¿Qué le pareció este contenido?
- Aprender
- Cree agentes de IA que escalen: crezca hasta 10 000 usuarios con arquitecturas basadas en eventos
Cree agentes de IA que escalen: crezca hasta 10 000 usuarios con arquitecturas basadas en eventos

Escalar aplicaciones de IA de cientos a miles de usuarios revela un punto de inflexión arquitectónico crítico. La arquitectura síncrona que permite crear prototipos rápidamente se convierte en el cuello de botella que impide el crecimiento. Para startups que crean aplicaciones de IA sobre AWS, ya sea para analizar documentos, generar contenido o enriquecer datos, el procesamiento de cargas de trabajo puede tardar segundos o minutos por solicitud. Multiplique eso por cientos de usuarios simultáneos y las arquitecturas síncronas agotarán grupos de conexiones, superarán umbrales de tiempo de espera y bloquearán la velocidad de implementación.
Este artículo describe cómo escalar el procesamiento documental con IA de 100 a 10 000 usuarios mediante arquitecturas basadas en eventos sobre AWS. El procesamiento inteligente de documentos (IDP) se usa como ejemplo principal en todo el artículo,aunque estos patrones se aplican a cualquier carga de trabajo de IA que requiera procesamiento en varios pasos.
Cuándo funcionan los monolitos (y cuándo no)
Con unos pocos cientos de usuarios, una canalización monolítica de procesamiento documental suele ser la opción adecuada. Una única instancia de cómputo recibe cargas de documentos mediante una API, llama a Amazon Textract (un servicio de machine learning que extrae automáticamente texto, escritura manual y datos de documentos escaneados) para extraer datos estructurados, valida los resultados con respecto a reglas empresariales, enriquece los datos con contexto adicional y escribe la salida final en una base de datos. Todo el flujo de trabajo se ejecuta de forma síncrona dentro de un único ciclo de solicitud y respuesta. Para una startup en fase inicial, esta arquitectura ofrece ventajas importantes: es conceptualmente sencilla, fácil de depurar y requiere una carga operativa mínima.
Pero esta arquitectura incorpora supuestos que se convierten en problemas al escalar. El procesamiento síncrono presupone que cada paso termina con suficiente rapidez para mantener abierta una conexión HTTP. Presupone que un pico en la carga de documentos no saturará el paso de validación, que puede requerir mucha CPU. Presupone que un fallo en la fase de enriquecimiento no obligará a volver a procesar todo el documento desde cero. Estos supuestos funcionan con unos cientos de usuarios. A escala, empiezan a romperse.
El punto de ruptura
Al llegar a 1000 usuarios, aparecen las primeras grietas. La extracción con Textract, que puede tardar entre 2 y 3 segundos por documento, empieza a generar acumulación durante las horas punta. El paso de validación, que se ejecuta en el mismo proceso, no puede escalarse de forma independiente. Si la extracción es lenta, la validación espera. Si la validación es lenta, el enriquecimiento espera. Toda la canalización se vuelve tan lenta como su componente más lento. Aumentan los tiempos de espera de conexión. Los usuarios ven indicadores de “procesando” que nunca terminan. El equipo de ingeniería añade más instancias, pero esto solo retrasa el problema en lugar de resolver el cuello de botella arquitectónico.
Con 5000 usuarios, el monolito deja de ser viable. Un único fallo en el paso de enriquecimiento se propaga hacia atrás y bloquea la validación y la extracción. El equipo no puede implementar actualizaciones en la lógica de validación sin reiniciar toda la canalización. Escalar la extracción independientemente de la validación es imposible porque ambas están acopladas en la misma base de código y se ejecutan en el mismo proceso. Con 10 000 usuarios, necesita un enfoque diferente.
Traspaso a las arquitecturas impulsadas por eventos
Las arquitecturas basadas en eventos resuelven esta limitación reemplazando llamadas síncronas por eventos asíncronos. En lugar de que un componente invoque directamente al siguiente, cada componente publica un evento cuando termina su trabajo y se suscribe a eventos que indican cuándo debe comenzar. La API de carga de documentos publica un evento cuando llega un documento. La API de carga de documentos publica un evento cuando llega un documento. Cada componente posterior, desde la extracción hasta la validación y el enriquecimiento, se suscribe al evento anterior, realiza su trabajo y publica el siguiente.
