。ドキュメントがアップロードされたときに S3 が EventBridge にイベントを発行するように設定します。S3 イベントをサブスクライブして Textract を呼び出す Lambda 関数を作成します。Lambda 関数は処理が完了すると extraction.complete イベントを発行します。パイプラインの残りの部分は同期状態を維持します。その後、処理レイテンシーとデプロイ速度への影響を測定します。追跡すべき主要なメトリクスには、P99 レイテンシー、エラー率、ドキュメントあたりのコスト、デプロイ頻度が含まれます。運用上の複雑さに見合うだけのメリットが得られる場合は、パターンを検証とエンリッチメントに拡張してください。
AWS は、イベントドリブンアーキテクチャの構築に関する包括的なガイダンスを提供しています。これには、IDP のリファレンスアーキテクチャや、AWS Well-Architected Serverless Applications Lens のベストプラクティスなどが含まれます。AWS 上で AI を構築するスタートアップにとって、これらのパターンは理論上のものではありません。数百人から数百万人のユーザーにスケールする企業によって用いられている実績のあるアプローチです。
AWS 上でイベントドリブン AI アプリケーションの構築を開始する準備はできていますか? AWS Activate では、Lambda、EventBridge、Bedrock、およびこの記事で取り上げている他のサービスの費用に充当できるクレジットを提供しています。また、AWS Activate コミュニティの創業者は、専門家リソース、テクニカルサポート、ビジネスメンターシップ、グローバルなスタートアップコミュニティとの直接的なつながりから恩恵を受けることもできます。今すぐ参加して、AWS 上で本番グレードの AI を構築しましょう。
このコンテンツはいかがでしたか?