Comment a été ce contenu ?
- Apprendre
- Développez des agents d’IA évolutifs : passez à 10 000 utilisateurs grâce à des architectures orientées événements
Développez des agents d’IA évolutifs : passez à 10 000 utilisateurs grâce à des architectures orientées événements

L’évolution des applications d’IA, passant de quelques centaines à plusieurs milliers d’utilisateurs, met en évidence un tournant architectural décisif. L’architecture synchrone, qui permet un prototypage rapide, devient alors le goulot d’étranglement qui freine la croissance. Pour les start-ups qui développent des applications d’IA sur AWS, qu’il s’agisse d’analyser des documents, de générer du contenu ou d’enrichir des données, le traitement des charges de travail peut prendre plusieurs secondes, voire plusieurs minutes, par requête. Multipliez ce temps par des centaines d’utilisateurs simultanés, et les architectures synchrones épuisent les pools de connexions, dépassent les seuils de délai d’attente et ralentissent la vitesse de déploiement.
Cet article explique comment faire évoluer le traitement de documents par IA de 100 à 10 000 utilisateurs à l’aide d’architectures orientées événements sur AWS.Le traitement intelligent des documents (IDP) sert d’exemple principal tout au long de cet article, bien que ces modèles s’appliquent à toute charge de travail d’IA nécessitant un traitement en plusieurs étapes.
Quand les architectures monolithiques fonctionnent (et quand elles ne fonctionnent pas)
Avec quelques centaines d’utilisateurs, un pipeline monolithique de traitement des documents constitue souvent le choix le plus judicieux. Une seule instance de calcul reçoit les documents chargés via une API, appelle Amazon Textract (un service de machine learning qui extrait automatiquement du texte, de l’écriture manuscrite et des données à partir de documents numérisés) pour extraire des données structurées, valide les résultats par rapport aux règles métier, enrichit les données avec du contexte supplémentaire, puis enregistre le résultat final dans une base de données. L’ensemble du flux de travail s’exécute de manière synchrone au cours d’un seul cycle requête-réponse. Pour une start-up en phase de démarrage, cette architecture présente des avantages significatifs : elle est simple sur le plan conceptuel, facile à déboguer et nécessite une charge opérationnelle minimale.
Mais cette architecture repose sur des hypothèses qui deviennent des freins à grande échelle. Le traitement synchrone part du principe que chaque étape s’achève suffisamment rapidement pour maintenir une connexion HTTP ouverte. Il part du principe qu’un pic de chargements de documents ne saturera pas l’étape de validation, qui peut être très gourmande en ressources CPU. Il part du principe qu’une défaillance au stade de l’enrichissement ne nécessite pas de retraiter l’intégralité du document depuis le début. Ces hypothèses tiennent la route avec quelques centaines d’utilisateurs. À grande échelle, elles commencent à s’effriter.
Le point de rupture
À partir de 1 000 utilisateurs, les premières failles apparaissent. L’extraction Textract, qui peut prendre 2 à 3 secondes par document, commence à générer un retard pendant les heures de pointe. L’étape de validation, qui s’exécute dans le même processus, ne peut pas être mise à l’échelle de manière indépendante. Si l’extraction est lente, la validation est bloquée. Si la validation est lente, l’enrichissement est bloqué. L’ensemble du pipeline devient aussi lent que son composant le plus lent. Les délais d’expiration des connexions augmentent. Les utilisateurs voient s’afficher des icônes de « traitement » qui ne disparaissent jamais. L’équipe d’ingénieurs ajoute des instances supplémentaires, mais cela ne fait que repousser le problème, sans résoudre le goulot d’étranglement architectural.
À partir de 5 000 utilisateurs, cette architecture monolithique devient intenable. Une seule défaillance au niveau de l’étape d’enrichissement provoque un effet domino en amont, bloquant ainsi la validation et l’extraction. L’équipe ne peut pas déployer de mises à jour sur la logique de validation sans redémarrer l’ensemble du pipeline. Il est impossible de faire évoluer l’extraction indépendamment de la validation, car ces deux processus sont couplés au sein d’une même code base et s’exécutent dans le même processus. À partir de 10 000 utilisateurs, une approche différente s’impose.
Opter pour des architectures guidées par les événements
Les architectures orientées événements résolvent cette contrainte en remplaçant les appels synchrones par des événements asynchrones. Au lieu qu’un composant appelle directement le suivant, chaque composant publie un événement lorsqu’il a terminé son travail et s’abonne aux événements qui lui signalent quand il doit commencer. L’API de téléchargement de documents publie un événement lorsqu’un document arrive. L’API de téléchargement de documents publie un événement lorsqu’un document arrive. Chaque composant suivant, de l’extraction à l’enrichissement en passant par la validation, s’abonne à l’événement précédent, effectue son travail, puis publie l’événement suivant.