Este patrón introduce una capa de indirecta: un bus de eventos como Amazon EventBridge (un servicio sin servidor que conecta aplicaciones mediante eventos) situado entre productores y consumidores. Productores y consumidores no tienen conocimiento directo entre sí. Este desacoplamiento es el cambio arquitectónico que permite escalado independiente, aislamiento de fallos y velocidad de implementación.
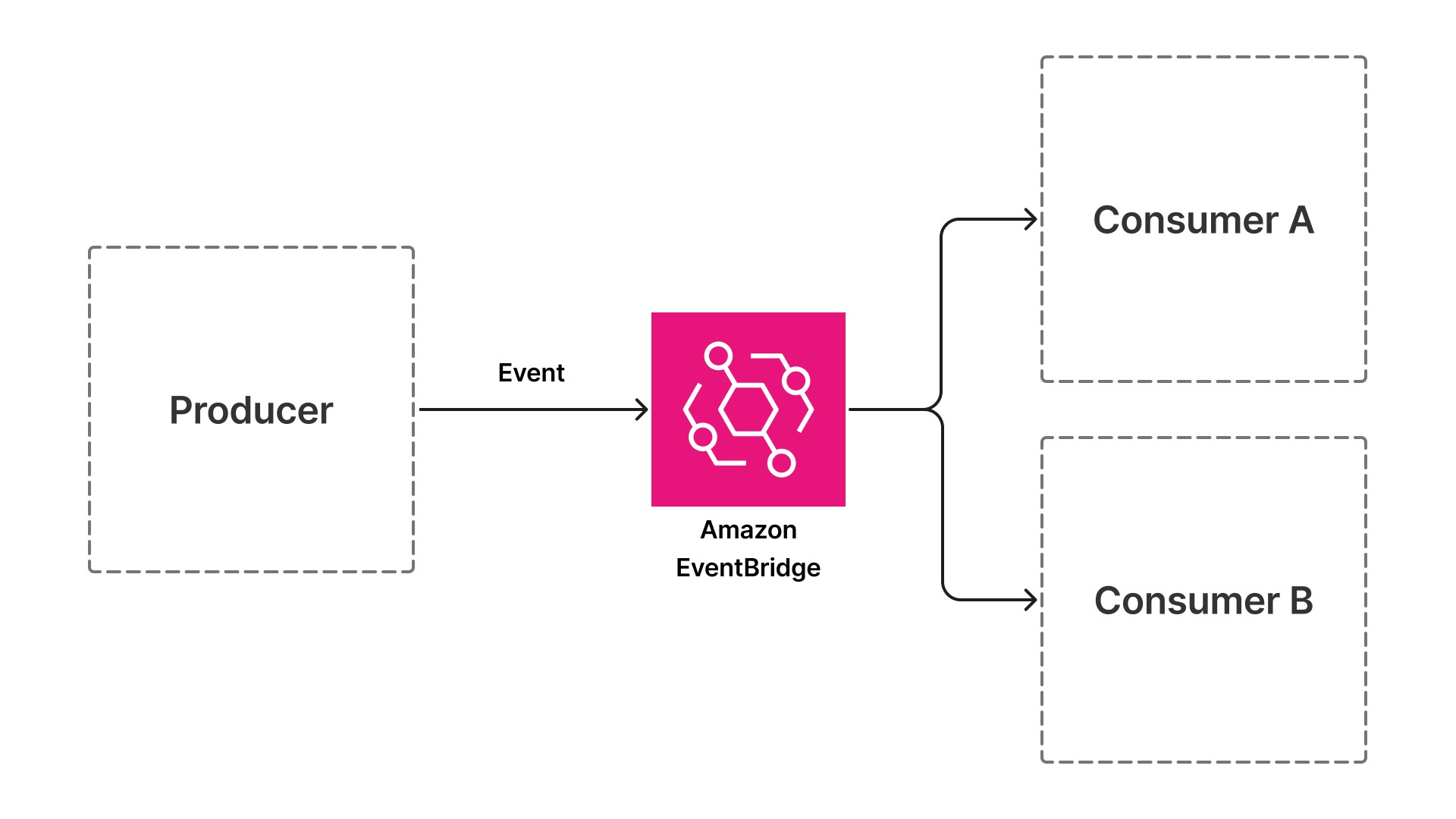
Por qué esto importa para las cargas de trabajo de IA
Las cargas de trabajo de IA se benefician especialmente de este patrón. La extracción con Textract puede tardar 2 segundos para una factura sencilla y 30 segundos para un contrato complejo. Amazon Bedrock El enriquecimiento puede tardar 1 segundo para clasificación y 10 segundos para extracción de entidades con un modelo de lenguaje de gran tamaño. En una arquitectura síncrona, estos tiempos de procesamiento variables generan latencia impredecible. En una arquitectura basada en eventos, cada paso procesa a su propio ritmo y publica eventos cuando finaliza. El rendimiento de la canalización está determinado por el comportamiento de escalado independiente de cada etapa y no queda limitado por su componente más lento. Para cargas de trabajo de IA con picos de demanda, esto también significa pagar solo por lo que usa en lugar de aprovisionar para capacidad máxima.
