このコンテンツはいかがでしたか?
コンテンツの言語
現時点では、すべてのコンテンツが翻訳されているわけではありません。
- 学ぶ
- Prove It, Part 2: Formal logic, Cedar policies, and the economics of verification
Prove It, Part 2: Formal logic, Cedar policies, and the economics of verification

Automated reasoning adds verification on top of LLM outputs by translating business policies into formal logic and checking them against those rules. It detects hallucinations, enforces compliance constraints, and controls agent actions with full coverage at a fraction of the cost of manual QA.

In Part 1 ('Probably Correct' Is Not Good Enough"), we covered why startups building on AI need deterministic verification, not just probabilistic safeguards. In this post, we go under the hood. If you are a technical co-founder, engineering lead, or senior developer at an AI startup, this is where you learn how automated reasoning actually works, what happens when your LLM generates a response and formal logic checks it, and why the economics makes this a no-brainer compared to hiring QA teams.
No API code in this post. That comes in Part 3. Here we focus on concepts, formal logic, and the verification pipeline so you understand what you are building.
Stochastic vs. deterministic: The fundamental distinction
Before diving into the mechanics, it is worth grounding the core distinction clearly, as it affects every architectural decision you make.
LLMs are stochastic.
They predict the next token based on probability distributions learned from training data. Temperature, top-k, and top-p sampling parameters introduce deliberate randomness. Run the same prompt twice and you may get different answers. This is a feature, not a bug: it is what makes LLMs flexible, creative, and capable of handling diverse natural language inputs. But it also means that any single output is a sample from a probability distribution, not a proven fact.
Automated reasoning (AR) is correct.
Given a set of rules and an input, the result is not a best guess. It is a proof. A statement is either provably valid with respect to your rules, provably invalid, or the system tells you precisely what information is missing or ambiguous. If the answer is wrong, AR does not just flag it; it gives you a counterexample showing exactly why it fails. The output is mathematically verifiable, not probabilistic. There is no temperature knob. There is no sampling. There is a proof you can inspect.
This is not about one approach being "better." LLMs are better at understanding natural language and generating human-like responses. AR is better at checking whether those responses are logically correct. Together, they form the complete stack: the LLM handles the conversation, AR handles correctness. This combination of neural networks and formal logic is what researchers call neurosymbolic AI.
For a five-person startup shipping to your first 100 customers, this distinction has a very practical consequence. You do not have the headcount for a QA team, and you do not have the runway to absorb a compliance incident. Formal verification becomes a force multiplier that lets a small team ship with the confidence of a much larger one.
What are the two layers of protection in Amazon Bedrock?
AWS provides AR at two layers, and they map cleanly to the maturity curve of most AI startups. When you are early-stage, your product is likely a chatbot or assistant: an LLM answering customer questions, generating recommendations, or providing guidance. At this stage, automated reasoning in Amazon Bedrock Guardrails verifies the content of model outputs against defined business rules
As you grow, you start building agentic workflows: your AI books appointments, processes refunds, queries databases, calls external APIs. At this layer, Policy in Amazon Bedrock AgentCore governs what actions an agent is allowed to take, using Cedar policies enforced at the gateway before any tool execution.
Cedar policies govern what an agent can do. But you can also expose the AR checks API as a tool in the agent's toolkit, letting the agent validate its own intermediate conclusions before acting on them. The agent calls ApplyGuardrail against your policy, inspects the findings, and self-corrects without involving the user. An agent planning a multi-step workflow can check whether its proposed sequence violates any constraint, catch a contradiction in its assumptions, or confirm that a derived value actually follows from the inputs. This shifts AR from a boundary check to a reasoning partner: the agent does not just get blocked at the gate, it avoids walking toward the gate in the first place.
