Como estava esse conteúdo?
- Aprenda
- Crie agentes de IA escaláveis: alcance 10 mil usuários com arquiteturas orientadas a eventos
Crie agentes de IA escaláveis: alcance 10 mil usuários com arquiteturas orientadas a eventos

Escalar aplicações de IA de centenas para milhares de usuários revela um ponto de inflexão crítico na arquitetura. A arquitetura síncrona, que habilita a prototipagem rápida, torna-se o gargalo que impede o crescimento. Para startups que desenvolvem aplicações de IA na AWS — seja para analisar documentos, gerar conteúdo ou enriquecer dados —, o processamento das workloads pode levar segundos ou minutos por solicitação. Multiplique isso por centenas de usuários simultâneos, e as arquiteturas síncronas esgotam os pools de conexão, excedem os limites de tempo de espera e impedem a velocidade de implantação.
Este artigo descreve como escalar o processamento de documentos por IA de 100 para 10.000 usuários utilizando arquiteturas orientadas a eventos na AWS. O Intelligent Document Processing (IDP) serve como o principal exemplo ao longo de todo o texto, embora esses padrões se apliquem a qualquer workload de IA que necessite de processamento em várias etapas.
Quando os monólitos funcionam (e quando não funcionam)
Com algumas centenas de usuários, um pipeline monolítico de processamento de documentos costuma ser a escolha certa. Uma única instância de computação recebe os documentos enviados por meio de uma API, chama o Amazon Textract (um serviço de machine learning que extrai automaticamente texto, escrita à mão e dados de documentos digitalizados) para extrair dados estruturados, valida os resultados em relação às regras de negócios, enriquece os dados com contexto adicional e grava o resultado final em um banco de dados. Todo o fluxo de trabalho é executado de forma síncrona dentro de um único ciclo de solicitação-resposta. Para uma startup em estágio inicial, essa arquitetura apresenta vantagens significativas: é conceitualmente simples, fácil de depurar e requer uma sobrecarga operacional mínima.
Mas essa arquitetura parte de suposições que se tornam desvantagens em grande escala. O processamento síncrono pressupõe que cada etapa seja concluída com rapidez suficiente para manter uma conexão HTTP aberta. Pressupõe que um pico no processo de upload de documentos não sobrecarregue a etapa de validação, que pode exigir muito da CPU. Pressupõe que uma falha na etapa de enriquecimento não exija o reprocessamento de todo o documento desde o início. Essas suposições se mantêm com algumas centenas de usuários. Em grande escala, elas começam a falhar.
O ponto de ruptura
Ao atingir 1.000 usuários, surgem as primeiras falhas. A extração do Textract, que pode levar de 2 a 3 segundos por documento, começa a gerar um acúmulo de tarefas durante os horários de pico. A etapa de validação, executada no mesmo processo, não tem escalabilidade independente. Se a extração estiver lenta, a validação fica em espera. Se a validação estiver lenta, o enriquecimento fica em espera. Todo o pipeline fica tão lento quanto seu componente mais lento. Os tempos limite de conexão aumentam. Os usuários veem ícones giratórios de “processamento” que nunca param. A equipe de engenharia adiciona mais instâncias, mas isso apenas adia o problema, em vez de resolver o gargalo arquitetônico.
A partir de 5.000 usuários, o monólito se torna insustentável. Uma única falha na etapa de enriquecimento causa um efeito em cascata para trás, bloqueando a validação e a extração. A equipe não consegue implantar atualizações na lógica de validação sem reiniciar todo o pipeline. A escalabilidade da extração independentemente da validação é impossível, já que ambas estão acopladas na mesma base de código e são executadas no mesmo processo. A partir de 10.000 usuários, é necessária uma abordagem diferente.
