このコンテンツはいかがでしたか?
- 学ぶ
- スケールする AI エージェントを構築する: スタートアップのためのシステム指向リファレンスアーキテクチャ
スケールする AI エージェントを構築する: スタートアップのためのシステム指向リファレンスアーキテクチャ

ビルダーは世代ごとに抽象化の転換期を迎えます。アセンブリ言語はより高水準の言語に移行しました。モノリスは分散システムに進化しました。オンプレミスインフラストラクチャはクラウドネイティブプラットフォームに道を譲りました。そして今、ソフトウェア自体が AI ネイティブになりつつあり、モデル、コンテキスト、エージェント、適応型ワークフローによって形作られています。
re:Invent 2025 で、ワーナー ヴォゲルスはこの状況を明確に指摘しました。成功するデベロッパーはシステム思考で、精密に構築します。勝利を収める企業は、AI をいち早く導入した企業でも、最も優れたモデルを選んだ企業でもなく、システム全体を俯瞰的に捉え、アーキテクチャに関するあらゆる決定が上下のレイヤーに波及することを理解している企業です。
現代の AI スタックは、モデルの選択、データ取得のアタッチ、オーケストレーションの追加、デプロイを選択する点において、チェックリストとして扱われることがあまりにも多いです。AI を利用した製品は、コンポーネントが単体で見栄えが良いだけでは失敗します。成功するのは、システムが実際の負荷の下で予測可能な動作をし、速度、信頼性、ガバナンス、コストのバランスが取れているときです。
Peter DeSantis は、re:Invent 2025 でインフラストラクチャの観点からこの主張を展開しました。AWS が 20 年間こだわり続けてきた 5 つの基本要素、すなわち、セキュリティ、可用性、伸縮性、俊敏性、コストは、今やより重要になってきています。AI ワークロードは、あらゆるアーキテクチャ上の弱点を増幅させます。100 名のユーザーでスケールするシステムでも、10,000 名のユーザーでは構造的に破綻する可能性があります。プロトタイプ段階では妥当に見えるコストモデルも、本番ボリュームでは維持不能になる可能性があります。また、善意に基づいて構築されたガバナンスアプローチは、企業のセキュリティレビューに耐えられません。
この記事では、プロトタイプから本番への移行を目指すモデルビルダーと AI ネイティブ SaaS チーム向けに、システム指向リファレンスアーキテクチャを概説します。このアーキテクチャは、連携することで最大限の価値を発揮する 5 つのレイヤーで構成されています。
サービスだけでなく、システムで考える
生成 AI の設計におけるよくある間違いは、あるチームは「最適な」モデルを選択し、別のチームは「最適な」ベクトルストアを選択し、さらに別のチームは使い慣れたオーケストレーションフレームワークを選択するというように、各レイヤーを個別に最適化することです。個々の決定は単独では合理的に見えるかもしれませんが、ユーザーが体験するのはシステム全体の動作、すなわち、検索速度、応答の質、ワークフローの耐久性、ポリシーの強制適用、テナントの分離、サービス提供コストです。
AI ネイティブソフトウェアでは、これらの結果はレイヤー間の相互作用から生じます。すなわち、ID と許可が検索とツールアクセスにどのように反映されるか、コンテキストの鮮度が出力の質にどのように影響するか、オーケストレーションが、再試行、状態、および長時間実行されるステップをどのように処理するか、オブザーバビリティが、モデル呼び出し、ワークフロー、およびアプリケーションロジックにどのように及ぶか、ストレージ、推論、およびワークフロー実行全体でコストがどのように累積するか、といったことが重要となります。
