Comment a été ce contenu ?
- Apprendre
- Création d’agents d’IA pouvant être mis à l’échelle : une architecture de référence orientée systèmes pour les start-ups
Création d’agents d’IA pouvant être mis à l’échelle : une architecture de référence orientée systèmes pour les start-ups

Chaque génération de développeurs fait face à un changement d’abstraction. L’assembleur a cédé la place aux langages de plus haut niveau. Les monolithes sont devenus des systèmes distribués. L’infrastructure sur site a laissé place aux plateformes natives cloud. Aujourd’hui, le logiciel lui-même devient natif IA, façonné par les modèles, le contexte, les agents et les flux de travail adaptatifs.
À l’occasion de re:Invent 2025, Werner Vogels a clairement défini ce moment : les développeurs qui réussissent pensent en systèmes et construisent avec précision. Les entreprises gagnantes ne sont pas celles qui ont adopté l’IA le plus tôt ou choisi le modèle le plus performant. Ce sont celles qui pensent en systèmes complets, qui comprennent que chaque décision architecturale se répercute sur les couches supérieures et inférieures.
La pile d’IA moderne est trop souvent traitée comme une liste de contrôle : choisir un modèle, associer une récupération, ajouter l’orchestration, déployer. Les produits alimentés par l’IA échouent lorsque leurs composants semblent impressionnants isolément. Ils réussissent lorsque le système se comporte de manière prévisible sous une charge réelle, en équilibrant vitesse, fiabilité, gouvernance et coût.
Peter DeSantis a défendu cet argument du point de vue de l’infrastructure lors de re:Invent 2025. Les cinq fondamentaux sur lesquels AWS se concentre depuis vingt ans, à savoir la sécurité, la disponibilité, l’élasticité, l’agilité et les coûts, sont plus importants aujourd’hui, et non moins. Les charges de travail d’IA amplifient chaque faiblesse architecturale. Un système capable de passer à l’échelle pour 100 utilisateurs peut échouer structurellement à 10 000. Un modèle de coût qui semble raisonnable au stade du prototype peut devenir intenable au volume de production. Et une approche de gouvernance fondée sur de bonnes intentions ne peut pas survivre à un examen de sécurité d’entreprise.
Cet article présente une architecture de référence orientée systèmes destinée aux développeurs de modèles et aux équipes SaaS natives IA qui passent du prototype à la production. Elle comprend cinq couches qui livrent toute leur valeur lorsqu’elles fonctionnent ensemble.
Penser en systèmes, pas seulement en services
Une erreur courante dans la conception de l’IA générative consiste à optimiser chaque couche indépendamment. Une équipe choisit le « meilleur » modèle. Une autre choisit le « meilleur » magasin vectoriel. Une troisième choisit un cadre d’orchestration selon ses habitudes. Chaque décision peut sembler rationnelle isolément, mais les utilisateurs font l’expérience du comportement de l’ensemble du système : vitesse de récupération, qualité des réponses, durabilité des flux de travail, application des politiques, isolation des locataires et coût de service.
Dans les logiciels natifs IA, ces résultats découlent d’interactions entre les couches : comment l’identité et les autorisations s’appliquent à la récupération et à l’accès aux outils ; comment la fraîcheur du contexte façonne la qualité des sorties ; comment l’orchestration gère les nouvelles tentatives, l’état et les étapes de longue durée ; comment l’observabilité couvre les appels aux modèles, les flux de travail et la logique applicative ; comment les coûts s’accumulent entre le stockage, l’inférence et l’exécution des flux de travail.
La meilleure pile d’IA n’est pas celle qui possède les éléments les plus impressionnants pris individuellement. C’est celle dont les boucles de rétroaction produisent un comportement système fiable et prévisible. Dans cette optique, voici une architecture de référence pratique pour les start-ups modernes natives IA sur AWS.
Couche 1 : socle de données et de contexte
Chaque produit d’IA repose sur un socle de données. Cette couche détermine si le produit peut ancrer le comportement de l’IA dans un contexte durable et gouverné. Dans les systèmes de production, le contexte façonne la qualité de la récupération, le comportement du modèle, la personnalisation et la confiance. Si cette couche est fragile, obsolète ou mal gouvernée, l’instabilité se propage vers le haut.