Mudança para arquiteturas orientadas a eventos
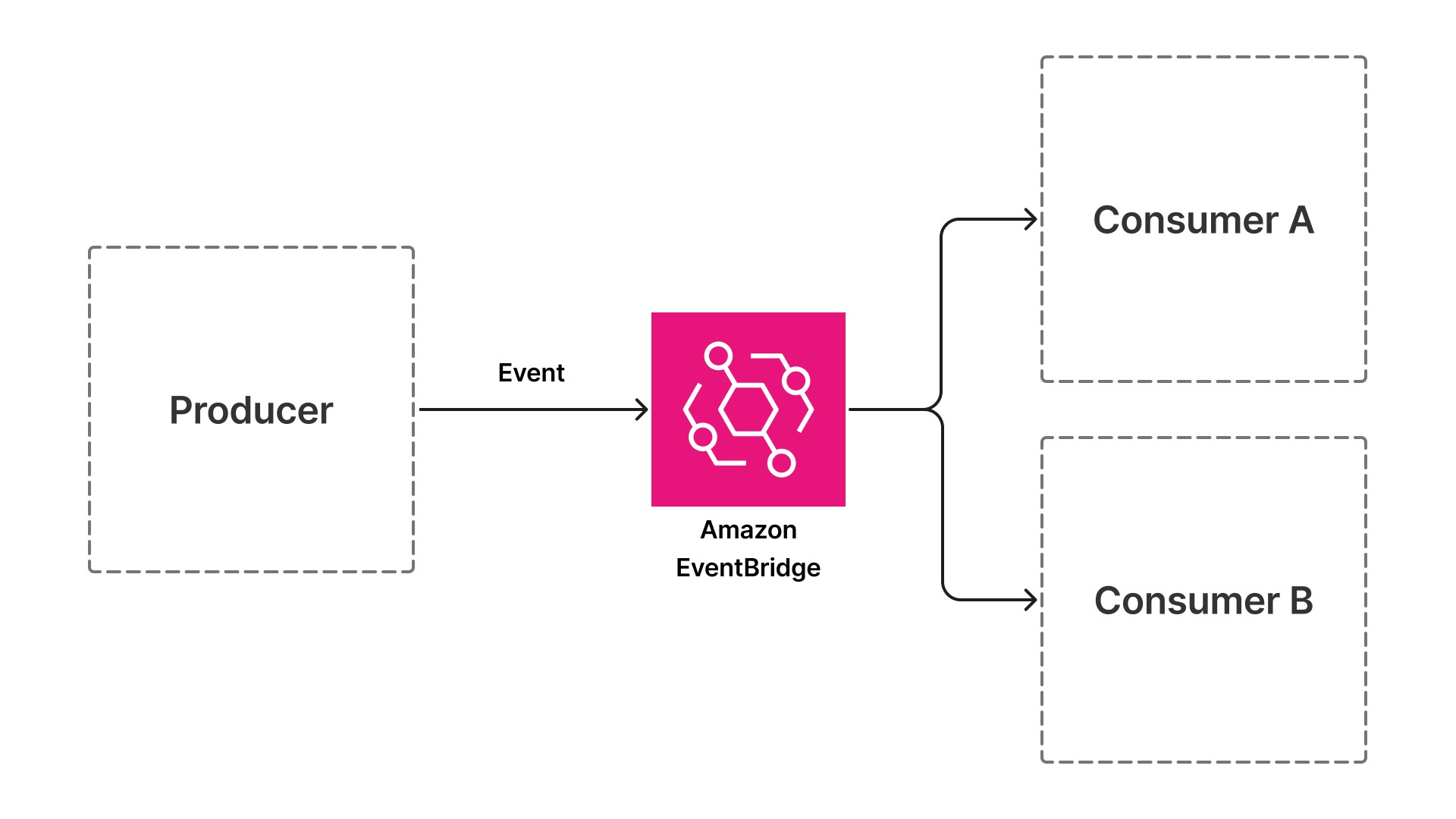
As arquiteturas orientadas a eventos resolvem essa restrição fazendo a troca de chamadas síncronas por eventos assíncronos. Em vez de um componente invocar diretamente o seguinte, cada componente publica um evento ao concluir seu trabalho e se inscreve para receber eventos que sinalizam quando deve começar. A API de envio de documentos publica um evento quando um documento chega. A API de envio de documentos publica um evento quando um documento chega. Cada componente subsequente — desde a extração, passando pela validação, até o enriquecimento — assina o evento anterior, realiza sua tarefa e publica o próximo.
Esse padrão introduz uma camada de indireção: um barramento de eventos como o Amazon EventBridge (um serviço sem servidor que conecta aplicações por meio de eventos) que fica entre produtores e consumidores. Os produtores e os consumidores não têm conhecimento direto uns dos outros. Essa dissociação é a mudança arquitetônica que habilita a escalabilidade independente, o isolamento de falhas e a velocidade de implantação.