Cuándo hacer la transición
Este patrón se vuelve esencial cuando una startup alcanza un punto de inflexión concreto: cuando el costo de los cuellos de botella síncronos (clientes perdidos, tiempo de ingeniería dedicado a apagar incendios, imposibilidad de implementar actualizaciones de forma segura) supera el costo de gestionar la complejidad asíncrona. Ha llegado a este punto cuando empieza a ver estas señales:
- Aparecen errores de tiempo de espera de conexión en los registros durante las horas punta
- Una única implementación requiere coordinar cambios entre varios equipos
- No puede escalar pasos individuales del procesamiento de forma independiente
- Los errores de procesamiento obligan a volver a procesar documentos completos desde cero
- La tasa de errores aumenta proporcionalmente con el tráfico
Para startups en fase inicial con menos de 500 usuarios, las arquitecturas basadas en eventos suelen ser prematuras porque la carga operativa supera los beneficios. Para startups que escalan de 1000 a 10 000 usuarios, es una transición necesaria.
Procesamiento documental basado en eventos en la práctica
Considere cómo se aplica este patrón al IDP. Una startup de tecnología financiera que desarrolla una plataforma de análisis de contratos para tecnología jurídica recibe cientos de contratos al día: NDA, contratos laborales, contratos con proveedores. Cada documento sigue un flujo de trabajo de varios pasos: carga, extracción, validación, enriquecimiento y almacenamiento. En una arquitectura basada en eventos, cada paso es un componente independiente activado por eventos.
El flujo de trabajo comienza cuando un usuario carga un contrato en un bucket de Amazon Simple Storage Service (S3). S3 publica un evento (Object Created) en el bus predeterminado de EventBridge. Un componente suscrito a este evento recupera el documento y llama a Textract para extraer texto, tablas y pares clave-valor. Textract procesa el documento de forma asíncrona (esto es fundamental para archivos PDF grandes que pueden tardar entre 20 y 30 segundos en procesarse) y, cuando finaliza la extracción, el componente publica un evento extraction.complete con los datos extraídos.
Un segundo componente, suscrito a extraction.complete, valida los datos extraídos con respecto a reglas empresariales. ¿El contrato incluye las cláusulas obligatorias? ¿Las fechas tienen el formato correcto? ¿Está presente el nombre de la contraparte? Si la validación se supera, el componente publica un evento validation.passed. Si falla, publica un evento validation.failed y dirige el documento a una cola de revisión manual (una cola de Amazon SQS consumida por un flujo de trabajo con intervención humana).
Un tercer componente, suscrito a validation.passed, enriquece los datos del contrato mediante Bedrock. Puede clasificar el tipo de contrato (NDA, laboral, proveedor), extraer entidades (nombres de empresas, fechas, importes monetarios) o resumir términos clave mediante un modelo de lenguaje de gran tamaño como Claude de Anthropic. La inferencia sin servidor de Bedrock significa que el componente no necesita administrar infraestructura de GPU; simplemente llama a la API de Bedrock y recibe una salida estructurada. Cuando finaliza el enriquecimiento, el componente publica un evento enrichment.finished y escribe los datos estructurados finales en Amazon DynamoDB(una base de datos NoSQL sin servidor con latencia de milisegundos a cualquier escala).