Quatre modes de défaillance sont courants en pratique :
- Les données faisant autorité doivent survivre à tout modèle ou stratégie de récupération. Les équipes qui associent trop étroitement leur architecture de données à un modèle de vectorisation spécifique reconstruisent souvent le socle chaque fois que le modèle ou le schéma d’accès change.
- Le contexte doit être organisé pour un accès rapide et pertinent. La latence de récupération est un problème de qualité du produit qui se répercute sur chaque couche au-dessus d’elle.
- Le même contexte qui améliore la précision peut créer un risque s’il est obsolète, trop partagé ou mal isolé entre les locataires. Des limites encadrées sont essentielles à la précision et à la confiance, pas seulement à la conformité.
- Les données non structurées à longue durée de vie, les vectorisations et l’état opérationnel remplissent des objectifs différents et doivent rester distincts sur le plan architectural, même lorsqu’ils cohabitent.
Amazon Simple Storage Service (Amazon S3) reste le système d’enregistrement canonique des documents, transcriptions, artefacts et journaux. S3 Vectors prolonge ces fondations dans le stockage vectoriel natif à l’échelle de milliards de vecteurs, tout en préservant le modèle d’élasticité, de durabilité et de disponibilité de S3. Pour un ISV qui crée un produit à forte intensité de connaissances, le contenu réglementaire, l’historique des interactions client et les vectorisations qui rendent les deux consultables peuvent résider dans les mêmes compartiments, sous les mêmes politiques d’accès, sans base de données vectorielles distincte à provisionner, mettre à l’échelle et sécuriser.
Une équipe qui gérait auparavant une base de données vectorielles distincte devait assurer le provisionnement, surveiller l’état de l’index et planifier les opérations de mise à l’échelle séparément du reste de son infrastructure. S3 Vectors élimine entièrement cette charge. La solution hérite des mêmes politiques d’accès qui régissent déjà le magasin de documents. Il n’y a donc aucune stratégie de mise à l’échelle distincte, aucune gestion supplémentaire des informations d’identification et aucune nouvelle surface de défaillance à surveiller.
Les magasins vectoriels spécialisés ont encore leur place. OpenSearch est plus adapté lorsque l’application doit combiner une correspondance exacte de mots-clés avec une pertinence sémantique, ou lorsque les performances de récupération doivent être optimisées avec une latence plus faible. Les vectorisations multimodales Amazon Nova deviennent importantes lorsque les données ne sont pas uniquement textuelles. Une plateforme de renseignement sur les contrats qui traite des PDF numérisés parallèlement à des enregistrements structurés, ou une plateforme multimédia qui indexe des vidéos avec leurs transcriptions, bénéficie d’un espace vectoriel partagé plutôt que de pipelines fragmentés.
Principaux services : Amazon S3, Amazon S3 Vectors, Amazon OpenSearch Service (accéléré par GPU), vectorisations multimodales Amazon Nova, bases de connaissances Amazon Bedrock.
Point de départ : stockez les documents sources dans S3 avec une isolation des locataires basée sur des préfixes dès le premier jour, puis configurez une base de connaissances Bedrock pour ce compartiment avant de créer une logique de récupération personnalisée.
Couche 2 : modèle et service
Cette couche détermine comment le système génère de l’intelligence, et à quel coût. La question n’est pas de savoir quel modèle est le plus performant, mais quelle stratégie de modèle offre le bon équilibre entre précision, latence, coût et contrôle pour chaque type de charge de travail.
Un développeur spécialisé dans un domaine (technologies juridiques, assistant de codage ou classificateur de documents financiers) a besoin d’une précision exclusive qu’un modèle frontière générique ne peut pas fournir de manière cohérente ni durable sur le plan économique. Un ISV moderne a besoin d’une latence et d’un coût prévisibles au volume de requêtes. Et un consommateur d’inférence doit éviter de payer le prix d’un modèle frontière pour des tâches courantes comme le routage, la synthèse ou l’extraction d’entités, où un modèle optimisé plus petit offre des performances équivalentes à une fraction du coût.