Ce modèle introduit un niveau d’indirection : un bus d’événements tel qu’Amazon EventBridge (un service sans serveur qui relie les applications à l’aide d’événements) qui s’interpose entre les producteurs et les consommateurs. Les producteurs et les consommateurs n’ont aucune connaissance directe les uns des autres. Ce découplage constitue le changement architectural qui permet une mise à l’échelle indépendante, l’isolation des pannes et une rapidité de déploiement.
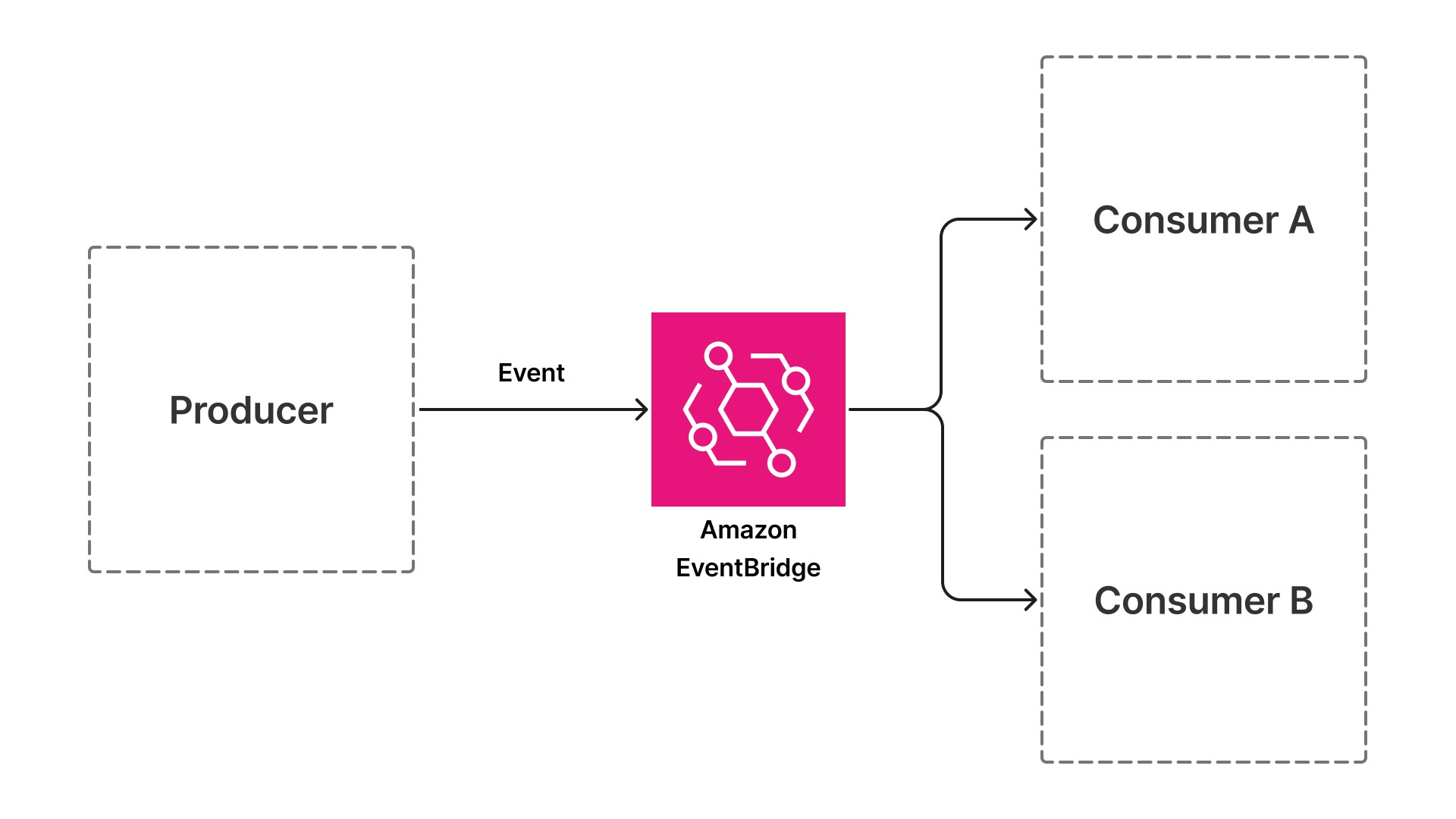
En quoi ces éléments sont importants pour les charges de travail liées à l’IA
Les charges de travail liées à l’IA tirent particulièrement profit de ce modèle. L’extraction avec Textract peut prendre deux secondes pour une facture simple et 30 secondes pour un contrat complexe. L’enrichissement avec Amazon Bedrock peut prendre une seconde pour la classification et dix secondes pour l’extraction d’entités à l’aide d’un grand modèle de langage. Dans une architecture synchrone, ces temps de traitement variables génèrent une latence imprévisible. Dans une architecture événementielle, chaque étape s’exécute à son propre rythme et publie des événements une fois terminée. Le débit du pipeline est déterminé par le comportement de mise à l’échelle indépendant de chaque étape, sans être limité par son composant le plus lent. Pour les charges de travail d’IA à pics de trafic, cela signifie également que vous ne payez que ce que vous utilisez, plutôt que de devoir provisionner une capacité maximale.
