¿Qué le pareció este contenido?
- Aprender
- Creación de agentes de IA escalables: una arquitectura de referencia orientada a los sistemas para startups
Creación de agentes de IA escalables: una arquitectura de referencia orientada a los sistemas para startups

Cada generación de creadores se enfrenta a un cambio en la abstracción. El ensamblaje cedió el paso a los lenguajes de nivel superior. Los monolitos evolucionaron hasta convertirse en sistemas distribuidos. La infraestructura en las instalaciones dio paso a las plataformas nativas en la nube. Hoy en día, el software en sí mismo se está volviendo nativo de la IA, determinado por modelos, contextos, agentes y flujos de trabajo adaptables.
En re:Invent 2025, Werner Vogels definió este momento con claridad: los desarrolladores que tienen éxito piensan en sistemas y crean con precisión. Las empresas que salen ganando no son las que adoptaron la IA antes ni las que eligieron el modelo más capaz; son las que piensan en sistemas completos, las que entienden que cada decisión arquitectónica repercute en las capas superiores e inferiores.
Con demasiada frecuencia, la pila de IA moderna se trata como una lista de verificación: elegir un modelo, asociar la recuperación, agregar la orquestación e implementar. Los productos con tecnología de IA fracasan cuando los componentes parecen impresionantes por sí solos. Tienen éxito cuando el sistema se comporta de manera predecible bajo una carga real y equilibran la velocidad, la fiabilidad, la gobernanza y el costo.
Peter DeSantis expuso este argumento desde el punto de vista de la infraestructura en re:Invent 2025. Los cinco aspectos fundamentales con los que AWS lleva obsesionado veinte años (seguridad, disponibilidad, elasticidad, agilidad y costo) son ahora más importantes, no menos. Las cargas de trabajo de IA agravan todos los puntos débiles de la arquitectura. Un sistema que se escala a cien usuarios puede fallar estructuralmente a partir de los diez mil. Un modelo de costos que parece razonable en la fase de prototipo puede resultar insostenible con el volumen de producción. Y un enfoque de gobernanza basado en buenas intenciones no puede sobrevivir a una revisión de seguridad empresarial.
En este artículo se describe una arquitectura de referencia orientada a los sistemas para los creadores de modelos y los equipos de SaaS nativo de la IA que pasan del prototipo a la producción. Dicha arquitectura está compuesta por cinco capas que ofrecen todo su valor cuando trabajan juntas.
Piense en sistemas, no solo en servicios
Un error común en el diseño de la IA generativa es optimizar cada capa de forma independiente. Un equipo elige el “mejor” modelo. Otro elige el “mejor” almacén vectorial. Un tercero elige un marco de orquestación basándose en la familiaridad. Cada decisión puede parecer racional por sí sola, pero los usuarios experimentan el comportamiento de todo el sistema: velocidad de la recuperación, calidad de la respuesta, durabilidad de los flujos de trabajo, aplicación de políticas, aislamiento de los inquilinos y costo del servicio.
En el software nativo de la IA, esos resultados surgen de las interacciones entre las capas: cómo la identidad y los permisos fluyen hacia la recuperación y el acceso a las herramientas; cómo la actualización del contexto da forma a la calidad de los resultados; cómo la orquestación maneja los pasos de reintento, estado y ejecución prolongada; cómo la observabilidad abarca las llamadas a modelos, los flujos de trabajo y la lógica de las aplicaciones; cómo se acumulan los costos de almacenamiento, inferencia y ejecución de los flujos de trabajo.
La mejor pila de IA no es la que tiene las partes más impresionantes individualmente, sino aquella cuyos bucles de comentarios producen un comportamiento del sistema fiable y predecible. Desde este punto de vista, se incluye aquí una arquitectura de referencia práctica para las startups modernas nativas de la IA en AWS.
Capa 1: fundamento de datos y contexto
Todos los productos de IA se basan en un fundamento de datos. Esta capa determina si el producto puede basar el comportamiento de la IA en un contexto gobernado y duradero. En los sistemas de producción, el contexto determina la calidad de la recuperación, el comportamiento de los modelos, la personalización y la confianza. Si esta capa es frágil, se queda obsoleta o está mal gobernada, la inestabilidad se extiende hacia arriba.