Here is how they compare:
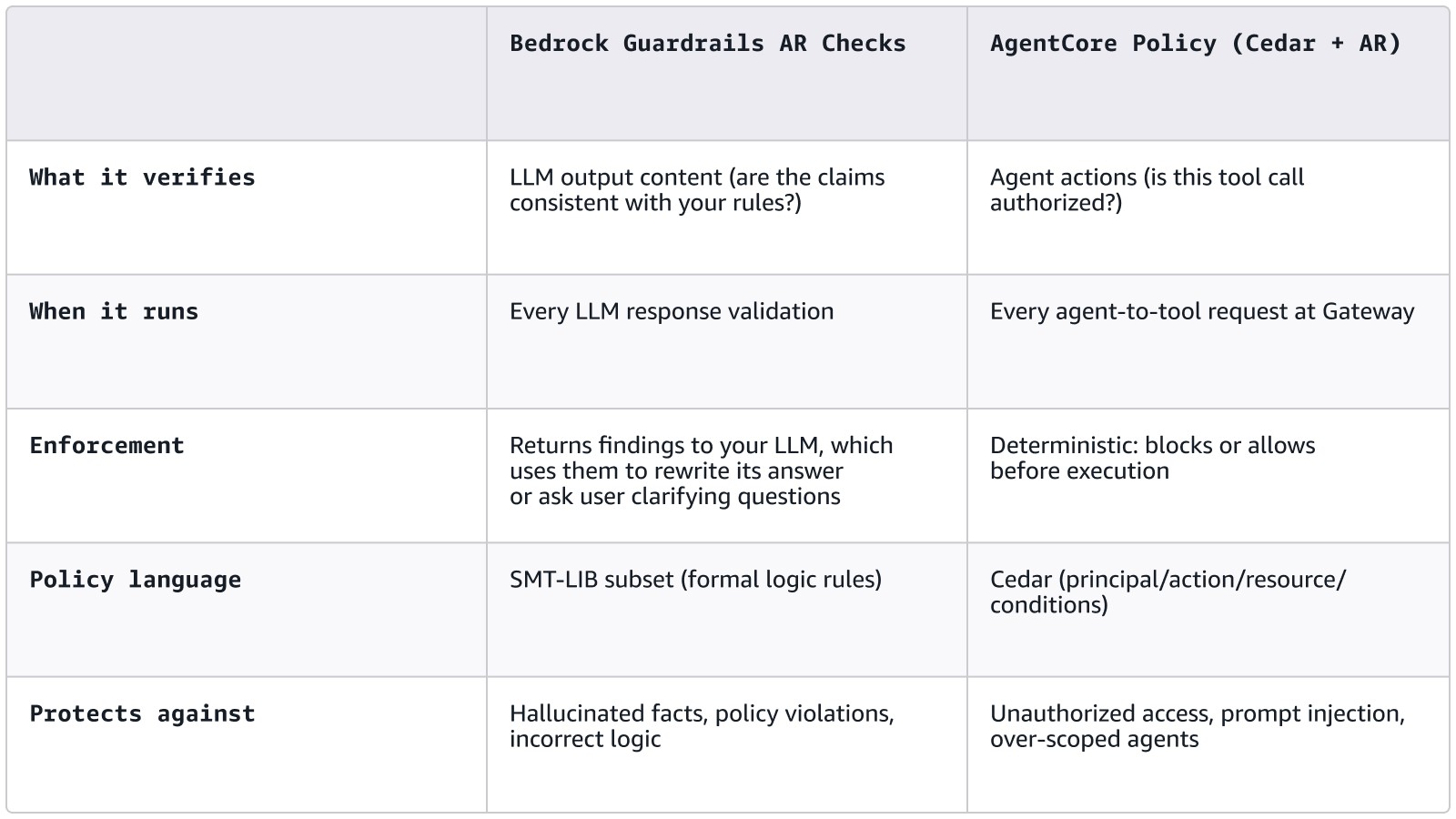
AR checks and Policy in Amazon Bedrock AgentCore protect different layers of your application.
- AR checks validate what your AI says, i.e. is this mortgage eligibility answer correct per your lending criteria?
- Policy in Amazon Bedrock AgentCore controls what your AI does, i.e. is this agent authorized to initiate a refund or query a customer's account?
Depending on what you are building today, you might start with one or both.
- If your MVP is a chatbot answering policy questions, AR checks is your first integration.
- If you are shipping an agent that books appointments and moves money, Policy is non-negotiable from day one.
Most startups will eventually run both together.
How AR checks work: Encoding your business rules as formal logic
The input to AR is a policy, and a policy starts with documents you already have.
If you are a fintech startup, it could be a lending criteria document. In healthcare, it may be clinical protocols or HIPAA handling procedures. In insurance, underwriting guidelines. These documents define what your AI should and should not say. They have been reviewed by your legal counsel. Your investors asked about them during due diligence. AR turns those existing artifacts into enforceable rules. You are not building something new from scratch. You are activating something you already have.
When you upload a policy document (PDF, Markdown, or plain text) to Amazon Bedrock, the system extracts two things: variables and rules.