Pour la plupart des équipes, Amazon Bedrock constitue le bon point de départ : une palette gérée de plus de 18 modèles à pondérations ouvertes aux côtés des modèles frontières d’Anthropic, avec Nova 2 dans le meilleur niveau coût-performance, sans la charge opérationnelle liée à l’exécution d’une infrastructure d’inférence. À mesure que le produit mûrit, la bonne question passe de « quel est le meilleur modèle ? » à « quelle part de notre avantage concurrentiel provient du comportement exclusif des modèles, par opposition aux flux de travail exclusifs du produit ? » Le peaufinage par renforcement (RFT) Bedrock peut améliorer la précision par rapport aux modèles de base sur des tâches propres à un domaine, ce qui rend des variantes plus petites, rapides et économiques viables au volume de production.
Pour les équipes qui ont besoin de plus de contrôle, Amazon SageMaker AI est le niveau géré, mais contrôlé, pour les développeurs qui doivent approfondir le peaufinage, l’évaluation, les MLOps et le déploiement personnalisé. C’est également la meilleure solution lorsque le comportement de modèle exclusif fait partie du produit lui-même. Les équipes qui ont besoin de schémas d’exécution qu’une interface entièrement gérée n’expose pas, comme la diffusion en continu bidirectionnelle pour des expériences vocales natives, trouveront SageMaker plus pratique. La diffusion audio en entrée et les transcriptions partielles en sortie rendent l’interaction fluide plutôt que limitée par la latence.
Pour les équipes qui créent des modèles de fondation à partir de zéro, EC2 Trn3 (Trainium3) offre un coût d’entraînement inférieur de 40 % et 5 fois plus de jetons de sortie par mégawatt, avec une intégration native PyTorch afin que les équipes puissent entraîner et déployer leurs modèles sans modifier le code du modèle. Amazon Elastic Kubernetes Service (EKS) se situe à l’extrémité du spectre pour les équipes qui ont besoin d’un contrôle complet de l’environnement d’exécution ou de piles de service spécialisées.
Les décisions relatives aux niveaux de modèle fixent le plancher de coût du système. Si chaque demande utilise par défaut un modèle frontière, les coûts augmentent rapidement à mesure que la récupération, les agents et les flux de travail en plusieurs étapes s’ajoutent. Une stratégie de modèle disciplinée maintient les capacités alignées sur les exigences des tâches et empêche le coût des modèles de dépasser discrètement le modèle économique du produit.
La page de tarification de Bedrock fournit une comparaison actualisée des coûts modèle par modèle pour les jetons d’entrée et de sortie. L’exécution de ces calculs sur votre volume de demandes attendu est une étape utile avant de finaliser votre architecture.
Principaux services : Amazon Bedrock (inférence sans serveur, niveaux de service), famille Amazon Nova 2, Bedrock RFT, SageMaker AI, EC2 Trn3 (Trainium3).
Point de départ : déterminez lesquelles de vos charges de travail nécessitent un modèle frontière et lesquelles pourraient être traitées par une solution plus petite ou moins coûteuse, car l’écart de coût s’accumule rapidement à grande échelle.
Couche 3 : inférence et environnement d’exécution agentique
L’inférence est le point où l’intention architecturale devient un comportement visible par l’utilisateur. Cette couche régit la latence, le débit, la simultanéité, l’état de session, les modèles d’interaction avec les outils, la qualité en cas de demande en rafales et le coût par interaction client. Le défi n’est pas la capacité, mais la fiabilité, l’isolation et la cohérence des coûts en conditions réelles : plusieurs locataires, demande en rafales, appels d’outil susceptibles d’échouer et flux de travail qui s’exécutent en minutes plutôt qu’en millisecondes.