Quand effectuer la transition
Ce modèle devient indispensable lorsqu’une start-up atteint un point d’inflexion spécifique : lorsque le coût des goulots d’étranglement synchrones (clients perdus, temps passé par les ingénieurs à résoudre des problèmes urgents, impossibilité de déployer des mises à jour en toute sécurité) dépasse le coût lié à la gestion de la complexité asynchrone. Vous avez atteint ce stade lorsque vous commencez à observer les signes suivants :
- Des erreurs de délai d’expiration de connexion apparaissent dans les journaux pendant les heures de pointe
- Un seul déploiement nécessite de coordonner les modifications entre plusieurs équipes
- Vous ne pouvez pas mettre à l’échelle les différentes étapes de traitement indépendamment
- L’échec du traitement nécessite de retraiter l’intégralité des documents depuis le début
- Votre taux d’erreur augmente proportionnellement au trafic
Pour les start-ups en phase de démarrage comptant moins de 500 utilisateurs, les architectures orientées événements sont souvent prématurées, car la charge opérationnelle l’emporte sur les avantages. Pour les start-ups passant de 1 000 à 10 000 utilisateurs, il s’agit d’une transition nécessaire.
Le traitement des documents piloté par les événements dans la pratique
Voyons comment ce modèle s’applique au traitement intelligent des documents. Une start-up fintech développant une plateforme d’analyse de contrats pour le secteur des technologies juridiques reçoit chaque jour des centaines de contrats : accords de confidentialité, contrats de travail, contrats avec des fournisseurs. Chaque document suit un flux de travail en plusieurs étapes : chargement, extraction, validation, enrichissement et stockage. Dans une architecture orientée événements, chaque étape est un composant indépendant déclenché par des événements.
Le flux de travail démarre lorsqu’un utilisateur charge un contrat dans un compartiment Amazon Simple Storage Service (S3). S3 publie un événement (Objet créé) sur le bus par défaut d’EventBridge. Un composant abonné à cet événement récupère le document et appelle Textract pour extraire le texte, les tableaux et les paires clé-valeur. Textract traite le document de manière asynchrone (ce qui est essentiel pour les fichiers PDF volumineux dont le traitement peut prendre entre 20 et 30 secondes) et, une fois l’extraction terminée, le composant publie un événement extraction.complete contenant les données extraites.
Un deuxième composant, abonné à l’événement extraction.complete, valide les données extraites au regard des règles métier. Le contrat contient-il toutes les clauses obligatoires ? Les dates sont-elles correctement formatées ? Le nom de la contrepartie est-il présent ? Si la validation aboutit, le composant publie un événement validation.passed. En cas d’échec de la validation, il publie un événement validation.failed et achemine le document vers une file d’attente de révision manuelle (une file d’attente Amazon SQS gérée par un flux de travail impliquant une intervention humaine).
Un troisième composant, abonné à l’événement validation.passed, enrichit les données du contrat à l’aide de Bedrock. Il peut classer le type de contrat (accord de confidentialité, contrat de travail, contrat fournisseur), extraire des entités (noms d’entreprises, dates, montants financiers) ou résumer les clauses clés à l’aide d’un modèle linguistique de grande envergure tel que Claude d’Anthropic. Grâce à l’inférence sans serveur de Bedrock, le composant n’a pas besoin de gérer d’infrastructure GPU : il lui suffit d’appeler l’API Bedrock pour recevoir un résultat structuré. Une fois l’enrichissement terminé, le composant publie un événement enrichment.finished et enregistre les données structurées finales dans Amazon DynamoDB (une base de données NoSQL sans serveur offrant une latence de l’ordre de la milliseconde, quelle que soit l’échelle).