Por que isso é importante para workloads de IA
As workloads de IA se beneficiam particularmente desse padrão. A extração com o Textract pode levar 2 segundos para uma fatura simples e 30 segundos para um contrato complexo. O enriquecimento com o Amazon Bedrock pode levar 1 segundo para a classificação e 10 segundos para a extração de entidades com um grande modelo de linguagem. Em uma arquitetura síncrona, esses tempos de processamento variáveis geram latência imprevisível. Em uma arquitetura orientada a eventos, cada etapa é processada em seu próprio ritmo, publicando eventos ao ser concluída. A throughput do pipeline é determinada pelo comportamento de escalabilidade independente de cada etapa, sem ser limitada pelo seu componente mais lento. No caso de workloads de IA com picos de atividade, isso também significa pagar apenas pelo que você usa, em vez de provisionar capacidade para atender aos picos.
Quando fazer a transição
Esse padrão se torna essencial quando uma startup atinge um ponto de inflexão específico: quando o custo dos gargalos síncronos (perda de clientes, tempo de engenharia gasto com correções de emergência, incapacidade de realizar a implantação de atualizações com segurança) excede o custo de gerenciar a complexidade assíncrona. Você chega a esse ponto quando começa a perceber estes sinais:
- Erros de tempo limite de conexão aparecem nos logs durante os horários de pico
- Uma única implantação é necessária para a coordenação de alterações entre várias equipes
- Não é possível garantir a escalabilidade das etapas individuais do processamento
- O processamento com falha é necessário para que os documentos sejam reprocessados do zero
- Sua taxa de erros aumenta proporcionalmente ao tráfego
Para startups em fase inicial com menos de 500 usuários, as arquiteturas orientadas a eventos costumam ser prematuras, já que a sobrecarga operacional supera os benefícios. Para startups que precisam se adaptar de 1.000 para 10.000 usuários, essa é uma transição necessária.
Processamento de documentos orientado a eventos na prática
Considere como esse padrão se aplica à IDP. Uma startup de fintech que está desenvolvendo uma plataforma de análise de contratos para o setor de tecnologia jurídica recebe centenas de contratos diariamente: acordos de confidencialidade (NDAs), contratos de trabalho e contratos com fornecedores. Cada documento passa por um fluxo de trabalho de várias etapas: faça upload, extração, validação, enriquecimento e armazenamento. Em uma arquitetura orientada a eventos, cada etapa é um componente independente como um gatilho para eventos.
O fluxo de trabalho começa quando um usuário faz o upload de um contrato para um bucket do Amazon Simple Storage Service (S3). O S3 publica um evento (Object Created) no barramento padrão do EventBridge. Um componente inscrito nesse evento recupera o documento e chama o Textract para extrair texto, tabelas e pares de chave-valor. O Textract processa o documento de forma assíncrona (isso é fundamental para PDFs grandes, cujo processamento pode levar de 20 a 30 segundos) e, quando a extração é concluída, o componente publica um evento extraction.complete com os dados extraídos.
Um segundo componente, inscrito no evento extraction.complete, valida os dados extraídos em relação às regras de negócios. O contrato inclui as cláusulas necessárias? As datas estão formatadas corretamente? O nome da contraparte está presente? Se a validação for bem-sucedida, o componente publica um evento validation.passed. Se a validação falhar, ele publica um evento validation.failed e encaminha o documento para uma fila de revisão manual (uma fila do Amazon SQS consumida por um fluxo de trabalho que envolve intervenção humana).
Um terceiro componente, inscrito no evento validation.passed, enriquece os dados do contrato usando o Bedrock. Ele pode classificar o tipo de contrato (NDA, contrato de trabalho, contrato com fornecedor), extrair entidades (nomes de empresas, datas, valores monetários) ou resumir termos-chave usando um grande modelo de linguagem, como o Claude, da Anthropic. A inferência sem servidor do Bedrock significa que o componente não precisa gerenciar infraestrutura de GPU; ele simplesmente chama a API do Bedrock e recebe uma saída estruturada. Quando o enriquecimento é concluído, o componente publica um evento enrichment.finished e grava os dados estruturados finais no Amazon DynamoDB(um banco de dados NoSQL sem servidor com latência de milissegundos em grande escala).