En la práctica, son comunes cuatro modos de fallo:
- Los datos del origen de la información deben sobrevivir a cualquier modelo o estrategia de recuperación. Los equipos que vinculan demasiado su arquitectura de datos a un modelo de incrustación específico suelen reconstruir el fundamento cada vez que cambia el modelo o el patrón de acceso.
- El contexto debe organizarse para facilitar un acceso rápido y pertinente. La latencia de recuperación es un problema de calidad del producto que se agrava en todas las capas superiores.
- El mismo contexto que mejora la precisión puede generar riesgos si se queda obsoleto, se comparte en exceso o se aísla mal entre los inquilinos. Los límites gobernados son esenciales para la precisión y la confianza, no solo para el cumplimiento.
- Los datos no estructurados de larga duración, las incrustaciones vectoriales y el estado operativo tienen diferentes propósitos y deben permanecer separados desde el punto de vista arquitectónico, incluso cuando residen cerca unos de otros.
Amazon Simple Storage Service (Amazon S3) sigue siendo el sistema canónico de registro de documentos, transcripciones, artefactos y registros. S3 Vectors amplía ese fundamento al almacenamiento vectorial nativo a una escala de mil millones de vectores, al tiempo que preserva el modelo de elasticidad, durabilidad y disponibilidad de S3. En el caso de un proveedor de software independiente (ISV) que crea un producto que hace un uso intensivo de conocimientos, el contenido reglamentario, el historial de interacciones con los clientes y las incrustaciones que permiten efectuar búsquedas en ambos campos pueden agruparse bajo las mismas políticas de acceso, sin necesidad de disponer de una base de datos vectorial independiente que aprovisionar, escalar y proteger.
Un equipo que anteriormente administraba una base de datos vectorial independiente se encargaba del aprovisionamiento, supervisaba el estado de los índices y planificaba la escalabilidad de los eventos por separado del resto de su infraestructura. S3 Vectors elimina esto por completo. Hereda las mismas políticas de acceso que ya rigen el almacén de documentos, por lo que no hay una estrategia de escalado independiente, una administración de credenciales adicional ni una nueva superficie de fallos que supervisar.
Los almacenes vectoriales especializados todavía tienen cabida.OpenSearch es la mejor opción cuando la aplicación necesita combinar la coincidencia exacta de palabras clave con la pertinencia semántica, o cuando el rendimiento de recuperación debe optimizarse con una latencia más baja. Amazon Nova Multimodal Embeddings adquiere importancia cuando los datos no son solo texto. Una plataforma de inteligencia contractual que procese archivos PDF escaneados junto con registros estructurados, o una plataforma multimedia que indexe videos con transcripciones, se beneficia de un espacio vectorial compartido en lugar de canalizaciones fragmentadas.
Servicios clave: Amazon S3, Amazon S3 Vectors, Amazon OpenSearch Service (aceleración por GPU), Amazon Nova Multimodal Embeddings, Bases de conocimiento de Amazon Bedrock.
Punto de partida: almacene los documentos de origen en S3 con un aislamiento de inquilinos basado en prefijos desde el primer día y, a continuación, configure una base de conocimiento de Bedrock con ese bucket antes de crear cualquier lógica de recuperación personalizada.
Capa 2: modelo y prestación
Esta capa determina cómo el sistema genera inteligencia y cuánto cuesta hacerlo. La decisión no es qué modelo es más capaz, sino qué estrategia de modelo ofrece el equilibrio adecuado entre precisión, latencia, costo y control para cada tipo de carga de trabajo.
Un creador específico de un dominio (tecnología legal, asistente de codificación o clasificador de documentos financieros) necesita una precisión patentada que un modelo de frontera genérico no puede ofrecer de manera uniforme ni mantener económicamente. Un ISV moderno necesita una latencia y un costo predecibles en función del volumen de consultas. Además, los consumidores de inferencias deben evitar pagar los precios de los modelos de frontera por tareas rutinarias, como el enrutamiento, el resumen o la extracción de entidades, en las que un modelo ajustado más pequeño funciona de manera equivalente a una fracción del costo.