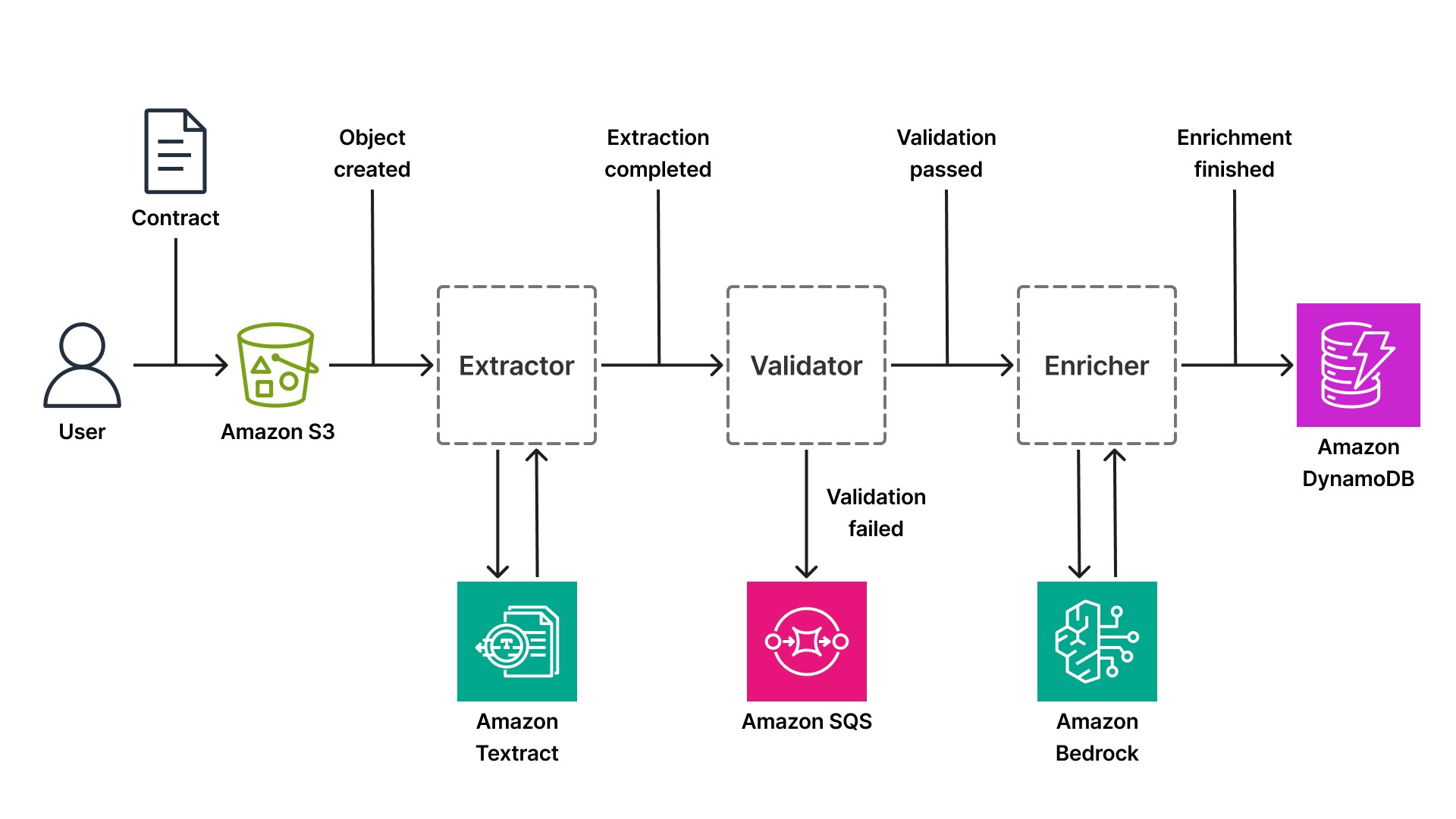
Que le pipeline traite des contrats, des dossiers médicaux ou des états financiers, le modèle basé sur les événements reste le même. Seul le service d’IA utilisé à chaque étape change. Un pipeline de dossiers médicaux pourrait par exemple utiliser Amazon Comprehend Medical pour l’extraction d’entités à la place de Bedrock. Un pipeline d’états financiers pourrait quant à lui utiliser l’API spécialisée AnalyzeExpense de Textract. Le principe architectural reste le même : chaque étape publie des événements, s’adapte de manière indépendante et peut être déployée sans affecter les autres étapes.
