Come ti è sembrato il contenuto?
- Scopri
- Crea agenti IA scalabili: raggiungi 10.000 utenti con architetture basate sugli eventi
Crea agenti IA scalabili: raggiungi 10.000 utenti con architetture basate sugli eventi

Scalare le applicazioni di intelligenza artificiale da centinaia a migliaia di utenti rivela un punto di svolta architetturale critico. L'architettura sincrona che consente una rapida prototipazione diventa il collo di bottiglia che impedisce la crescita. Per le startup che sviluppano applicazioni di intelligenza artificiale su AWS, che si tratti di analizzare documenti, generare contenuti o arricchire dati, l'elaborazione dei carichi di lavoro può richiedere secondi o minuti per richiesta. Moltiplicando questo per centinaia di utenti simultanei, le architetture sincrone esauriscono i pool di connessioni, superano le soglie di timeout e rallentano la velocità di distribuzione.
Questo articolo illustra come scalare l'elaborazione di documenti tramite intelligenza artificiale da 100 a 10.000 utenti utilizzando architetture basate su eventi su AWS. L’elaborazione intelligente dei documenti (IDP) serve da esempio principale, sebbene questi schemi si applichino a qualsiasi carico di lavoro di intelligenza artificiale che richieda un'elaborazione a più fasi.
Quando i monoliti funzionano (e quando no)
Con poche centinaia di utenti, una pipeline monolitica per l'elaborazione dei documenti è spesso la scelta ideale. Una singola istanza di calcolo riceve i documenti caricati tramite un'API, richiama Amazon Textract (un servizio di machine learning che estrae automaticamente testo, scrittura a mano e dati da documenti scansionati) per estrarre dati strutturati, convalida i risultati rispetto alle regole aziendali, arricchisce i dati con contesto aggiuntivo e scrive l'output finale in un database. L'intero flusso di lavoro viene eseguito in modo sincrono all'interno di un singolo ciclo richiesta-risposta. Per una startup in fase iniziale, questa architettura offre vantaggi significativi: è concettualmente semplice, facile da debuggare e richiede un sovraccarico operativo minimo.
Ma questa architettura comporta presupposti che diventano passività su larga scala. L'elaborazione sincrona presuppone che ogni passaggio venga completato abbastanza rapidamente da mantenere aperta una connessione HTTP. Si presuppone che un picco nei caricamenti di documenti non sovrasti la fase di convalida, che potrebbe richiedere un utilizzo intensivo della CPU. Si presuppone che un errore nella fase di arricchimento non richieda la rielaborazione dell'intero documento da zero. Queste ipotesi valgono per poche centinaia di utenti. Su larga scala, iniziano a fratturarsi.
Il punto di rottura
Con 1.000 utenti, iniziano a comparire i primi problemi. L'estrazione di Textract, che potrebbe richiedere 2-3 secondi per documento, inizia a creare un accumulo di richieste durante le ore di punta. La fase di validazione, eseguita nello stesso processo, non può essere scalata in modo indipendente. Se l'estrazione è lenta, la validazione si blocca. Se la validazione è lenta, l'arricchimento si blocca. L'intera pipeline diventa lenta quanto il suo componente più lento. I timeout di connessione aumentano. Gli utenti vedono indicatori di caricamento "in elaborazione" che non si risolvono mai. Il team di ingegneri aggiunge altre istanze, ma questo non fa altro che rimandare il problema, anziché risolverlo a livello architetturale.
Con 5.000 utenti, il monolite diventa insostenibile. Un singolo errore nella fase di arricchimento si propaga a ritroso, bloccando la validazione e l'estrazione. Il team non può implementare aggiornamenti alla logica di validazione senza riavviare l'intera pipeline. Scalare l'estrazione indipendentemente dalla validazione è impossibile, poiché sono interconnesse nella stessa codebase e vengono eseguite nello stesso processo. Con 10.000 utenti, è necessario un approccio diverso.
Passaggio ad architetture basate sugli eventi
Le architetture basate sugli eventi risolvono questo vincolo sostituendo le chiamate sincrone con eventi asincroni. Invece di un componente che invoca direttamente il successivo, ogni componente pubblica un evento quando completa il proprio lavoro e si iscrive agli eventi che segnalano quando deve iniziare. L'API di caricamento dei documenti pubblica un evento quando arriva un documento. L'API di caricamento dei documenti pubblica un evento all'arrivo di un documento. Ogni componente successivo, dall'estrazione alla validazione fino all'arricchimento, si iscrive all'evento precedente, esegue il proprio lavoro e pubblica quello successivo.