C’est cette couche qui détermine si un ISV moderne peut vendre aux entreprises ou seulement aux adopteurs précoces. Une application agentique avec d’excellentes performances de modèle, mais sans isolation des locataires, sans durabilité des flux de travail et sans historique auditable des appels d’outil, échouera à un examen d’approvisionnement, non pas parce qu’elle est techniquement erronée, mais parce qu’elle ne peut pas être fiable au niveau du système.
Project Mantle, le moteur d’inférence sous-jacent à Bedrock, traite la fiabilité et l’isolation au niveau de l’infrastructure. Le routage par niveau de service permet à une plateforme de renseignement sur les contrats d’orienter l’extraction de clauses destinée aux utilisateurs vers une voie prioritaire, et le recoupement réglementaire en arrière-plan vers une voie flexible, afin d’optimiser les coûts sans dégrader l’expérience utilisateur. L’isolation des files d’attente par client signifie qu’un pic de chargements de documents chez un locataire n’affecte pas la session d’examen active d’un autre locataire. Le Journal, innovation clé au sein de Mantle, enregistre en continu des points de contrôle de l’état d’inférence, de sorte qu’un flux de travail de due diligence de longue durée qui échoue après 12 minutes reprend au point des 12 minutes, et non depuis le début.
Amazon Bedrock AgentCore fournit l’environnement d’exécution de production que la plupart des équipes passeraient autrement des mois à créer : déploiement d’agents conteneurisés avec n’importe quel framework (LangGraph, CrewAI, Strands Agents, OpenAI Agents SDK), mémoire épisodique intersession, accès aux outils basé sur MCP avec Cedar pour l’application des politiques, et évaluation continue de la qualité avec des évaluateurs en direct. Une équipe SaaS juridique qui exploite sa propre infrastructure d’agents mobilise généralement plusieurs ingénieurs pour gérer la conteneurisation, la gestion des sessions et la sécurité des outils. AgentCore regroupe ces préoccupations dans une couche gérée, libérant cette capacité d’ingénierie pour la bibliothèque de clauses, la taxonomie des risques et les règles de politique propres aux clients qui permettent de remporter des contrats.
Le principe qui fait la réussite ou l’échec de cette couche dans les cycles de vente en entreprise est la distinction entre les mécanismes et les bonnes intentions :
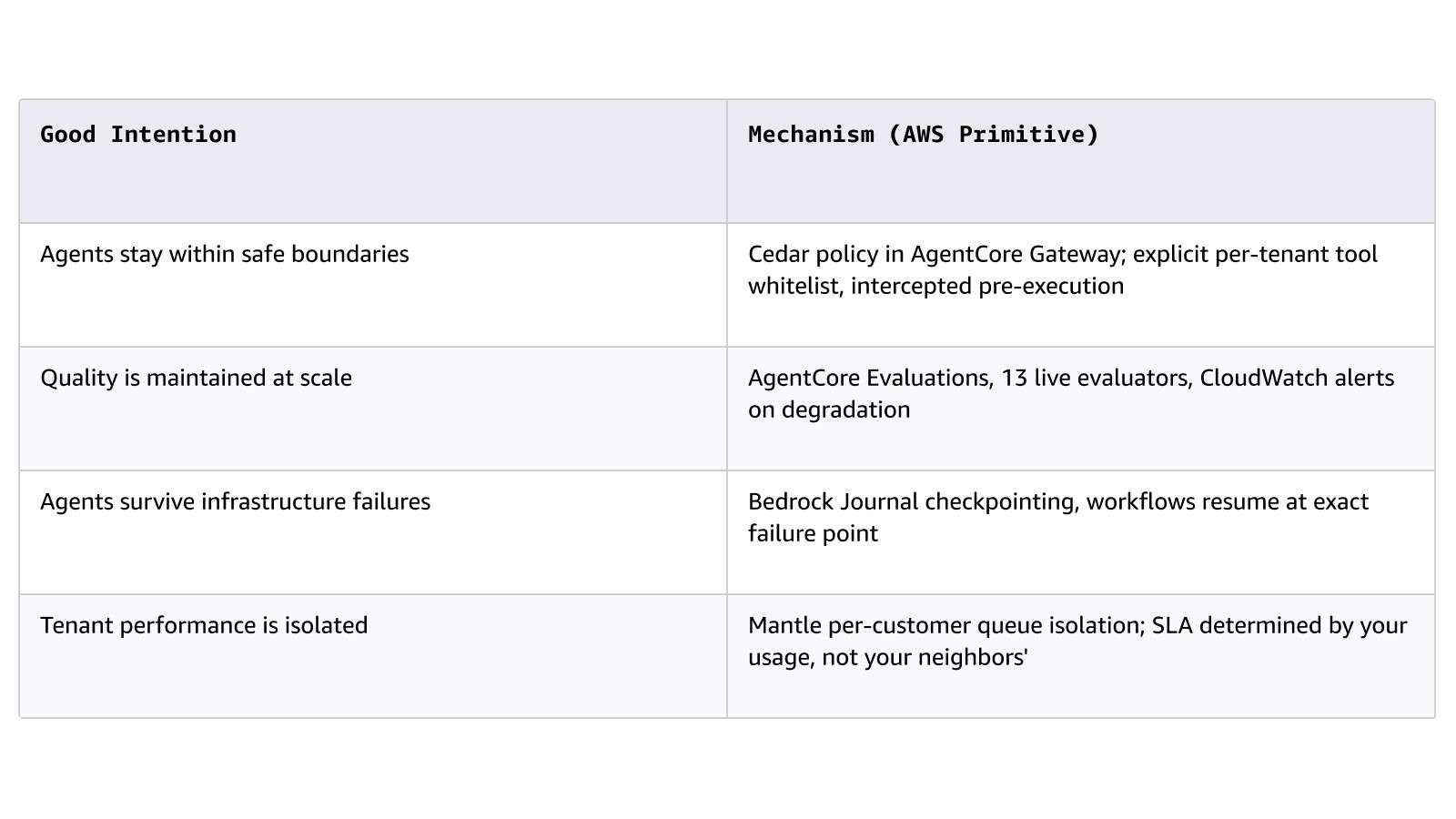