Variables represent the concepts in your domain. Each variable has a name, a type, and a description. For example, in a mortgage eligibility policy:
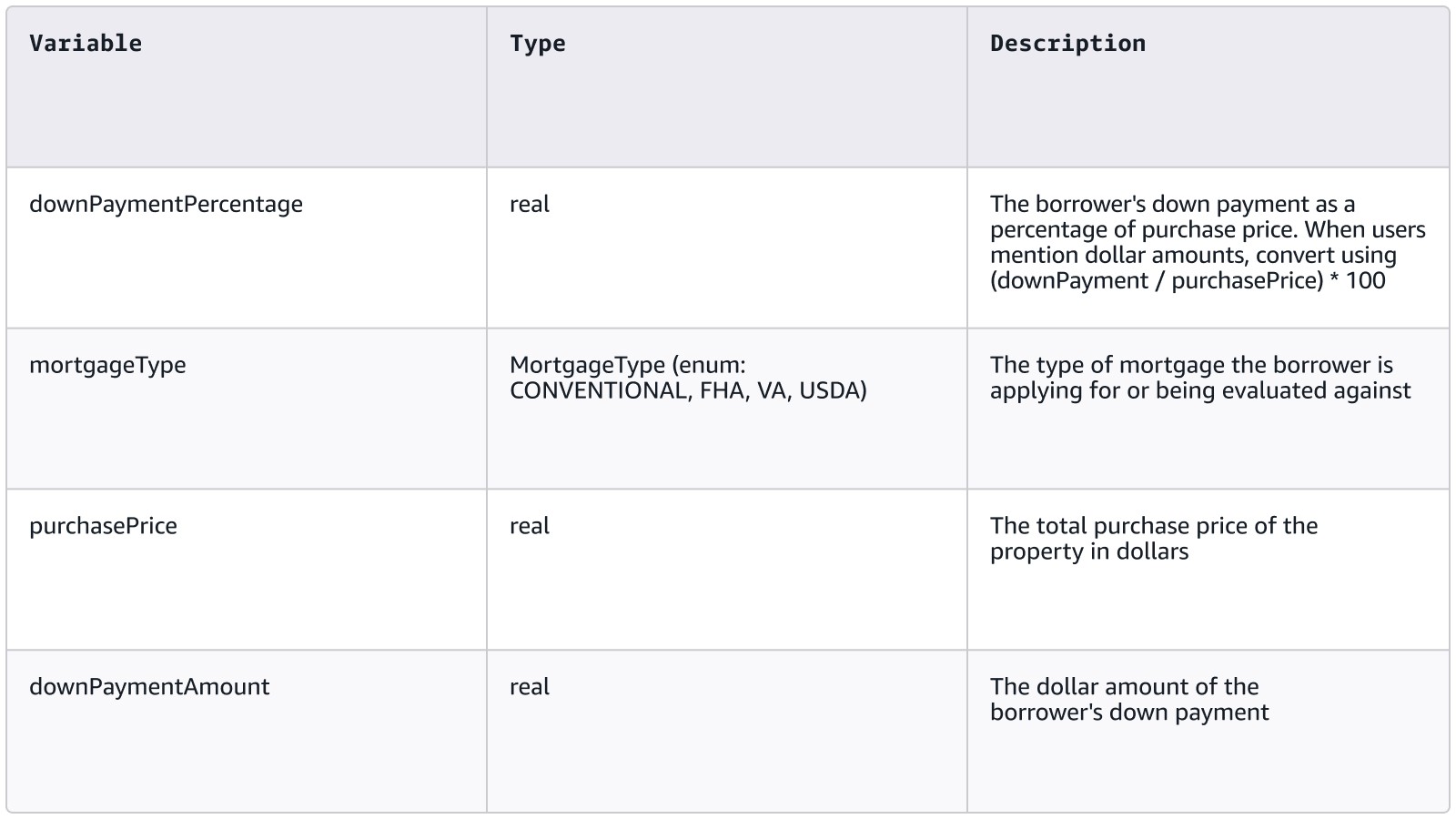
The variable descriptions are the single most important factor in accuracy. Vague descriptions leave the LLM guessing at what a variable represents. Detailed descriptions that explain what the concept means, how your users refer to it, and how it appears in your policy documents give the LLM the context it needs to map natural language to the right formal variables. This is where your domain expertise as a startup builder matters most.
Rules are formal logic expressions that capture relationships between variables. They use a subset of SMT-LIB syntax, and most follow an if-then (implicative) format:
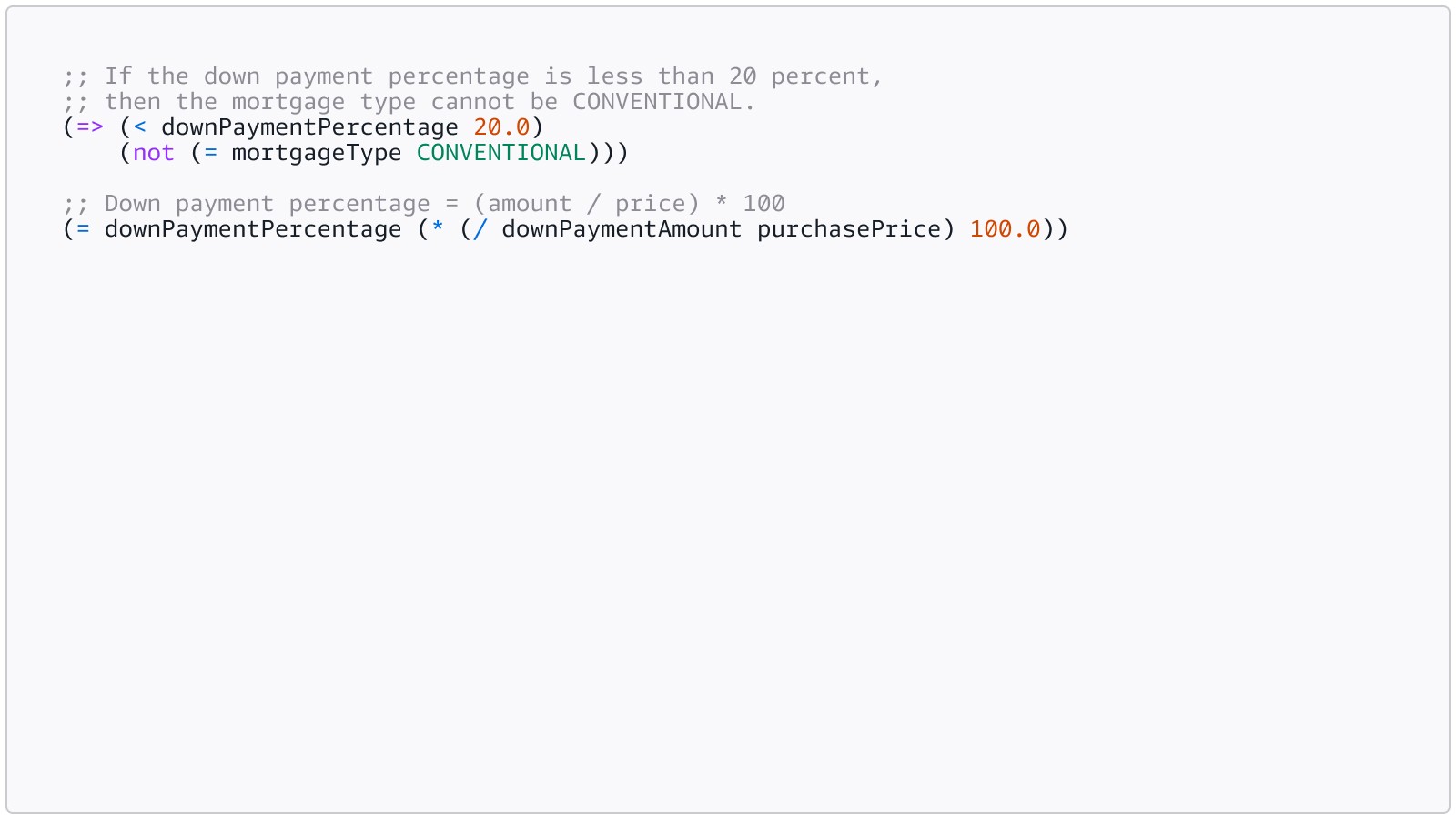
This is what Bedrock generates under the hood when you upload your mortgage policy document. You can review these rules in the console to verify the system captured your intent correctly, but you are not writing SMT-LIB by hand. You write the policy in natural language, and the system translates it into formal logic.
The two-step verification process
Once you have set up an AR policy and attached it to a guardrail (covered in Part 3), every LLM response your application sends to ApplyGuardrail goes through a two-step verification process. Understanding this split is critical because it tells you where to invest your effort.
Step 1: Translation
The system converts the natural language in both the user question and the LLM's response into formal logic predicates, statements like earning “>= 180 & earning <= 220” rather than simple assignments, using the variables declared in your policy. This is where the variable descriptions come in.
For example, if the response says "a customer with $30,000 USD down on a $350,000 USD house qualifies for a conventional mortgage," the translation step produces: downPaymentAmount = 30000, purchasePrice = 350000, mortgageType = CONVENTIONAL.