Questo schema introduce un livello di indirezione: un bus di eventi come Amazon EventBridge (un servizio serverless che connette le applicazioni tramite eventi) e che si interpone tra produttori e consumatori. Produttori e consumatori non hanno alcuna conoscenza diretta l'uno dell'altro. Questo disaccoppiamento rappresenta il cambiamento architetturale che consente la scalabilità indipendente, l'isolamento dei guasti e la velocità di distribuzione.
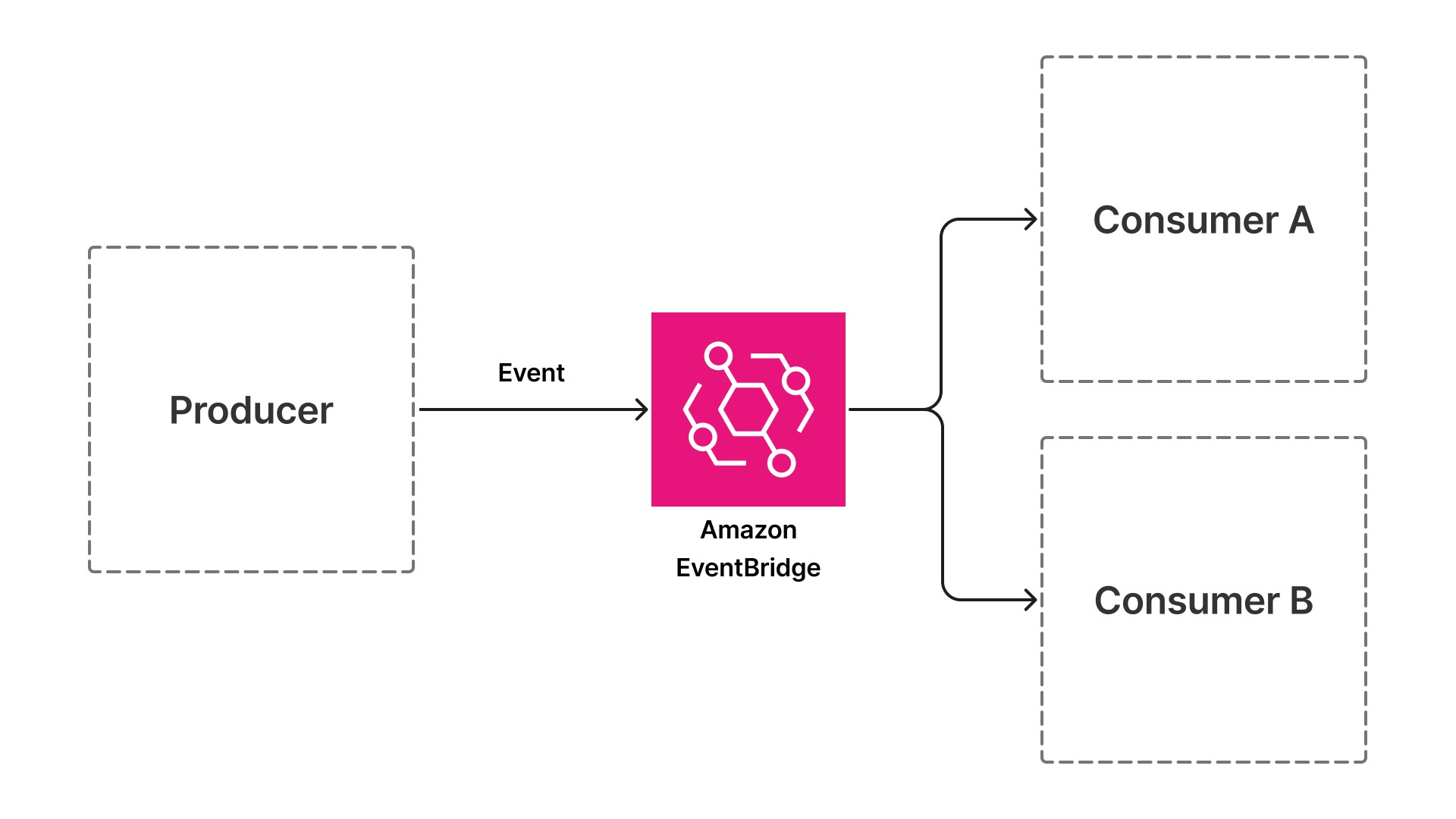
Perché è importante per i carichi di lavoro di intelligenza artificiale
I carichi di lavoro basati sull'intelligenza artificiale traggono particolare vantaggio da questo schema. L'estrazione di un estratto di testo potrebbe richiedere due secondi per una semplice fattura e 30 secondi per un contratto complesso. Con un modello linguistico di grandi dimensioni, l'arricchimento di Amazon Bedrock potrebbe richiedere 1 secondo per la classificazione e 10 secondi per l'estrazione delle entità. In un'architettura sincrona, questi tempi di elaborazione variabili creano una latenza imprevedibile. In un'architettura basata sugli eventi, ogni fase viene elaborata al proprio ritmo, pubblicando eventi al termine dell'elaborazione. Il throughput della pipeline è determinata dal comportamento di scalabilità indipendente di ogni fase, non limitata dal componente più lento. Per i carichi di lavoro di IA con picchi di utilizzo, questo significa anche pagare solo per ciò che si utilizza, anziché prevedere la capacità di picco.