Principaux services : Amazon Bedrock (Project Mantle : niveaux de service, isolation des files d’attente, Journal), AgentCore (environnement d’exécution, mémoire, passerelle, évaluations, identité), Strands Agents, AWS Step Functions, Amazon Simple Queue Service (SQS).
Point de départ : dressez la liste des exigences d’entreprise auxquelles votre agent doit répondre et associez chacune d’elles à un mécanisme concret, plutôt qu’à une stratégie d’invite.
Couche 4 : orchestration et calcul
C’est la couche où l’IA cesse d’être un simple appel de modèle pour devenir un logiciel. La plupart des produits d’IA en production sont des systèmes en plusieurs étapes qui récupèrent le contexte, invoquent des modèles, appellent des outils, valident les sorties, déclenchent des actions en aval, conservent les résultats et réintègrent des flux de travail de manière asynchrone. L’orchestration fait partie de l’architecture applicative de base, et non d’un détail de mise en œuvre.
Prenons une plateforme SaaS de services financiers qui effectue des analyses de contrats. Une seule demande peut impliquer l’ingestion de documents, le découpage, la génération de vectorisations, la récupération d’informations dans des accords antérieurs, un raisonnement en plusieurs étapes sur des clauses, le routage vers un réviseur humain et le déclenchement d’un flux de travail de conformité en aval. Il s’agit d’un flux de travail applicatif durable avec logique de branchement, nouvelles tentatives, transitions d’état et étapes asynchrones s’étendant sur plusieurs minutes ou heures, et non d’un simple appel d’inférence.
L’idée structurelle reflète ici ce qui a rendu le calcul sans serveur transformateur : l’objectif n’est pas seulement de simplifier la gestion de l’infrastructure, mais de supprimer des catégories entières de gestion de l’infrastructure. Lambda Managed Instances applique ce principe à une lacune courante. Certaines charges de travail nécessitent des caractéristiques de calcul spécifiques (mémoire élevée pour la génération de vectorisations, pipelines de prétraitement de documents ou inférence de modèles intensive en CPU) qui sont trop lourdes pour de simples fonctions sans serveur, mais ne justifient pas une gestion directe du parc. Une start-up qui traite chaque jour des milliers de documents juridiques peut exécuter ces fonctions sur des profils d’instance spécifiques pendant que Lambda gère le provisionnement, la mise à l’échelle et les correctifs, ce qui permet de conserver une architecture sans serveur sans hériter des opérations de flotte EC2.