Pour les développeurs qui mettent en place ces pipelines, AWS a lancé des serveurs de protocole de contextualisation des modèles (MCP) qui s’intègrent aux assistants de codage basés sur l’IA. Le serveur MCP sans serveur d’AWS apporte son expertise pour optimiser la manière dont les développeurs créent des applications sans serveur directement au sein de l’environnement de codage, ce qui réduit le temps passé à consulter la documentation.
L’analyse de rentabilisation du découplage
Les implications commerciales de cette architecture vont au-delà de l’élégance technique. Les architectures orientées événements transforment les coûts fixes en coûts variables. Dans une architecture monolithique fonctionnant sur des instances de calcul, une start-up paie pour la capacité 24 heures sur 24, 7 jours sur 7, quel que soit le volume de documents. Dans une architecture orientée événements utilisant AWS Lambda, la start-up ne paie que pour l’utilisation réelle des ressources de calcul, en fonction du nombre d’exécutions, de leur durée et de la mémoire allouée. Pour les charges de travail présentant un trafic variable, traitant par exemple 50 documents à 2 h du matin et 500 documents à 14 h, cela peut réduire considérablement les coûts d’infrastructure.
L’isolation des défaillances permet d’améliorer la résilience. Dans un pipeline monolithique, un bug dans la logique de validation peut provoquer le plantage de l’ensemble du processus, bloquant ainsi l’extraction et l’enrichissement. En revanche, dans un pipeline piloté par les événements, un échec de validation n’affecte que l’étape de validation. L’extraction continue de traiter les nouveaux documents, et l’enrichissement poursuit le traitement des documents validés. Les événements ayant échoué peuvent être acheminés vers des files d’attente de messages perdus en vue d’une analyse ultérieure, et l’équipe peut déployer un correctif sur le composant de validation sans avoir à redémarrer l’intégralité du pipeline.
La vitesse de déploiement augmente, car chaque composant peut être déployé indépendamment. L’équipe peut mettre à jour la logique d’enrichissement de Bedrock, par exemple en passant de Claude Sonnet à Claude Opus pour une plus grande précision, sans toucher au code d’extraction ou de validation. Cela réduit les risques liés au déploiement et permet à l’équipe d’accélérer ses itérations. Pour les start-ups pour lesquelles la rapidité de mise sur le marché constitue un avantage concurrentiel, cet aspect est déterminant.
Mise en route
La transition d’une architecture monolithique vers une architecture orientée événements ne nécessite pas de réécrire l’intégralité de l’application. Commencez par découpler un seul flux de travail asynchrone, tel que l’extraction de documents, du reste du pipeline. Configurez S3 pour qu’il publie des événements vers EventBridge lorsque des documents sont mis en ligne. Créez une fonction Lambda qui s’abonne aux événements S3 et appelle Textract. La fonction Lambda publie ensuite un événement extraction.complete une fois l’opération terminée. Conservez le reste du pipeline en mode synchrone. Évaluez ensuite l’impact sur la latence de traitement et la vitesse de déploiement. Les indicateurs clés à suivre comprennent la latence P99, le taux d’erreur, le coût par document et la fréquence de déploiement. Si les avantages justifient la complexité opérationnelle, étendez ce modèle à la validation et à l’enrichissement.
AWS propose des conseils complets pour la conception d’architectures orientées événements, notamment des architectures de référence pour les IDP et les bonnes pratiques issues du guide Applications sans serveur AWS Well-Architected Lens. Pour les start-ups qui développent des solutions d’IA sur AWS, ces modèles ne sont pas purement théoriques. Il s’agit d’approches éprouvées, utilisées par des entreprises dont le nombre d’utilisateurs passe de quelques centaines à plusieurs millions.
Prêt à vous lancer dans le développement d’applications d’IA pilotées par les événements sur AWS ? AWS Activate offre des crédits permettant de réduire le coût de Lambda, EventBridge, Bedrock et des autres services présentés dans cet article. Les fondateurs membres de la communauté AWS Activate bénéficient également de ressources spécialisées, d’une assistance technique, d’un accompagnement commercial et de liens directs avec la communauté mondiale des start-ups. Rejoignez-nous dès aujourd’hui et commencez à développer des solutions d’IA prêtes pour la production sur AWS.
Comment a été ce contenu ?