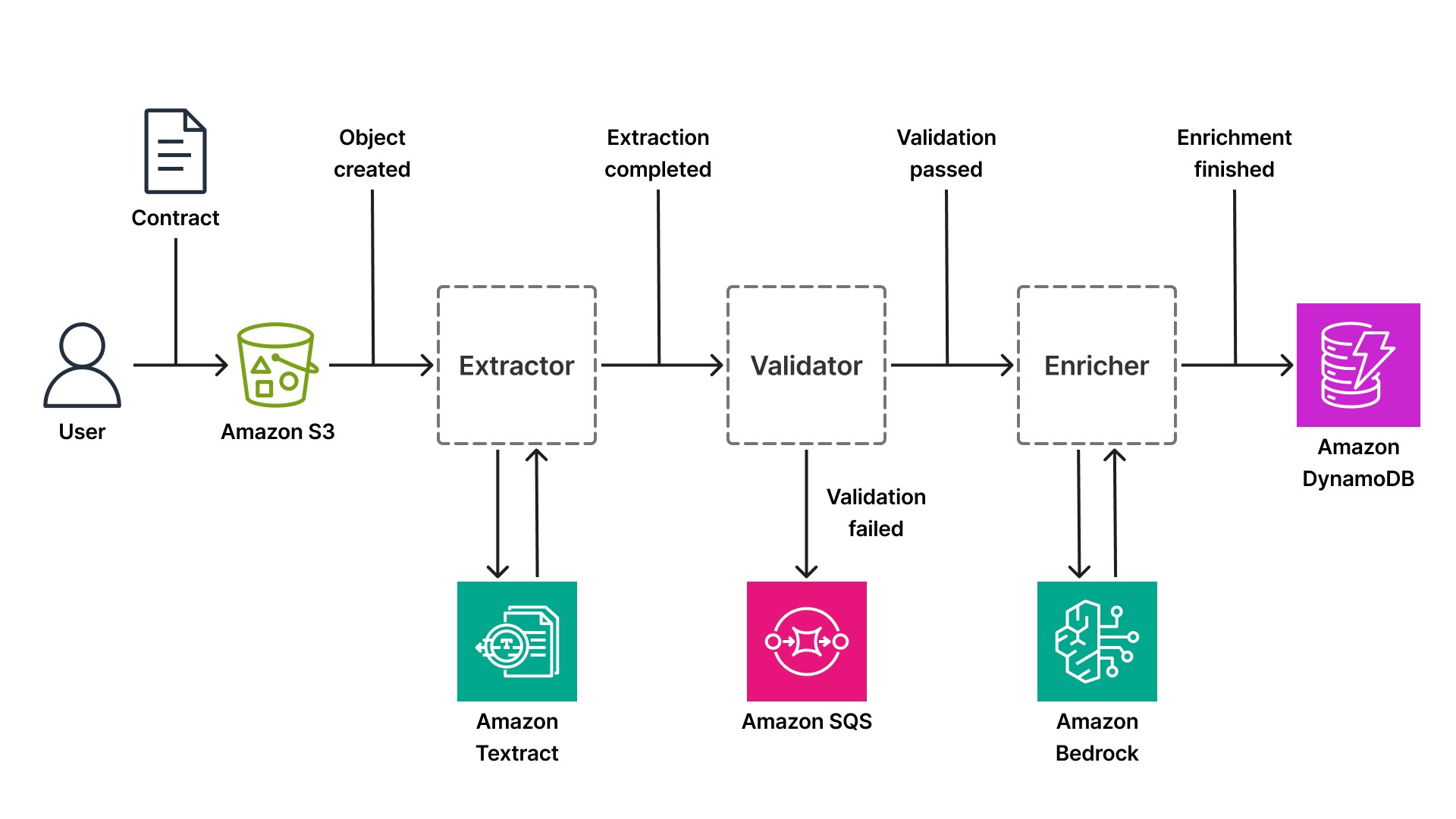
Seja no caso de um pipeline que processe contratos, prontuários médicos ou demonstrações financeiras, o padrão orientado a eventos permanece o mesmo. Apenas o serviço de IA em cada etapa muda. Um pipeline de prontuários médicos pode usar o Amazon Comprehend Medical para extração de entidades, em vez do Bedrock. Um pipeline de demonstrações financeiras pode usar a API especializada AnalyzeExpense do Textract. O princípio arquitetônico se mantém: cada etapa publica eventos, possui escalabilidade independente e pode ser implantada sem afetar as outras etapas.