The fact that we use LLMs to translate your input natural language into logic is why the system claims up to 99 percent verification accuracy. To ensure our translation is correct, we don't just rely on one LLM. Instead, we use multiple LLMs at different temperatures in parallel to perform the same translation. Only when the redundant translations are semantically equivalent can we make a validation result. When the translations disagree, we instead return an AMBIGUOUS result that includes two possible interpretations of the input. Your LLM can use this feedback to disambiguate its answer or ask the user clarifying questions. When we benchmarked our system against Carnegie Mellon's conditional QA data set, in over 99 percent of cases where an answer was flagged as VALID from our system the flag was correct. You can find more details on the methodology in this paper.
Step 2: Verification
An Satisfiability Modulo Theories (SMT) solver evaluates whether the translated assignments satisfy all your policy rules. This step is mathematically sound by definition. Once the translation is correct, the verification is provably correct.
For the mortgage example: the solver computes downPaymentPercentage = (30000 / 350000) * 100 = 8.57 percent, checks this against the rule (=> (< downPaymentPercentage 20.0) (not (= mortgageType CONVENTIONAL))), finds that 8.57 < 20, and concludes that mortgageType = CONVENTIONAL is logically invalid. The system returns an invalid finding with a complete trace showing exactly which rule was violated and why.
The practical takeaway for startup builders? The translation quality is something you control through better variable descriptions. The verification math is something you do not have to worry about. You invest in describing your domain well, and the solver handles the rest.
What do the findings mean?