Pour les équipes qui ont besoin d’un contrôle plus poussé de l’environnement d’exécution, EKS fournit la cohérence et le contrôle que préfèrent les développeurs de modèles exécutant des serveurs d’inférence personnalisés ou les équipes de plateforme qui se standardisent autour de Kubernetes.
Amazon DynamoDB s’intègre naturellement comme plan de contrôle transactionnel pour l’état des flux de travail, les métadonnées de session, la configuration des locataires, les clés d’idempotence, les résultats des outils et les références d’audit. Il s’agit de l’épine dorsale opérationnelle qui maintient la cohérence de l’application à mesure que le travail se déplace entre les services et les étapes de flux de travail. Cette couche est distincte de la couche de mémoire sémantique utilisée pour la récupération.
L’environnement de développement optimisé par l’IA Kiro s’inscrit dans cette couche comme accélérateur de livraison de logiciels. Son rôle consiste à aider les équipes à traduire les exigences formulées en langage naturel en conceptions structurées, spécifications et tâches de mise en œuvre, afin d’avancer plus vite tout en maintenant la cohérence de l’architecture du système.
Principaux services : Lambda Managed Instances, Lambda Durable Functions, Amazon DynamoDB, Amazon EC2 M9g (Graviton5), AWS Step Functions, Amazon ECS sur Graviton5, Amazon EventBridge, Amazon SQS.
Point de départ : mappez votre flux de travail sur papier, en identifiant chaque étape susceptible d’échouer, de se ramifier ou de s’exécuter de manière asynchrone, avant de choisir un outil d’orchestration.
Couche 5 : gouvernance, observabilité et confiance
C’est là que de nombreuses piles d’IA échouent encore. Les équipes traitent la gouvernance comme un élément qui peut être ajouté plus tard. Les agents dotés d’un large accès aux outils, d’une rigueur d’évaluation limitée et de contraintes vagues fondées sur des invites érodent la confiance et créent des obstacles à l’adoption. Le meilleur principe ? Des mécanismes, pas des intentions.
Les acheteurs en entreprise posent deux questions constantes avant d’adopter un système d’IA : pouvez-vous démontrer que nos données ne franchissent jamais les frontières entre locataires ? Et pouvez-vous prouver que votre IA opère dans les limites que vous affirmez, avec des mécanismes qui appliquent ces limites et des journaux qui montrent ce qui s’est passé ?
Pour un ISV du secteur de la santé, cela signifie un agent soumis au périmètre HIPAA qui ne peut pas accéder aux dossiers en dehors du contexte autorisé d’un patient. Pour un fournisseur SaaS de services financiers, cela signifie un assistant de recherche en investissement dont les appels d’outil sont limités par des accords d’accès aux données propres au client. Il s’agit d’exigences standard pour les déploiements réglementés en entreprise, pas de cas périphériques.
Le calcul confidentiel Bedrock répond à la question de l’isolation des données dans le plan d’inférence en protégeant les données pendant l’exécution et en fournissant une limite d’environnement d’exécution offrant davantage de garanties. Des services comme Bedrock, AgentCore, Lambda et S3 peuvent fonctionner dans un modèle d’identité unifié, ce qui permet d’appliquer la gouvernance des accès de manière cohérente aux données, à l’invocation de modèles et à l’utilisation des outils par les agents, sans créer de système d’autorisation distinct pour chaque couche. Les mêmes politiques qui régissent l’accès aux données régissent également les appels de modèle et les autorisations des outils. Les journaux d’appels d’outil deviennent alors des enregistrements auditables du comportement du système.