Quando eseguire la transizione
Questo schema diventa essenziale quando una startup raggiunge un punto di svolta specifico: quando il costo dei colli di bottiglia sincroni (clienti persi, tempo di ingegneria speso a risolvere problemi urgenti, incapacità di implementare aggiornamenti in modo sicuro) supera il costo della gestione della complessità asincrona. Avrai raggiunto questo punto quando inizierai a notare questi segnali:
- Nei log compaiono errori di timeout della connessione durante le ore di punta
- Una singola distribuzione richiede il coordinamento delle modifiche tra più team
- Non è possibile scalare le singole fasi di elaborazione in modo indipendente
- L'elaborazione non riuscita richiede la rielaborazione completa dei documenti da zero
- Il tasso di errore aumenta proporzionalmente al traffico
Per le startup in fase iniziale con meno di 500 utenti, le architetture basate sugli eventi sono spesso premature, poiché i costi operativi superano i benefici. Per le startup che crescono da 1.000 a 10.000 utenti, si tratta di una transizione necessaria.
Elaborazione dei documenti basata sugli eventi nella pratica
Consideriamo come questo schema si applichi a IDP. Una startup fintech che sviluppa una piattaforma di analisi contrattuale per il settore legal tech riceve centinaia di contratti al giorno: accordi di riservatezza (NDA), contratti di lavoro, contratti con i fornitori. Ogni documento segue un flusso di lavoro in più fasi: caricamento, estrazione, convalida, arricchimento e archiviazione. In un'architettura basata sugli eventi, ogni fase è un componente indipendente attivato da eventi.
Il flusso di lavoro inizia quando un utente carica un contratto in un bucket Amazon Simple Storage Service (S3). S3 pubblica un evento (Oggetto creato) nel bus predefinito di EventBridge. Un componente iscritto a questo evento recupera il documento e chiama Textract per estrarre testo, tabelle e coppie chiave-valore. Textract elabora il documento in modo asincrono (questo è fondamentale per i PDF di grandi dimensioni che potrebbero richiedere 20-30 secondi per essere elaborati) e quando l'estrazione è completata, il componente pubblica un evento extraction.complete con i dati estratti.
Un secondo componente, iscritto a extraction.complete, convalida i dati estratti rispetto alle regole aziendali. Il contratto include le clausole richieste? Le date sono formattate correttamente? È presente il nome della controparte? Se la convalida ha esito positivo, il componente pubblica un evento validation.passed. Se la convalida non riesce, pubblica un evento validation.failed e indirizza il documento a una coda di revisione manuale (una coda Amazon SQS consumata da un flusso di lavoro con intervento umano).
Un terzo componente, iscritto a validation.passed, Potrebbe classificare il tipo di contratto (NDA, impiego, fornitore), estrarre entità (nomi di aziende, date, importi monetari) o riassumere i termini chiave utilizzando un modello linguistico ampio come Claude di Anthropic. L'inferenza serverless di Bedrock significa che il componente non ha bisogno di gestire l'infrastruttura GPU, chiama semplicemente l'API di Bedrock e riceve un output strutturato. Quando l'arricchimento è completato, il componente pubblica un evento enrichment.finished e scrive i dati strutturati finali inAmazon DynamoDB(un database NoSQL serverless con latenza dell’ordine di millisecondi su qualsiasi scala).