極めて優れた AI スタックとは、個々のコンポーネントが極めて優れているスタックではありません。フィードバックループによって、信頼性が高く、予測可能なシステム動作を生み出すスタックです。このような視点から、AWS 上で AI ネイティブな現代のスタートアップ向けに、実践的なリファレンスアーキテクチャをご紹介します。
レイヤー 1: データとコンテキストの基盤
あらゆる AI 製品はデータ基盤の上に構築されています。このレイヤーは、製品が AI の動作を、統制された耐久性があるコンテキストに基づかせることができるかどうかを決定づけます。本番システムでは、コンテキストが、検索の質、モデル動作、パーソナライゼーション、信頼性を左右します。このレイヤーが脆弱であったり、古くなっていたり、統制が不十分であったりすると、不安定性が上位レイヤーに波及します。
実際には、4 つの障害モードがよく見られます:
- 信頼できる情報源となるデータは、いかなるモデルや検索戦略よりも長く存続する必要があります。データアーキテクチャを特定の埋め込みモデルに過度に依存させているチームは、多くの場合、モデルやアクセスパターンが変更されるたびに基盤を再構築しています。
- コンテキストは、迅速かつ適切なアクセスのために整理されている必要があります。検索レイテンシーは製品品質の問題であり、上位のすべてのレイヤーに影響が波及します。
- 正確性を高める同じコンテキストも、古くなっていたり、過剰に共有されていたり、テナント間で適切に分離されていなかったりすると、リスクを生み出す可能性があります。コンプライアンスだけでなく、正確性と信頼性を確保するためには、統制された境界が不可欠です。
- 長期保存される非構造化データ、ベクトル埋め込み、および運用状態はそれぞれ異なる目的を持ち、たとえ近接して存在する場合でも、アーキテクチャ上は明確に区別されるべきです。
Amazon Simple Storage Service (Amazon S3) は、ドキュメント、トランスクリプト、アーティファクト、およびログの標準的な記録システムであり続けています。S3 Vectors は、この基盤を数十億ベクトル規模のネイティブベクトルストレージに拡張し、S3 の伸縮性、耐久性、可用性モデルを維持します。ナレッジ集約型製品を構築する ISV にとって、規制コンテンツ、顧客とのやり取りの履歴、およびそれらを検索可能にする埋め込みは、同じバケット内で同じアクセスポリシーの下で管理できます。別途ベクトルデータベースをプロビジョニング、スケーリング、および保護する必要はありません。
従来、個別のベクトルデータベースを管理していたチームは、プロビジョニング、インデックスの状態のモニタリング、スケーリングイベントの計画を、インフラストラクチャの他の部分とは別に行っていました。S3 Vectors は、これらを完全に排除します。ドキュメントストアを既に統制しているのと同じアクセスポリシーを継承するため、個別のスケーリング戦略、追加の認証情報管理、モニタリングすべき新たな障害が発生し得る場所はありません。
専用のベクトルストアにも依然として役割があります。OpenSearch は、アプリケーションが正確なキーワードマッチングと意味論的関連性を組み合わせる必要がある場合、または低レイテンシーで検索パフォーマンスを最適化する必要がある場合に適しています。Amazon Nova マルチモーダル埋め込みは、データが純粋なテキストではない場合に重要になります。スキャンされた PDF と構造化レコードを処理する契約インテリジェンスプラットフォームや、動画とトランスクリプトをインデックス化するメディアプラットフォームは、断片化されたパイプラインではなく、共有ベクトル空間から恩恵を享受できます。