Para la mayoría de los equipos, Amazon Bedrock es el punto de partida correcto: una selección administrada de más de dieciocho modelos de peso abierto junto con los modelos de frontera de Anthropic, con Nova 2 en el nivel con la mejor relación entre costo y rendimiento, sin la carga operativa de ejecutar una infraestructura de inferencia. A medida que el producto va madurando, la pregunta correcta pasa de ser “¿cuál es el mejor modelo?” a “¿qué parte de nuestra ventaja competitiva proviene del comportamiento de los modelos patentados frente a los flujos de trabajo de los productos patentados?”. El refinamiento mediante refuerzo (RFT) de Bedrock puede mejorar la precisión en tareas específicas de un dominio en comparación con los modelos básicos, lo que hace que las variantes más pequeñas, rápidas y rentables sean prácticas para el volumen de producción.
Para los equipos que necesitan más control, Amazon SageMaker AI es el nivel administrado pero controlado para los creadores que necesitan profundizar en el refinamiento, la evaluación, las MLOps y la implementación personalizada. También es la mejor opción cuando el comportamiento de los modelos patentados forma parte del producto en sí. Para los equipos que necesitan patrones de tiempo de ejecución que una superficie totalmente administrada no exponga, como la transmisión bidireccional para experiencias de voz nativas, SageMaker será la opción más práctica. La transmisión de audio y la salida de transcripciones parciales hacen que la interacción parezca fluida, en lugar de estar limitada por la latencia.
Para los equipos que crean modelos fundacionales desde cero, Trn3 (Trainium3) de EC2 ofrece un costo de entrenamiento un 40 % más bajo y cinco veces más tokens de salida por megavatio, con una integración nativa con PyTorch para que los equipos puedan entrenar e implementar sin cambiar el código del modelo. Amazon Elastic Kubernetes Service (EKS) se encuentra en el extremo más alejado del espectro para los equipos que necesitan un control total del tiempo de ejecución o pilas especializadas de prestación.
Las decisiones de nivel de modelo establecen el costo mínimo del sistema. Si todas las solicitudes se basan de forma predeterminada en un modelo de frontera, los costos aumentan rápidamente a medida que se agregan la recuperación, los agentes y los flujos de trabajo de varios pasos. Una estrategia de modelos disciplinada mantiene la capacidad alineada con los requisitos de las tareas y evita que el costo de los modelos supere discretamente a la economía de los productos.
En la página de precios de Bedrock se ofrece una comparación de los costos actuales modelo por modelo entre los tokens de entrada y salida. Vale la pena llevar a cabo estos cálculos con el volumen esperado de solicitudes antes de finalizar la arquitectura.
Servicios clave: Amazon Bedrock (inferencia sin servidor, niveles de servicio), familia Amazon Nova 2, RFT de Bedrock, SageMaker AI, Trn3 (Trainium3) de EC2.
Punto de partida: identifique cuáles de sus cargas de trabajo requieren un modelo de frontera y cuáles podrían manejarse con una alternativa más pequeña o más barata, ya que la diferencia de costos se agrava rápidamente a escala.
Capa 3: inferencia y tiempo de ejecución agéntico
La inferencia es donde la intención arquitectónica se convierte en un comportamiento visible para el usuario. Esta capa regula la latencia, el rendimiento, la concurrencia, el estado de las sesiones, los patrones de interacción entre las herramientas, la calidad ante picos de demanda y el costo por interacción con el cliente. El desafío no es la capacidad, sino la fiabilidad, el aislamiento y la uniformidad de los costos en condiciones reales: múltiples inquilinos, picos de demanda, llamadas a herramientas que pueden fallar y flujos de trabajo que duran minutos en lugar de milisegundos.