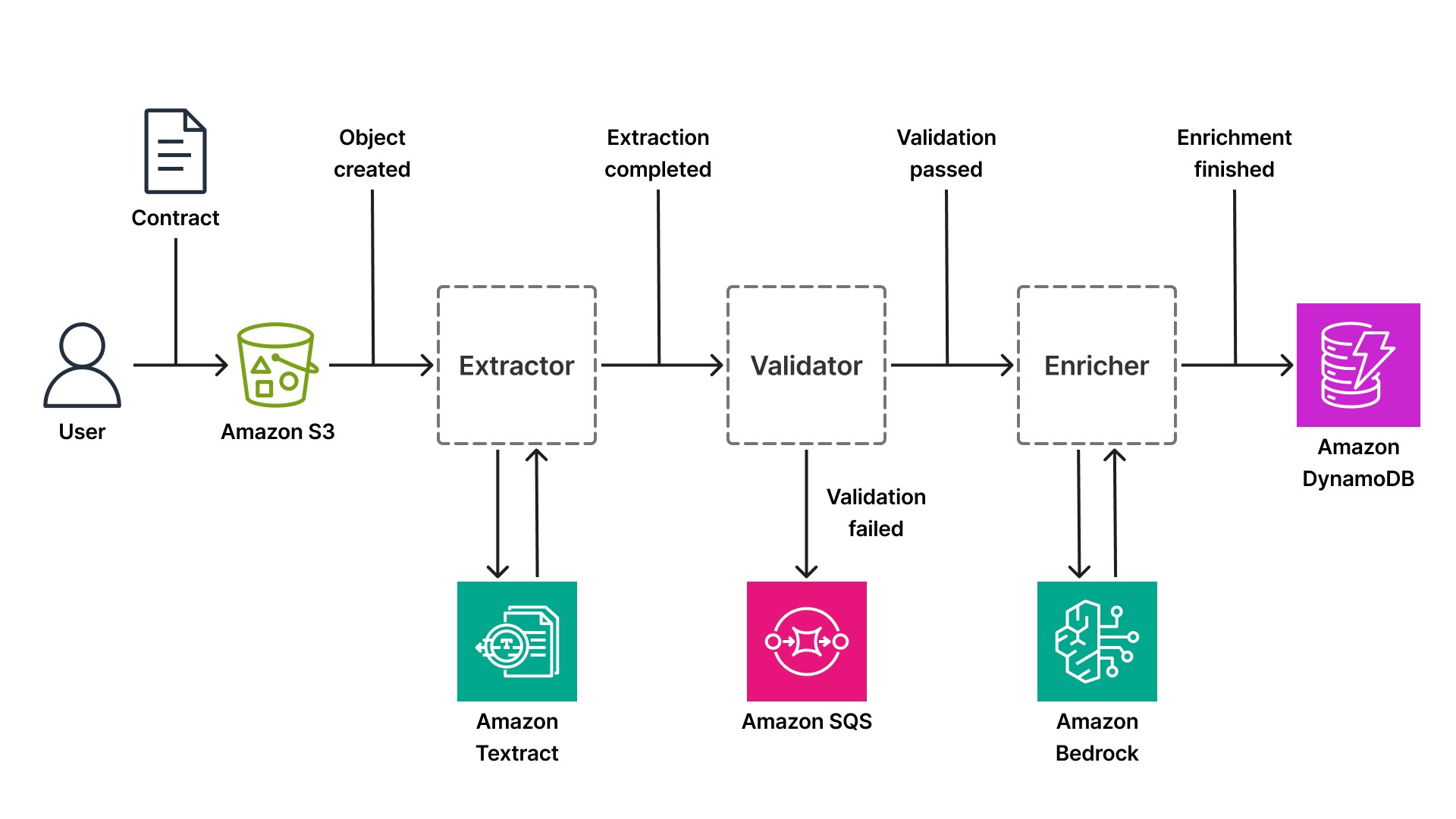
Che la pipeline elabori contratti, cartelle cliniche o bilanci, il modello basato sugli eventi rimane lo stesso. Solo il servizio di intelligenza artificiale in ogni fase cambia. Una pipeline di cartelle cliniche potrebbe utilizzare Amazon Comprehend Medical per l'estrazione di entità invece di Bedrock. Una pipeline di bilancio potrebbe utilizzare l'API specializzata AnalyzeExpense di Textract. Il principio architetturale rimane valido: ogni passaggio pubblica eventi, si adatta in modo indipendente e può essere distribuito senza influenzare le altre fasi.