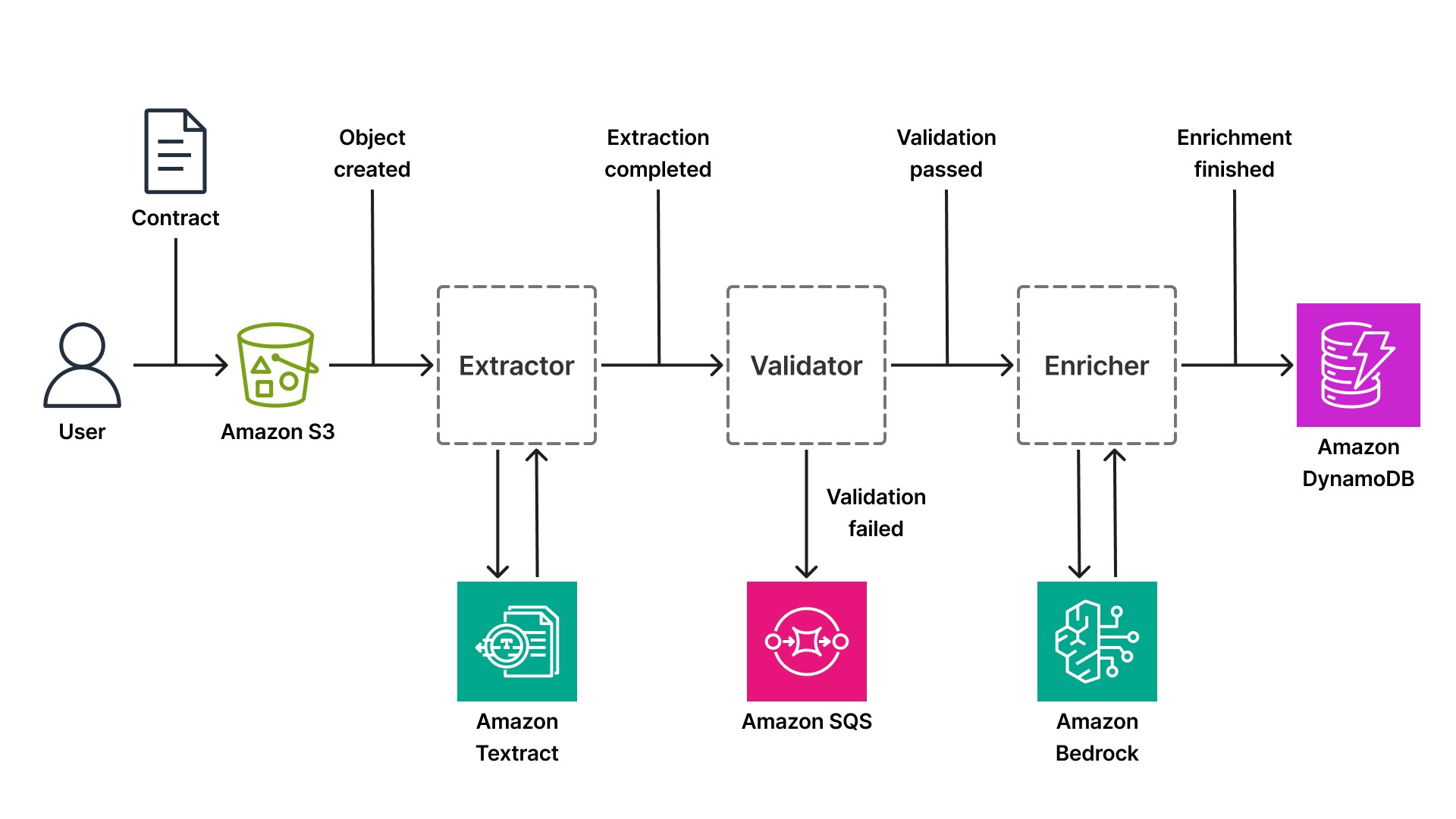
Tanto si la canalización procesa contratos, historiales médicos o estados financieros, el patrón basado en eventos sigue siendo el mismo. Solo cambia el servicio de IA usado en cada paso. Una canalización de historiales médicos podría usar Amazon Comprehend Medical para extracción de entidades en lugar de Bedrock. Una canalización de estados financieros podría usar la API especializada AnalyzeExpense API de Textract. El principio arquitectónico se mantiene: cada paso publica eventos, escala de forma independiente y puede implementarse sin afectar al resto de etapas.