主要なサービス: Amazon S3、Amazon S3 Vectors、Amazon OpenSearch Service (GPU アクセラレーテッド)、Amazon Nova マルチモーダル埋め込み、Amazon Bedrock ナレッジベース。
開始点: ソースドキュメントを、プレフィックスベースのテナント分離を使用して S3 に最初から保存し、カスタム検索ロジックを構築する前に、そのバケットに対して Bedrock ナレッジベースを設定します。
レイヤー 2: モデルとサービス提供
このレイヤーは、システムがどのようにインテリジェンスを生成するか、およびそのコストを決定します。重要なのは、どのモデルが最も高性能かではなく、各ワークロードタイプにおいて、精度、レイテンシー、コスト、コントロールの適切なバランスを実現するモデル戦略はどれか、という点です。
ドメイン固有のビルダー (リーガルテック、コーディングアシスタント、金融文書分類ツール) は、汎用的なフロンティアモデルでは一貫して実現できない、あるいは経済的に維持できない独自の精度を必要とします。現代の ISV は、クエリ量が増えても、予測可能なレイテンシーとコストを必要とします。また、推論コンシューマーは、ルーティング、要約、エンティティ抽出といったルーチンタスクにおいて、より小型のチューニング済みモデルが同等のパフォーマンスをはるかに低いコストで実現できる場合、フロンティアモデルの料金を支払うことを避けるべきです。
ほとんどのチームにとって、Amazon Bedrock は適切な開始点です。これは、Anthropic のフロンティアモデルに加え、18 以上のオープンウェイトモデルのマネージドラインナップを提供します。また、Nova 2 はコストパフォーマンスに極めて優れており、推論インフラストラクチャを実行する運用上の負担もありません。製品が成熟するにつれて、適切な問いは、「どのモデルが最適か?」から「当社の競争優位性は、独自のモデル動作と独自製品のワークフローのどちらからどれだけ得られているか?」に変化します。Bedrock Reinforcement Fine-Tuning (RFT) は、ドメイン固有のタスクにおいて基本モデルよりも精度を高めることができ、より小さく、より高速で、よりコスト効率の高いバリアントを、本番レベルのボリュームで実用化できるようにすることを可能にします。
より詳細なコントロールが必要なチーム向けに、Amazon SageMaker AI は、ファインチューニング、評価、MLOps、カスタムデプロイにより深く踏み込む必要があるビルダー向けの、マネージド型でありながら制御された階層です。また、独自のモデル動作が製品自体の一部である場合にも適しています。音声ネイティブエクスペリエンスのための双方向ストリーミングなど、フルマネージドサーフェスでは公開されていないランタイムパターンが必要なチームは、SageMaker の方がより実用的な選択肢となるでしょう。音声を継続的に入力しながら、逐次の文字起こしを出力することにより、インタラクションはレイテンシーに縛られることなくスムーズになります。
ゼロから基盤モデルを構築するチーム向けには、EC2 Trn3 (Trainium3) が 40% 低いトレーニングコストと、5 倍のメガワットあたりの出力トークンに加えて、ネイティブ PyTorch 統合を提供することで、チームは、モデルコードを変更することなく、トレーニングおよびデプロイできます。Amazon Elastic Kubernetes Service (EKS) は、完全なランタイムコントロールや特殊なサービングスタックを必要とするチーム向けの、最も自由度の高いソリューションです。
