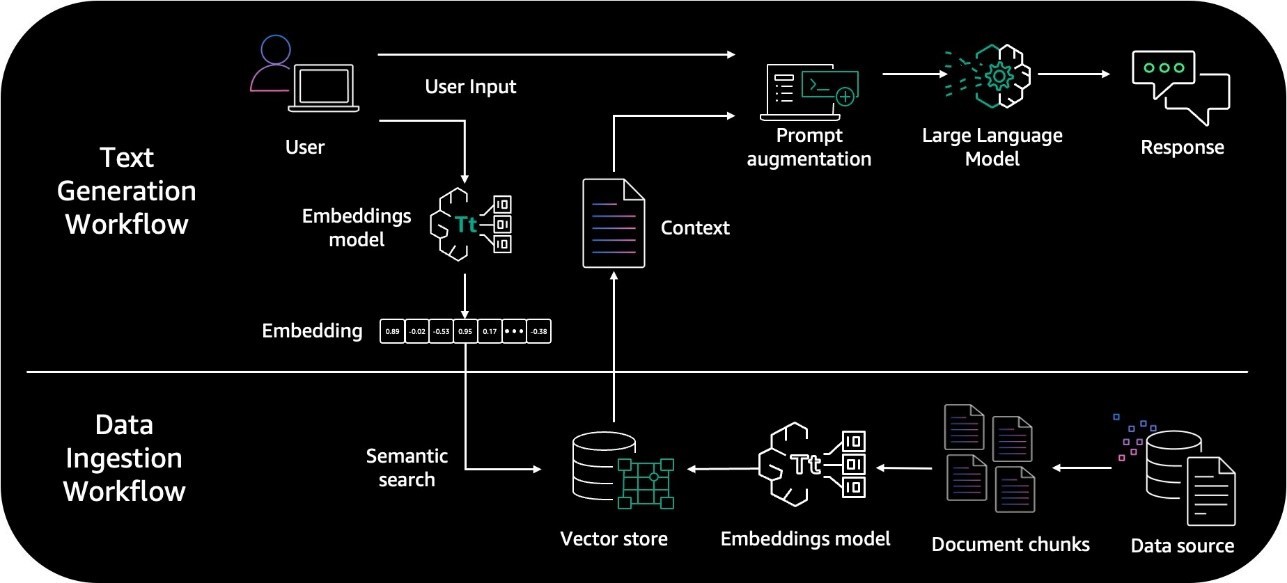
La génération à enrichissement contextuel (RAG) est le processus consistant à optimiser le résultat d’un grand modèle de langage. Elle fait donc appel à une base de connaissances fiable externe aux sources de données utilisées pour l’entraîner avant de générer une réponse. Les grands modèles de langage (LLM) sont entraînés avec d’importants volumes de données et utilisent des milliards de paramètres pour générer des résultats originaux pour des tâches telles que répondre à des questions, traduire des langues et compléter des phrases. La RAG étend les capacités déjà très puissantes des LLM à des domaines spécifiques ou à la base de connaissances interne d’une organisation, le tout sans qu’il soit nécessaire de réentraîner le modèle. Il s’agit d’une approche économique pour améliorer les résultats du LLM et garantir qu’ils restent pertinents, précis et utiles dans de nombreux contextes.
Amazon Bedrock est un service entièrement géré qui propose un choix de modèles de base très performants, ainsi qu’un large éventail de fonctionnalités, pour créer des applications d’IA génératives tout en simplifiant le développement et en préservant la confidentialité et la sécurité.
La base de connaissances pour Amazon Bedrock vous aide à tirer parti de la génération à enrichissement contextuel (RAG), une technique populaire qui consiste à extraire des informations d’un magasin de données pour augmenter les réponses générées par les grands modèles de langage (LLM). Lorsque vous configurez une base de connaissances avec vos sources de données, votre application peut interroger la base de connaissances pour renvoyer des informations permettant de répondre à la requête, soit par des citations directes provenant des sources, soit par des réponses naturelles générées à partir des résultats de la requête.
Les bases de connaissances vous permettent de créer des applications enrichies par le contexte généré par l’interrogation d’une base de connaissances. Cela vous permet d’accélérer la mise sur le marché en évitant les tâches fastidieuses liées à la construction de pipelines et en vous fournissant une solution RAG prête à l’emploi pour réduire le temps de création de votre application. L’ajout d’une base de connaissances augmente également la rentabilité en supprimant la nécessité d’entraîner continuellement votre modèle pour qu’il puisse tirer parti de vos données privées.