Per gli sviluppatori che creano queste pipeline, AWS ha rilasciato i server Model Context Protocol (MCP) che si integrano con gli assistenti di codifica IA. Il server MCP serverless di AWS fornisce competenze per semplificare il modo in cui gli sviluppatori creano applicazioni serverless direttamente all'interno dell'ambiente di programmazione, riducendo il tempo dedicato alla ricerca di documentazione.
Il business case del disaccoppiamento
Le conseguenze commerciali di questa architettura vanno oltre l'eleganza tecnica. Le architetture basate sugli eventi spostano i costi da fissi a variabili. In un'architettura monolitica in esecuzione su istanze di calcolo, una startup paga per la capacità 24 ore su 24, 7 giorni su 7, indipendentemente dal volume dei documenti. In un'architettura basata sugli eventi che utilizza AWS Lambda, la startup paga solo per l'effettivo utilizzo delle risorse di calcolo, in base al numero di esecuzioni, alla loro durata e alla memoria allocata. Per carichi di lavoro con traffico variabile, come l'elaborazione di 50 documenti alle 2 del mattino e 500 documenti alle 14, questo può ridurre significativamente i costi dell'infrastruttura.
La resilienza migliora grazie all'isolamento dei guasti. In una pipeline monolitica, un bug nella logica di validazione può mandare in crash l'intero processo, bloccando l'estrazione e l'arricchimento. In una pipeline basata sugli eventi, invece, un errore di validazione influisce solo su questa fase. L'estrazione continua a elaborare i nuovi documenti e l'arricchimento continua a elaborare i documenti validati. Gli eventi non riusciti possono essere instradati alle code DLQ per un'analisi successiva, e il team può implementare una correzione al componente di convalida senza riavviare l'intera pipeline.
La velocità di distribuzione aumenta perché ogni componente può essere distribuito in modo indipendente. Il team può aggiornare la logica di arricchimento di Bedrock, ad esempio passando da Claude Sonnet a Claude Opus per una maggiore precisione, senza dover modificare il codice di estrazione o validazione. Ciò riduce il rischio di distribuzione e consente al team di iterare più rapidamente. Per le startup, dove il time-to-market rappresenta un vantaggio competitivo, questo aspetto è fondamentale.
Nozioni di base
La transizione dall'architettura monolitica a quella basata sugli eventi non richiede la riscrittura dell'intera applicazione. Inizia separando un singolo flusso di lavoro asincrono, come l'estrazione di documenti, dal resto della pipeline. Configura S3 in modo da pubblicare gli eventi su EventBridge quando vengono caricati i documenti. Crea una funzione Lambda che si iscrive agli eventi S3 e chiama Textract. La funzione Lambda pubblica quindi un evento extraction.complete una volta terminato. Mantieni sincronizzato il resto della pipeline. Successivamente, misura l'impatto sulla latenza di elaborazione e sulla velocità di distribuzione. Le metriche chiave da monitorare includono la latenza P99, il tasso di errore, il costo per documento e la frequenza di distribuzione. Se i benefici giustificano la complessità operativa, estendere il modello alla convalida e all'arricchimento.
AWS fornisce una guida completa per la creazione di architetture event-driven, incluse architetture di riferimento per IDP e best practice tratte da AWS Well-Architected Serverless Applications Lens. Per le startup che sviluppano soluzioni di intelligenza artificiale su AWS, questi modelli non sono teorici, ma approcci collaudati utilizzati da aziende che scalano da centinaia a milioni di utenti.
Sei pronto a iniziare a creare applicazioni di intelligenza artificiale basate sugli eventi su AWS? AWS Activate fornisce crediti per compensare il costo di Lambda, EventBridge, Bedrock e gli altri servizi trattati in questo articolo. I fondatori della community AWS Activate beneficiano inoltre di risorse specialistiche, supporto tecnico, tutoraggio aziendale e collegamenti diretti con la community globale di startup. Iscriviti oggi e inizia a sviluppare un'intelligenza artificiale di livello produttivo su AWS.
Come ti è sembrato il contenuto?