モデル階層の決定がシステムのコストの下限を決定します。あらゆるリクエストがデフォルトでフロンティアモデルに設定されると、データ取得、エージェント、複数ステップのワークフローが追加されるにつれてコストが急速に上昇します。規律あるモデル戦略により、タスク要件に合わせて機能を維持し、モデルコストが製品の経済性をいつの間にか上回るのを防ぎます。
Bedrock の料金ページでは、入力トークンと出力トークンごとのモデルごとの最新のコスト比較を提供しています。アーキテクチャを最終決定する前に、想定されるリクエスト量に対してこれらの計算を実行することは有益です。
主要なサービス: Amazon Bedrock (サーバーレス推論、サービス階層)、Amazon Nova 2 ファミリー、Bedrock RFT、SageMaker AI、EC2 Trn3 (Trainium3)。
開始点: ワークロードのうち、どのワークロードにフロンティアモデルが必要で、どのワークロードがより小規模または低コストの代替モデルで処理できるかを特定してください。規模が大きくなるにつれてコスト差は急速に拡大します。
レイヤー 3: 推論とエージェンティックランタイム
推論は、アーキテクチャに関する意図が、ユーザーに見える動作となる段階です。このレイヤーは、レイテンシー、スループット、同時実行、セッション状態、ツールのインタラクションパターン、バースト的な需要下での質、顧客とのやり取りあたりのコストを統制します。課題は機能ではなく、実際の条件、すなわち、複数のテナント、バースト的な需要、失敗する可能性のあるツール呼び出し、ミリ秒ではなく数分かかるワークフローにおける信頼性、分離性、コストの一貫性です。
これは、現代の ISV がエンタープライズ向けに販売できるか、それともアーリーアダプター向けにしか販売できないかを決定づけるレイヤーです。優れたモデルパフォーマンスを備えていても、テナント分離、ワークフローの耐久性、監査可能なツール呼び出し履歴がないエージェンティックアプリケーションは、技術的に間違っているからではなく、システムレベルで信頼できないため、調達審査に不合格となります。
Bedrock の基盤となる推論エンジンである Project Mantle は、インフラストラクチャレベルでの信頼性と分離に対応しています。サービス階層ルーティングにより、契約インテリジェンスプラットフォームは、ユーザー向けの条項抽出を優先レーンに、バックグラウンドでの規制関連相互参照を柔軟なレーンに、それぞれルーティングすることで、ユーザーエクスペリエンスを損なうことなく、コストを最適化できます。顧客ごとのキュー分離により、あるテナントのドキュメントアップロードでバーストが生じても、他のテナントのアクティブなレビューセッションには影響しません。Mantle の重要なイノベーションである Journal は、推論状態を継続的にチェックポイントとして保存するため、12 分経過後に失敗した長時間のデューデリジェンスワークフローは、最初からではなく、12 分経過時点から再開されます。
Amazon Bedrock AgentCore は、本来であればほとんどのチームが構築に数か月を費やすであろう本番ランタイムを提供します。任意のフレームワーク (LangGraph、CrewAI、Strands Agents、OpenAI Agents SDK) へのコンテナ化されたエージェントのデプロイ、セッションをまたいだエピソード記憶、MCP ベースのツールアクセスと Cedar ポリシーの強制適用、およびライブエバリュエーターに照らした継続的な質の評価が含まれます。独自のエージェントインフラストラクチャを運用するリーガル SaaS チームは通常、コンテナ化、セッション処理、およびツールのセキュリティを管理するために複数のエンジニアを必要とします。AgentCore は、これらの懸念事項をマネージドレイヤーに統合し、エンジニアのキャパシティを、取引の獲得につながる条項ライブラリ、リスク分類、およびクライアント固有のポリシールールに振り向けられるようにします。