La gouvernance à cette couche inclut également des contrôles de données tenant compte des locataires, la gestion des versions de modèle et d’invite, la traçabilité des appels d’outil et des flux de travail, la visibilité des coûts par environnement ou par client, et l’observabilité de bout en bout sur les couches application, flux de travail et modèle. Ce ne sont pas des luxes architecturaux. Ces éléments permettent aux équipes de raisonner sur le comportement du système, d’enquêter sur les incidents au niveau approprié et de démontrer la conformité sans reconstruire les événements à partir de journaux bruts.
Pour les équipes opérant dans la zone EMEA, le contexte réglementaire façonne plusieurs de ces décisions architecturales. Les exigences du RGPD relatives à la résidence des données signifient que l’isolation des locataires n’est pas seulement une exigence de vente en entreprise, mais aussi une obligation juridique. L’isolation basée sur les préfixes S3 et le chiffrement par locataire sont les mécanismes pratiques qui y répondent. Le règlement européen sur l’IA introduit d’autres obligations en matière de transparence et de supervision humaine pour les applications d’IA à haut risque, ce qui correspond directement à la journalisation d’audit et à la traçabilité des appels d’outil.
Notez que les modèles de Bedrock, S3 Vectors et AgentCore ne sont pas disponibles uniformément dans toutes les régions AWS EMEA. Les équipes doivent vérifier la disponibilité dans leur région cible avant de s’engager dans une architecture spécifique.
Les équipes de start-up doivent également noter que certains services mentionnés ci-dessus, notamment S3 Vectors et AgentCore, sont relativement nouveaux dans les environnements de production. Validez leur maturité pour votre cas d’utilisation et votre région avant d’en faire une infrastructure centrale.
Principaux services : Amazon Bedrock (calcul confidentiel), AWS Identity and Access Management (IAM), Amazon CloudWatch, AgentCore Policy (Cedar), AgentCore Evaluations, AWS Security Hub.
Point de départ : déterminez ce que votre journal d’audit doit prouver aux acheteurs ou aux responsables de la conformité. Remontez ensuite de cet objectif vers les politiques et les outils que vous devez mettre en place.
Comment le système complet s’articule
Une demande utilisateur arrive dans l’application. L’environnement d’exécution authentifie la demande et résout le contexte du locataire. La mémoire pertinente et les connaissances produit sont récupérées depuis la couche de contexte. La couche d’orchestration détermine si la tâche est une simple interaction avec un modèle ou un flux de travail en plusieurs étapes. La couche d’inférence génère l’étape suivante ou raisonne à son sujet. Les politiques limitent les outils qui peuvent être invoqués. Les étapes de longue durée enregistrent des points de contrôle de l’état et récupèrent proprement en cas d’échec. Le système émet de la télémétrie à chaque étape. Les évaluations et les boucles de rétroaction mesurent la qualité au fil du temps. Les équipes produit utilisent ces signaux pour affiner les invites, mettre à jour les politiques, améliorer la récupération ou déterminer quand une personnalisation plus poussée des modèles est justifiée.
C’est la pensée systémique mise en pratique. L’architecture gagnante est celle qui aligne données, contexte, inférence, flux de travail, gouvernance et opérations dans un système cohérent qui se comporte bien à mesure que l’entreprise passe à l’échelle.
Pour la plupart des équipes de start-up, le point d’entrée est la couche 1. Mettez en place un socle de données solide et une isolation correcte des locataires avant de vous attaquer aux agents ou à l’orchestration. Les couches suivantes ne sont fiables qu’à la hauteur des fondations sur lesquelles elles reposent.
Construisez-le. Maîtrisez-le.
Une pile d’IA bien conçue améliore le délai de mise sur le marché, la fiabilité, la confiance et la discipline des coûts, non pas grâce à un service unique, mais parce que les couches fonctionnent ensemble au sein d’un système cohérent. Lorsque la pile est orientée systèmes, les équipes peuvent faire évoluer leur architecture à mesure que l’entreprise se développe, sans repartir de zéro chaque fois qu’une nouvelle capacité apparaît.
Comment a été ce contenu ?