Esta es la capa que determina si un ISV moderno puede vender a empresas o solo a los primeros usuarios. Una aplicación agéntica con un rendimiento excelente de modelos, pero sin aislamiento de inquilinos, sin durabilidad de los flujos de trabajo y sin un historial auditable de llamadas a herramientas no superará la revisión de la adquisición, no porque sea técnicamente incorrecta, sino porque no se puede confiar en ella en el nivel del sistema.
Project Mantle, el motor de inferencia subyacente a Bedrock, aborda la fiabilidad y el aislamiento en el nivel de infraestructura. El enrutamiento por niveles de servicio permite a una plataforma de inteligencia contractual dirigir la extracción de cláusulas orientadas al usuario a una vía prioritaria y la verificación reglamentaria en segundo plano a una vía flexible, lo que optimiza los costos sin degradar la experiencia del usuario. El aislamiento de las colas por cliente significa que el hecho de que un inquilino suba varios documentos no afecta a la sesión de revisión activa de otro inquilino. Journal, una innovación clave de Mantle, comprueba continuamente el estado de las inferencias, de modo que un flujo de trabajo de diligencia debida de larga duración que falla a los doce minutos se reanuda en ese punto, no desde el principio.
Amazon Bedrock AgentCore proporciona el tiempo de ejecución de producción que, de otro modo, la mayoría de los equipos dedicarían meses a crear: implementación de agentes en contenedores en cualquier marco (LangGraph, CrewAI, Strands Agents, OpenAI Agents SDK), memoria episódica entre sesiones, acceso a herramientas basadas en el protocolo de contexto para modelos (MCP) con la aplicación de políticas de Cedar y evaluación continua de la calidad comparándola con evaluadores en tiempo real. Un equipo legal de SaaS que gestiona su propia infraestructura de agentes suele depender de varios ingenieros para administrar la creación de contenedores, el manejo de las sesiones y la seguridad de las herramientas. AgentCore consolida esas preocupaciones en una capa administrada, lo que libera esa capacidad de ingeniería para dedicarse a la biblioteca de cláusulas, la taxonomía de riesgos y las reglas de políticas específicas del cliente, que permiten cerrar acuerdos.