エンタープライズセールスサイクルにおいてこのレイヤーの成否を分ける原則は、メカニズムと善意の区別です:
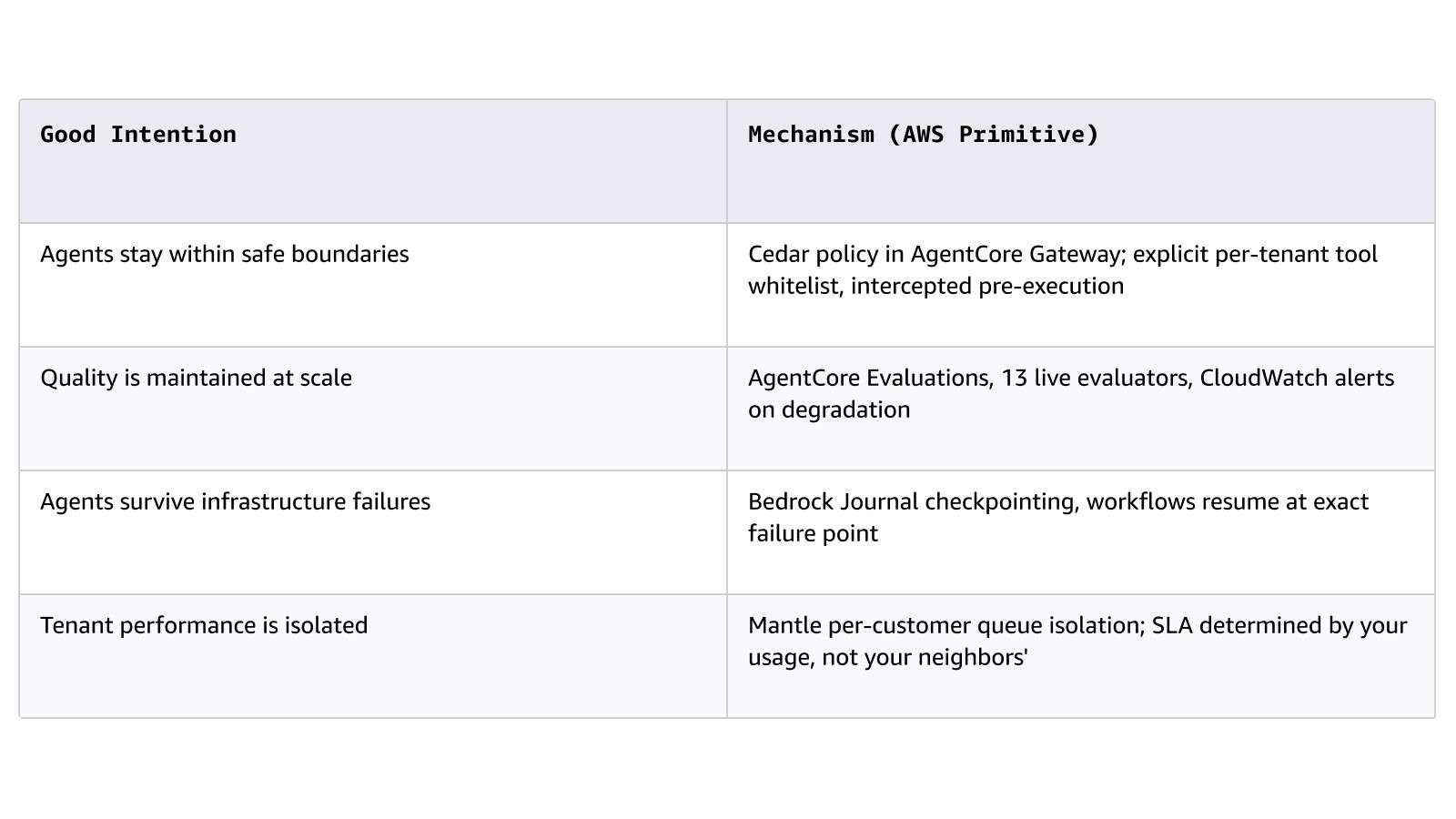
主要なサービス: Amazon Bedrock (Project Mantle: サービス階層、キュー分離、Journal)、AgentCore (ランタイム、メモリ、ゲートウェイ、評価、ID)、Strands Agents、AWS Step Functions、Amazon Simple Queue Service (SQS)。
開始点: エージェントが満たす必要がある企業要件を挙げ、それぞれを、プロンプト戦略ではなく、具体的なメカニズムにマッピングします。
レイヤー 4: オーケストレーションとコンピューティング
これは、AI が単一のモデル呼び出しであることをやめ、ソフトウェアとなるレイヤーです。ほとんどの本番 AI 製品は、コンテキストの取得、モデルの呼び出し、ツールの呼び出し、出力の検証、下流アクションのトリガー、結果の永続化、ワークフローの非同期的な再開を行う複数ステップのシステムです。オーケストレーションは、実装の詳細ではなく、コアアプリケーションアーキテクチャの一部です。
契約の分析を実行する金融サービス SaaS プラットフォームについて考えてみましょう。単一のリクエストには、ドキュメントの取り込み、チャンキング、埋め込み生成、過去の契約を対象とする検索、条項に対する複数ステップの推論、人間のレビュー担当者へのルーティング、下流のコンプライアンスワークフローのトリガーが含まれる可能性があります。これは、単一の推論呼び出しではなく、数分から数時間にわたる、分岐ロジック、リトライ、状態遷移、非同期ステップを含む、耐久性のあるアプリケーションワークフローです。
ここでの構造的なインサイトは、サーバーレスコンピューティングを革新的なものとした理由を反映しています。目標は、インフラストラクチャの管理を容易にすることではなく、インフラストラクチャ管理のカテゴリ全体を排除することです。Lambda マネージドインスタンスは、この原則を一般的なギャップに適用します。一部のワークロードは、特定のコンピューティング特性、埋め込み生成のための大容量メモリ、ドキュメント前処理パイプライン、または CPU 負荷の高いモデル推論を必要としますが、これらはシンプルなサーバーレス関数では処理負荷が高すぎるものの、直接的なフリート管理を必要とするほどではありません。毎日数千の法的文書を処理するスタートアップは、特定のインスタンスプロファイル上でこれらの機能を実行でき、Lambda がプロビジョニング、スケーリング、パッチ適用を管理し、EC2 フリート運用を引き継ぐことなくサーバーレスアーキテクチャを維持します。
より詳細なランタイムコントロールを必要とするチーム向けに、EKS は、カスタム推論サーバーを実行するモデルビルダーや Kubernetes を標準化するプラットフォームチームが好む一貫性とコントロールを提供します。
Amazon DynamoDB は、ワークフローの状態、セッションメタデータ、テナント設定、べき等性キー、ツールの結果、監査参照のためのトランザクションコントロールプレーンとして自然に適合します。これは、作業がサービスやワークフローのステップをまたいで進行する際に、アプリケーションの一貫性を維持する運用基盤となります。これは、検索に使用されるセマンティックメモリレイヤーとは異なります。