AR checks do not simply return "pass" or "fail." They return structured findings that tell you exactly what happened and what to do next. Each finding is one of these types:
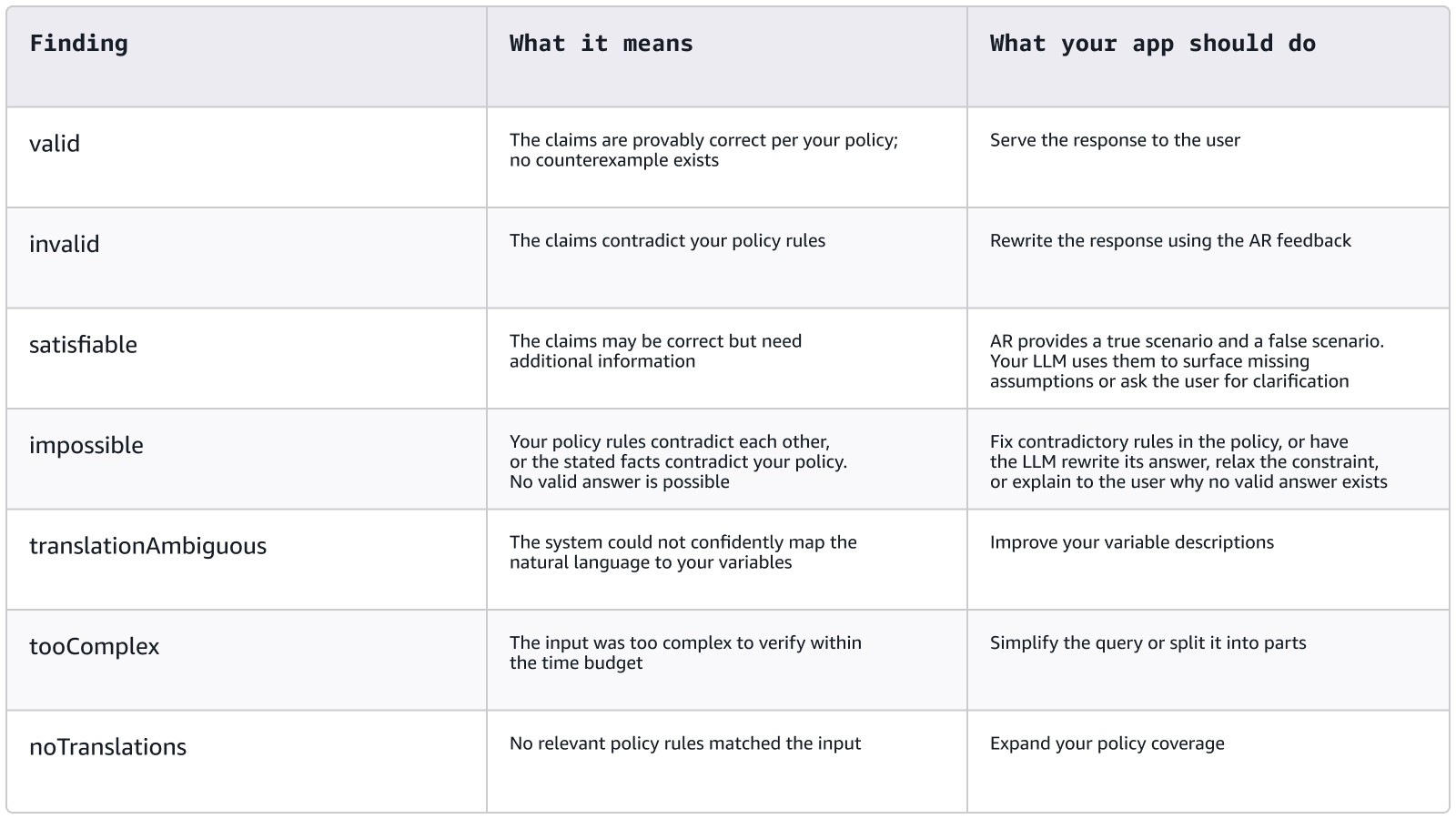
This is important: AR checks operate in detect mode. They return findings and feedback, but do not block the response. Your application inspects the findings and decides what to do: serve it, rewrite it, ask for clarification, or fall back to a safe default. This gives you full control over the user experience while getting mathematical verification on every response. For a working example of this pattern, see the open source rewriting chatbot implementation, which demonstrates how to take AR findings and feed them back to the LLM for automated correction.
AgentCore Policy: Deterministic boundaries for AI agents
If your startup is building agentic applications, where your AI orchestrates multi-step workflows, calls tools, and takes actions on behalf of users, you have a different trust problem. It is not just about what the AI says. It is about what the AI does.
For startups in healthcare, fintech, or legal, "the agent did something unexpected" is not acceptable from a compliance or regulatory perspective. You need provable boundaries on agent behavior, and those boundaries need to hold even when the agent is manipulated by prompt injection or makes a reasoning error.
Policy in Amazon Bedrock AgentCore solves this with an authorization layer enforced on every agent-tool interaction at the gateway boundary. Policies are written in Cedar, the authorization language built by AWS to be verified with AR. Cedar policies define who (principal) can do what (action) on which resource, under what conditions. No tool invocation passes through the gateway without a matching permit. You can write policies directly in Cedar or describe your rules in natural language and let the system generate Cedar for you.