El principio que determina el éxito o fracaso de esta capa en los ciclos de ventas empresariales es la distinción entre los mecanismos y las buenas intenciones:
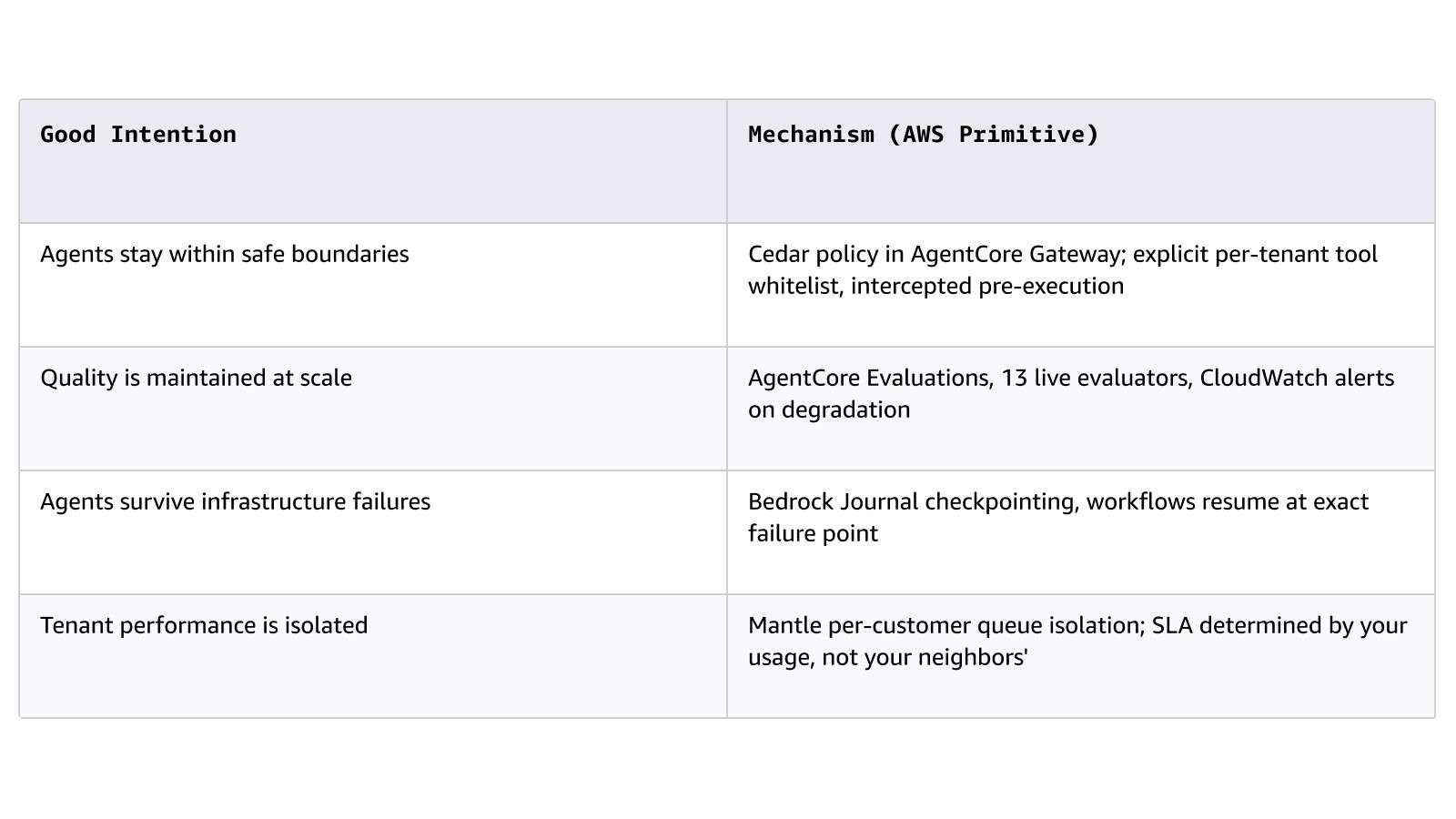
Servicios clave: Amazon Bedrock (Project Mantle: niveles de servicios, aislamiento de colas, Journal), AgentCore (Tiempo de ejecución, Memoria, Puerta de enlace, Evaluaciones, Identidad), Strands Agents, AWS Step Functions, Amazon Simple Queue Service (SQS).
Punto de partida: enumere los requisitos empresariales que su agente debe cumplir y asigne cada uno de ellos a un mecanismo concreto, en lugar de a una estrategia de peticiones.
Capa 4: orquestación y computación
Esta es la capa en la que la IA deja de ser una única llamada a un modelo y se convierte en software. La mayoría de los productos de IA de producción son sistemas de varios pasos que recuperan el contexto, invocan modelos, llaman a herramientas, validan los resultados, activan acciones posteriores, conservan los resultados y vuelven a ingresar los flujos de trabajo de forma asíncrona. La orquestación forma parte de la arquitectura principal de las aplicaciones, no es un detalle de la implementación.
Considere una plataforma de SaaS de servicios financieros que analice contratos. Una sola solicitud puede implicar la ingesta de documentos, la fragmentación, la generación de incrustaciones, la recuperación a partir de contratos anteriores, el razonamiento en varios pasos sobre las cláusulas, el enrutamiento a un revisor humano y la activación de un flujo de trabajo de cumplimiento posterior. Se trata de un flujo de trabajo duradero de aplicaciones con lógica ramificada, reintentos, transiciones de estado y pasos asíncronos que duran minutos u horas, sin una sola llamada de inferencia.