AI を利用した開発環境である Kiro は、ソフトウェア提供アクセラレーターとしてこのレイヤーに適合します。その役割は、チームが自然言語の要件を、構造化された設計、仕様、実装タスクに変換できるように支援して、チームがシステムアーキテクチャの一貫性を維持しながら、作業速度を向上させることができるよにすることです。
主要なサービス: Lambda Managed Instances、Lambda Durable Functions、Amazon DynamoDB、Amazon EC2 M9g (Graviton5)、 AWS Step Functions、Amazon ECS on Graviton5、Amazon EventBridge、Amazon SQS。
開始点: オーケストレーションツールを選択する前に、ワークフローを紙に書き出し、失敗したり、分岐したり、非同期で実行されたりする可能性のあるすべてのステップを特定します。
レイヤー 5: ガバナンス、オブザーバビリティ、信頼
多くの AI スタックが依然として機能不全に陥っているのは、まさにこの部分です。チームはガバナンスを後から追加できるものとして捉えがちです。広範なツールアクセスを持ち、評価の厳密性が限られ、プロンプトに基づく制約が曖昧なエージェントは、信頼を損ない、導入の障壁となります。より良い原則とは何でしょうか。それは、意図ではなく、メカニズムです。
エンタープライズの購入者は、AI システムを導入する前に、ほぼ例外なく、次の 2 つの質問をします。すなわち、「データがテナント境界を決して越えないことを実証できますか?」、および「貴社が主張する境界内で AI が動作し、それらの境界を強制適用するメカニズムと、何が起こったのかを示すログを備えていることを証明できますか?」という質問です。
ヘルスケア ISV の場合、これは、患者の承認されたコンテキスト外のレコードにアクセスできない HIPAA 準拠のエージェントを意味します。金融サービス SaaS プロバイダーの場合、これは、クライアント固有のデータアクセス契約によってツール呼び出しが制約される投資調査アシスタントを意味します。これらは、規制対象となる企業デプロイにおける標準的な要件であり、例外的なケースではありません。
Bedrock Confidential Computing は、実行中のデータを保護し、より高次のランタイム境界を提供することで、推論プレーンにおけるデータ分離の問題に対処します。Bedrock、AgentCore、Lambda、S3 などのサービスは、統合 ID モデル内で動作できるため、各レイヤーのために個別の承認システムを構築することなく、データ、モデル呼び出し、エージェントツールの使用全体にわたってアクセスガバナンスを一貫して適用できます。データアクセスを規定するポリシーは、モデル呼び出しとツール許可も規定します。ツール呼び出しログは、システム動作の監査可能な記録となります。
また、このレイヤーのガバナンスには、テナントを考慮したデータコントロール、モデルとプロンプトのバージョニング、ツール呼び出しとワークフロー全体のトレーサビリティ、環境またはお客様ごとのコストの可視性、アプリケーション、ワークフロー、モデルレイヤー全体にわたるエンドツーエンドのオブザーバビリティも含まれます。これらは単なるアーキテクチャ上の贅沢ではありません。これらは、チームがシステム動作を推論し、適切なレイヤーでインシデントを調査して、生ログからイベントを再構築することなくコンプライアンスを実証することを可能にします。