Before your policies are deployed, automated reasoning runs semantic validation to catch problems, including:
- Overly permissive policies that would allow all requests for a given principal/action/resource combination
- Overly restrictive policies that would deny everything
- Ineffective policies where a Permit permits nothing or a Forbid forbids nothing
The enforcement follows two principles that are particularly important for startups in regulated industries:
- Default-deny: if no policy explicitly permits an action, it is blocked. Your agent cannot do anything you did not authorize.
- Forbid always wins over permit: you can set hard-stop rules that cannot be overridden, regardless of what other policies exist.
Consider a healthcare startup building an appointment scheduling agent. With AgentCore Policy, you can enforce that patients only access their own records, that appointment bookings are restricted to business hours, and that refund amounts are capped by policy. These rules hold regardless of how the agent is prompted, any bugs that exist in your code, or how creative the user gets with their requests. The enforcement happens at the gateway boundary, outside the agent entirely.
How much does automated reasoning cost compared to manual QA?
To understand the economics of automated reasoning, it is useful to compare it against the baseline most teams currently use: manual QA review of model outputs.
The old way: Manual QA
A reviewer checking AI outputs can handle roughly 50 interactions per hour at a loaded cost of about $40 USD/hour. For a startup handling 100,000 customer interactions monthly, reviewing every interaction costs $80,000 USD/month. Even sampling 10 percent costs $8,000 USD/month, and you are still unverified on the other 90 percent. At $80K to $150K USD per reviewer annually, a team of 5 to 10 reviewers runs $400K to $1.5M USD per year. For most startups, that is a significant chunk of funding spent on checking whether your AI is correct.
The new way: automated reasoning
AR checks are priced per validation request. (Exact pricing should be confirmed on the Bedrock pricing page as rates may vary.) Unlike manual review, every interaction can be verified rather than sampled. Amazon Bedrock Guardrails uses text units as the validation unit, where each text unit is 1,000 characters. Here is what that looks like for a typical startup:
Assumptions
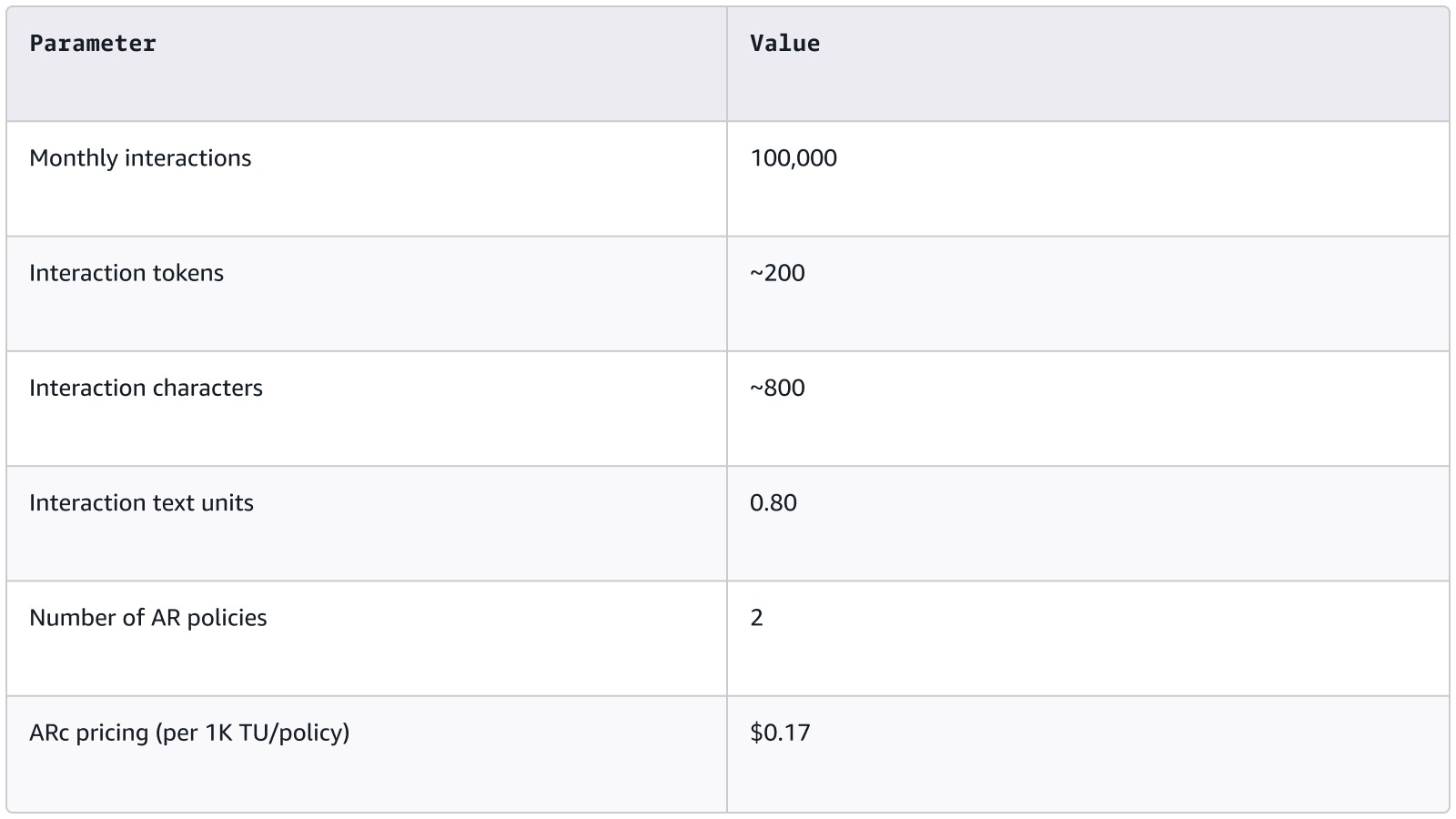
Calculation
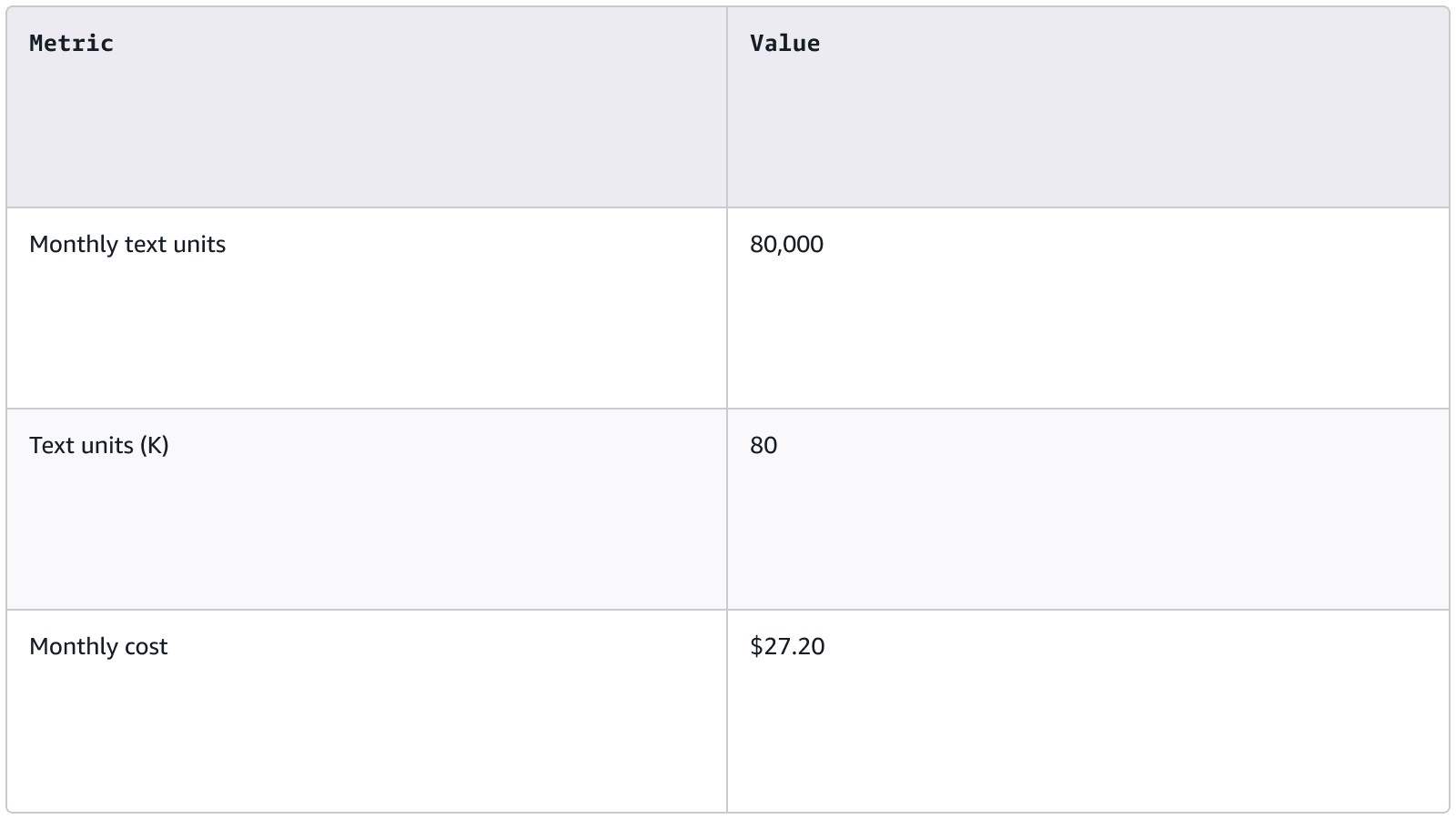
Using the example above of a startup handling 100K interactions per month, and assuming that the output of each interaction is ~200 tokens, we can easily estimate the cost of using AR checks for validation. Amazon Bedrock Guardrails measures usage in Text Units, where one text unit is 1000 characters. Using an average of 4 characters per token, we estimate each interaction to be ~800 characters and therefore 0.8 text units.