Para os desenvolvedores que criam esses pipelines, a AWS lançou servidores do protocolo de contexto para modelos (MCP) que se integram a assistentes de programação baseados em IA. O AWS Serverless MCP Server oferece conhecimento especializado para otimizar a forma como os desenvolvedores criam aplicações sem servidor diretamente no ambiente de programação, reduzindo o tempo gasto na busca por documentação.
Os argumentos econômicos a favor da dissociação
As consequências comerciais dessa arquitetura vão além da elegância técnica. As arquiteturas orientadas a eventos transformam os custos fixos em variáveis. Em uma arquitetura monolítica executada em instâncias de computação, uma startup paga pela capacidade 24 horas por dia, 7 dias por semana, independentemente do volume de documentos. Em uma arquitetura orientada a eventos que utiliza o AWS Lambda, a startup paga apenas pelo uso real de computação, com base no número de execuções, na duração delas e na memória alocada. Para workloads com tráfego variável — processando 50 documentos às 2h da manhã e 500 documentos às 14h —, isso pode reduzir significativamente os custos de infraestrutura.
A resiliência aumenta com o isolamento de falhas. Em um pipeline monolítico, um bug na lógica de validação pode travar todo o processo, bloqueando a extração e o enriquecimento. Mas, em um pipeline orientado a eventos, uma falha na validação afeta apenas a etapa de validação. A extração continua processando novos documentos, e o enriquecimento continua processando os documentos validados. Os eventos com falha podem ser encaminhados para filas de mensagens não entregues para análise posterior, e a equipe pode realizar a implantação de uma correção no componente de validação sem precisar reiniciar todo o pipeline.
A velocidade de implantação aumenta porque cada componente pode ser implantado de forma independente. A equipe pode atualizar a lógica de enriquecimento do Bedrock — talvez mudando do Claude Sonnet para o Claude Opus para obter maior precisão — sem alterar o código de extração ou validação. Isso reduz o risco de implantação e permite que a equipe realize iterações mais rapidamente. Para startups em que o tempo de lançamento no mercado é uma vantagem competitiva, isso faz toda a diferença.
Conceitos básicos
A transição de uma arquitetura monolítica para uma arquitetura orientada a eventos não é necessária para reescrever toda a aplicação. Comece separando um único fluxo de trabalho assíncrono, como a extração de documentos, do restante do pipeline. Configure o S3 para publicar eventos no EventBridge quando os documentos forem feitos upload. Crie uma função do Lambda que assine os eventos do S3 e chame o Textract. A função do Lambda, então, publica um evento extraction.complete ao concluir a tarefa. Mantenha o restante do pipeline síncrono. Em seguida, avalie o impacto na latência de processamento e na velocidade de implantação. As principais métricas a serem monitoradas incluem a latência P99, a taxa de erros, o custo por documento e a frequência de implantação. Se os benefícios justificarem a complexidade operacional, expanda o padrão para validação e enriquecimento.
A AWS oferece orientações abrangentes para a criação de arquiteturas orientadas a eventos, incluindo arquiteturas de referência para IDP e práticas recomendadas da AWS Well-Architected Serverless Applications Lens. Para startups que desenvolvem aplicações de IA na AWS, esses padrões não são meras teorias. Trata-se de abordagens comprovadas, utilizadas por empresas que possuem escalabilidade de centenas para milhões de usuários.
Pronto para começar a desenvolver aplicações de IA orientadas a eventos na AWS? O AWS Activate oferece créditos para compensar o custo do Lambda, do EventBridge, do Bedrock e dos demais serviços abordados neste artigo. Os fundadores da comunidade AWS Activate também se beneficiam de recursos especializados, suporte técnico, orientação empresarial e conexões diretas com a comunidade global de startups. Inscreva-se hoje mesmo e comece a desenvolver IA pronta para produção na AWS.
Como estava esse conteúdo?