EMEA で活動するチームにとって、規制関連の状況は、これらのアーキテクチャに関する意思決定のいくつかに影響を及ぼします。データレジデンシーに関する GDPR の要件は、テナント分離が単なるエンタープライズへの販売における要件ではなく、法的要件であることを意味します。S3 プレフィックスベースの分離とテナントごとの暗号化は、これを満たす実用的なメカニズムです。EU AI Act は、高リスク AI アプリケーションについての透明性と人間による監視に関するさらなる義務を課しており、監査ログ記録とツール呼び出しのトレーサビリティに直接対応しています。
Bedrock モデル、S3 Vectors、および AgentCore は、すべての AWS EMEA リージョンで同じように利用できるわけではないことに留意してください。チームは、特定のアーキテクチャを本格的に採用する前に、対象リージョンでの可用性を確認する必要があります。
また、スタートアップチームは、S3 Vectors や AgentCore など、上記で言及されているサービスの一部が、本番環境では比較的新しいものであることにも留意すべきです。コアインフラストラクチャとして本格的に採用する前に、特定のユースケースとリージョンにおける成熟度を検証してください。
主要なサービス: Amazon Bedrock (機密コンピューティング)、AWS Identity and Access Management (IAM)、Amazon CloudWatch、AgentCore Policy (Cedar)、AgentCore Evaluations、AWS Security Hub。
開始点: 監査ログで購入者やコンプライアンスオフィサーに何を証明する必要があるのかを明確にします。その後、そこから逆算して、備えておく必要がある必要なポリシーとツールを明らかにします。
システム全体の構成
ユーザーリクエストがアプリケーションに入力されます。ランタイムはリクエストを認証し、テナントコンテキストを解決します。関連するメモリと製品に関するナレッジはコンテキストレイヤーから取得されます。オーケストレーションレイヤーは、タスクがシンプルなモデルインタラクションなのか、または複数ステップのワークフローなのかを判断します。推論レイヤーは、次のステップを生成または推論します。ポリシーは、呼び出せるツールを制約します。長時間実行されるステップは、状態をチェックポイントとして保存し、障害発生時には適切に復旧します。システムは、各ステージにわたってテレメトリを出力します。評価とフィードバックループは、時間の経過に伴う質を測定します。製品チームは、これらのシグナルを使用して、プロンプトの改良、ポリシーの更新、検索の改善、またはより詳細なモデルカスタマイズが必要なタイミングを判断します。
これが実践的なシステム思考です。成功するアーキテクチャとは、データ、コンテキスト、推論、ワークフロー、ガバナンス、および運用を、企業がスケールするのに合わせて適切に動作する、一貫性のあるシステムに統合したものです。
ほとんどのスタートアップチームにとって、エントリーポイントはレイヤー 1 です。エージェントやオーケストレーションに取り組む前に、データ基盤とテナント分離を適切なものにしましょう。後続のレイヤーの信頼性は、それらの土台となる基盤に左右されます。
構築し、責任をもって運用しましょう。
適切に設計された AI スタックは、個々のサービスによってではなく、各レイヤーが連携して一貫性のあるシステムとして機能することで、市場投入までの時間を短縮し、信頼性や信用を強化し、コスト管理を改善します。スタックがシステム指向であれば、チームは、新しい機能が登場するたびにゼロから再構築することなく、ビジネスの成長に合わせてアーキテクチャを進化させることができます。
このコンテンツはいかがでしたか?