Validation of 100,000 interactions of 0.8 text units each gives us a total of 80K text units per month. With AR checks price of $0.17 per 1000 text units, our total monthly cost for a single policy would be $13.60 USD. With multiple policies applied, costs scale linearly. Even with multiple policies, the total cost remains dramatically lower than manual review.
The compliance math is even more compelling. A single HIPAA violation category can cost up to $2,067,813 USD per year under current inflation-adjusted figures. For a healthcare startup whose AI processes thousands of patient interactions daily, the regulatory exposure from unverified outputs is existential. In this context, AR functions less like a software expense and more like a risk management control.
For developers, the closest analogy is Rust's borrow checker. Rust catches memory corruption at compile time, before code reaches production. AR catches policy violations at verification time, before they reach your customer. Catching errors before they cause damage is always cheaper than cleaning up afterward.
There is a trade-off: AR validation adds latency to each response, and rewriting means your LLM runs twice on flagged outputs. For most applications, however, those costs are trivial next to the operational, legal, or reputational impact of an incorrect output.
The same argument resonates with investors. Being able to say that AI outputs are systematically verified against formal business policies is not simply a product feature. It is proof that risk is being managed proactively. That is the kind of concrete, verifiable claim that strengthens a startup’s risk profile.
What comes next?
In Part 3: A Step-by-Step Implementation Playbook, we go from concepts to code. You will learn how to create an AR policy from your existing documents, deploy it to a guardrail, integrate with the ApplyGuardrail API, handle findings programmatically, set up AgentCore Policy through AgentCore Gateway, and build an audit trail. Everything you need to go from reading about mathematical verification to shipping it in production.
.jpg)
Harshvardhan Chunawala
Harshvardhan Chunawala は、米国を拠点とする AWS の Solutions Architect であり、AWS Academy Authorized Educator でもあります。世界中の大企業のリーダー、スタートアップの創業者、C スイートのエグゼクティブと連携し、業界を問わず、AWS 上でスケーラブルかつセキュアなクラウドインフラストラクチャを設計しています。同氏は、AWS Golden Jacket の受賞者であり、複数の Amazon チームと協力し、セキュリティ、衛星、信頼性の高いエージェンティック AI サービスの領域で、最先端のクラウド機能の構築と提供に取り組んでいます。AWS での仕事以外では、10 年を超える経験を持つクラウドセキュリティの分野で世界的に認められたテクノロジスト兼エキスパートです。また、Carnegie Mellon University と連携しており、クラウドコンピューティングと新興テクノロジーの研究および指導に貢献しています。仕事以外では、スカイダイビングと飛行機の操縦を楽しんでいます。

Mike Miller
Mike Miller は、AWS の Director of AI Product Management であり、ハルシネーションを防ぐための自動推論機能、Amazon Q、Amazon Bedrock など、主要な生成 AI イニシアティブについて助言しています。同氏は、生成 AI アプリケーションを構築するためのノーコードプレイグラウンドである PartyRock の社内版が Amazon の従業員の間で爆発的に人気を博した後、これを一般公開しました。Mike は以前、AWS Machine Learning Thought Leadership チームを率い、AWS DeepLens、AWS DeepRacer、AWS DeepComposer を立ち上げ、世界中のデベロッパーが楽しく魅力的な方法で実践的な機械学習を体験できるようにしました。Mike は 13 年を超える期間にわたって Amazon に在籍しており、AWS に入社する前は Lab126 で Fire TV のプロダクトマネジメントを率いていました。

Rahul Kumar
Rahul Kumar 博士は AWS の Senior Applied Science Manager であり、Rust および C プログラムの検証テクノロジーの構築と、大規模言語モデルと自動推論を組み合わせたニューロシンボリック AI の発展に取り組んでいます。AWS では、Kani モデルチェッカーや「Verify the Safety of the Rust Standard Library」チャレンジなど、オープンソースイニシアティブを推進しています。Brigham Young University で PhD を取得し、以前は Microsoft Research や NASA JPL で形式検証と静的解析に取り組んでいたほか、カリフォルニア工科大学では講師を務めていました。自動推論をより多くの人々が利用できるようにすることに情熱を注いでおり、数学的証明手法が AI のハルシネーションをなくし、ソフトウェアの正当性を保証する方法について講演を行っています。同氏は、ワシントン州シアトルを拠点としています。

Stefano Buliani
Stefano Buliani は、AWS の Automated Reasoning Group の Principal Product Manager であり、Amazon Bedrock ガードレールを通じて生成 AI に形式検証機能を導入する取り組みを主導しています。ソフトウェアエンジニアとしての経歴を持つ Stefano は、AWS に 12 年を超える期間にわたって在籍しており、サーバーレスおよび自動推論チームにおいて、Specialist Solutions Architect および Product Manager の両方を務めてきました。同氏は以前の役割において、AWS Lambda と Amazon API Gateway 上でサーバーレスアプリケーションを構築およびスケールするお客様をサポートしていました。仕事以外では、太平洋岸北西部でアウトドアアクティビティを楽しんでいます。同氏はカナダのバンクーバーを拠点としています。
このコンテンツはいかがでしたか?