Para los desarrolladores que crean estas canalizaciones, AWS ha lanzado servidores de protocolos de contexto de modelos (MCP) que se integran con asistentes de programación basados en IA. El AWS Serverless MCP Server proporciona experiencia especializada para simplificar la forma en que los desarrolladores crean aplicaciones sin servidor directamente desde el entorno de programación y reducir el tiempo dedicado a buscar documentación.
El argumento empresarial a favor del desacoplamiento
Las consecuencias empresariales de esta arquitectura van más allá de la elegancia técnica. Las arquitecturas basadas en eventos trasladan los costos de fijos a variables. En una arquitectura monolítica que se ejecuta sobre instancias de cómputo, una startup paga capacidad de manera ininterrumpida, independientemente del volumen de documentos. En una arquitectura basada en eventos que usa AWS Lambda, la startup paga solo por el uso real de cómputo según el número de ejecuciones, su duración y la memoria asignada. Para cargas de trabajo con tráfico variable, que procesan 50 documentos a las 2:00 y 500 documentos a las 14:00, esto puede reducir significativamente los costos de infraestructura.
La resiliencia mejora gracias al aislamiento de fallos. En una canalización monolítica, un error en la lógica de validación puede hacer que falle todo el proceso y bloquear la extracción y el enriquecimiento. Pero en una canalización basada en eventos, un fallo de validación afecta solo a la etapa de validación. La extracción sigue procesando documentos nuevos y el enriquecimiento continúa procesando documentos validados. Los eventos fallidos pueden dirigirse a colas de mensajes fallidos para analizarlos posteriormente y el equipo puede implementar una corrección en el componente de validación sin reiniciar toda la canalización.
La velocidad de implementación aumenta porque cada componente puede implementarse de forma independiente. El equipo puede actualizar la lógica de enriquecimiento de Bedrock, por ejemplo, cambiar de Claude Sonnet a Claude Opus para obtener mayor precisión, sin modificar el código de extracción o validación. Esto reduce el riesgo de implementación y permite iterar más rápido. Para startups donde el tiempo de salida al mercado es una ventaja competitiva, esto importa.
Introducción
La transición de una arquitectura monolítica a una arquitectura basada en eventos no requiere reescribir toda la aplicación. Empiece por desacoplar un único flujo de trabajo asíncrono, como la extracción de documentos, del resto de la canalización. Configure S3 para publicar eventos en EventBridge cuando se carguen documentos. Cree una función de Lambda que se suscriba a los eventos de S3 y llame a Textract. Después, la función de Lambda publica un evento extraction.complete cuando finaliza. Mantenga el resto de la canalización como síncrona. Después mida el impacto sobre la latencia de procesamiento y la velocidad de implementación. Entre las métricas clave que debe supervisar se incluyen la latencia P99, la tasa de errores, el costo por documento y la frecuencia de implementación. Si los beneficios justifican la complejidad operativa, amplíe el patrón a validación y enriquecimiento.
AWS proporciona orientación exhaustiva para crear arquitecturas basadas en eventos, incluidas arquitecturas de referencia para IDP y prácticas recomendadas de AWS Well-Architected Serverless Applications Lens. Para las startups que crean soluciones de IA sobre AWS, estos patrones no son teóricos. Son enfoques probados utilizados por empresas que escalan de cientos a millones de usuarios.
¿Listo para empezar a crear aplicaciones de IA basadas en eventos sobre AWS? AWS Activate proporciona créditos para compensar el costo de Lambda, EventBridge, Bedrock y los demás servicios descritos en este artículo. Los fundadores de la comunidad AWS Activate también se benefician de recursos especializados, soporte técnico, mentoría empresarial y conexiones directas con la comunidad global de startups. Únase hoy y empiece a crear IA lista para producción sobre AWS.
¿Qué le pareció este contenido?