La información estructural aquí refleja lo que hizo que la computación sin servidor fuera transformadora: el objetivo no es simplemente facilitar la administración de la infraestructura, sino eliminar categorías enteras de administración de la infraestructura. Lambda Managed Instances aplica ese principio a una brecha común. Algunas cargas de trabajo requieren características de computación específicas, una gran cantidad de memoria para la generación de incrustaciones, canalizaciones de preprocesamiento de documentos o inferencia de modelos con un uso intensivo de la CPU, que son demasiado pesadas para funciones simples sin servidor, pero no justifican la administración directa de la flota. Una startup que procesa miles de documentos legales a diario puede ejecutar esas funciones en perfiles de instancia específicos, mientras que Lambda administra el aprovisionamiento, el escalado y la aplicación de revisiones, al tiempo que mantiene una arquitectura sin servidor sin heredar las operaciones de la flota de EC2.
Para los equipos que requieren un control más profundo del tiempo de ejecución, EKS proporciona la coherencia y el control que prefieren los creadores de modelos que ejecutan servidores de inferencia personalizados o los equipos de plataformas que estandarizan en Kubernetes.
Amazon DynamoDB se adapta de forma natural como plano de control transaccional para el estado de los flujos de trabajo, los metadatos de las sesiones, la configuración de los inquilinos, las claves de idempotencia, los resultados de las herramientas y las referencias de auditoría. Es la columna vertebral operativa que mantiene la coherencia de la aplicación a medida que el trabajo avanza en los servicios y los distintos pasos del flujo de trabajo. Esto es diferente de la capa de memoria semántica que se utiliza para la recuperación.
El entorno de desarrollo con tecnología de IA Kiro encaja en esta capa como un acelerador de entrega de software. Su función es ayudar a los equipos a traducir los requisitos del lenguaje natural en diseños, especificaciones y tareas de implementación estructurados, lo que les permite avanzar más rápido y, al mismo tiempo, mantener la coherencia de la arquitectura del sistema.
Servicios clave: Lambda Managed Instances, funciones duraderas de Lambda, Amazon DynamoDB, M9g (Graviton5) de Amazon EC2, AWS Step Functions, Amazon ECS en Graviton5, Amazon EventBridge, Amazon SQS.
Punto de partida: esboce su flujo de trabajo en papel e identifique cada paso que podría fallar, ramificarse o ejecutarse de forma asíncrona antes de elegir cualquier herramienta de orquestación.
Capa 5: gobernanza, observabilidad y confianza
Es aquí donde muchas pilas de IA siguen fallando. Los equipos consideran que la gobernanza es algo que se puede agregar más adelante. Los agentes con un amplio acceso a las herramientas, un rigor de evaluación limitado y restricciones imprecisas basadas en las peticiones erosionan la confianza y generan barreras para la adopción. ¿El mejor principio? Mecanismos, no intenciones.
Los compradores empresariales se hacen dos preguntas coherentes antes de adoptar un sistema de IA: ¿se puede demostrar que nuestros datos nunca superan los límites de los inquilinos? y ¿se puede demostrar que la IA funciona dentro de los límites que se afirman, con mecanismos que hagan cumplir esos límites y con registros que muestren lo que ocurrió?
Para un ISV de servicios de salud, esto significa un agente con el alcance de la HIPAA que no puede acceder a los historiales fuera del contexto autorizado del paciente. Para un proveedor de SaaS de servicios financieros, significa un asistente de investigación de inversiones cuyas herramientas se ven limitadas por los acuerdos de acceso a los datos específicos del cliente. Se trata de requisitos estándar para las implementaciones empresariales reguladas, no de casos extremos.
La computación confidencial de Bedrock aborda la cuestión del aislamiento de datos en el plano de inferencia al proteger los datos durante la ejecución y proporcionar un límite de tiempo de ejecución de mayor seguridad. Los servicios, incluidos Bedrock, AgentCore, Lambda y S3, pueden funcionar dentro de un modelo de identidad unificado, lo que permite que la gobernanza del acceso se aplique de manera uniforme en todos los datos, la invocación de modelos y el uso de las herramientas de agentes, sin crear un sistema de autorización independiente para cada capa. Las mismas políticas que rigen el acceso a los datos también rigen las llamadas a modelos y los permisos de las herramientas. Los registros de llamadas a las herramientas se convierten entonces en registros auditables del comportamiento del sistema.
La gobernanza en esta capa también incluye controles de datos basados en los inquilinos, control de versiones de modelos y peticiones, trazabilidad en todas las llamadas a herramientas y flujos de trabajo, visibilidad de costos por entorno o cliente y observabilidad integral en todas las capas de aplicaciones, flujos de trabajo y modelos. No se trata de lujos arquitectónicos. Son los que permiten a los equipos razonar sobre el comportamiento del sistema, investigar los incidentes en la capa correcta y demostrar el cumplimiento sin tener que reconstruir los eventos a partir de registros sin procesar.
Para los equipos que operan en EMEA, el contexto reglamentario da forma a varias de estas decisiones arquitectónicas. Los requisitos del RGPD en relación con la residencia de datos significan que el aislamiento de los inquilinos no es solo un requisito de ventas empresariales, sino también legal. El aislamiento basado en prefijos de S3 y el cifrado por inquilino son los mecanismos prácticos que lo satisfacen. La Ley de IA de la UE introduce más obligaciones en materia de transparencia y supervisión humana para las aplicaciones de IA de alto riesgo, y se relaciona directamente con el registro de auditorías y la trazabilidad de las llamadas a herramientas.
Tenga en cuenta que la disponibilidad de los modelos de Bedrock, S3 Vectors y AgentCore no están disponibles de manera uniforme en todas las regiones de EMEA de AWS. Los equipos deben verificar la disponibilidad en la región de destino antes de comprometerse con una arquitectura específica.
Los equipos de startups también deben tener en cuenta que algunos de los servicios mencionados anteriormente, incluidos S3 Vectors y AgentCore, son relativamente nuevos en los entornos de producción. Valide la madurez de su caso de uso y región específicos antes de utilizarlos como infraestructura principal.
Servicios clave: Amazon Bedrock (computación confidencial), AWS Identity and Access Management (IAM), Amazon CloudWatch, política de AgentCore (Cedar), Evaluaciones de AgentCore, AWS Security Hub.
Punto de partida: decida qué debe demostrar su registro de auditoría a los compradores o a los responsables de cumplimiento. A continuación, retroceda desde ese punto hasta llegar a las políticas y herramientas que necesita implementar.
Cómo se integra el sistema completo
Una solicitud del usuario entra en la aplicación. El tiempo de ejecución autentica la solicitud y resuelve el contexto del inquilino. Los conocimientos pertinentes de memoria y producto se recuperan de la capa de contexto. La capa de orquestación determina si la tarea es una simple interacción con un modelo o un flujo de trabajo de varios pasos. La capa de inferencia genera o razona sobre el siguiente paso. Las políticas limitan las herramientas que se pueden invocar. Los pasos de larga duración comprueban el estado y se recuperan de forma limpia en caso de error. El sistema emite telemetría en cada etapa. Las evaluaciones y los bucles de comentarios miden la calidad a lo largo del tiempo. Los equipos de producto utilizan esas señales para refinar las peticiones, actualizar las políticas, mejorar la recuperación o decidir cuándo se justifica una personalización más profunda del modelo.
Ese es el pensamiento sistémico en la práctica. La arquitectura ganadora es la que alinea los datos, el contexto, la inferencia, el flujo de trabajo, la gobernanza y las operaciones en un sistema coherente que se comporta bien a medida que la empresa escala.
Para la mayoría de los equipos de startups, el punto de entrada es la capa 1. Consiga el fundamento de datos y el aislamiento de inquilinos justo antes de abordar los agentes o la orquestación. Las capas siguientes son tan fiables como el fundamento que se encuentra debajo de ellas.
Créela y hágala suya
Una pila de IA bien diseñada mejora el tiempo de comercialización, la fiabilidad, la confianza y la disciplina de costos, no gracias a un servicio único, sino porque las capas funcionan juntas como un sistema coherente. Cuando la pila está orientada a los sistemas, los equipos pueden hacer evolucionar su arquitectura a medida que la empresa crece sin tener que volver a crear desde cero cada vez que aparece una nueva funcionalidad.
¿Qué le pareció este contenido?