Come ti è sembrato il contenuto?
- Scopri
- Crea agenti IA scalabili: un'architettura di riferimento orientata ai sistemi per le startup
Crea agenti IA scalabili: un'architettura di riferimento orientata ai sistemi per le startup

Ogni generazione di costruttori affronta un cambiamento nell'astrazione. L'assemblaggio ha ceduto a linguaggi di livello superiore. I monoliti si sono evoluti in sistemi distribuiti. L'infrastruttura on-premises ha lasciato il posto a piattaforme native per il cloud. Ora il software stesso sta diventando nativo dell'IA, plasmato da modelli, contesto, agenti e flussi di lavoro adattivi.
A re:Invent 2025, Werner Vogels ha inquadrato chiaramente questo momento: gli sviluppatori che hanno successo pensano in termini di sistemi e costruiscono con precisione. Le aziende che vincono non sono quelle che hanno adottato l'IA per prime o hanno scelto il modello più capace. Sono quelle che pensano in termini di sistemi completi, che comprendono che ogni decisione architettonica si ripercuote sugli strati superiori e sottostanti.
Il moderno stack di IA viene troppo spesso trattato come una lista di controllo: scegli un modello, allega il recupero, aggiungi l'orchestrazione, implementa. I prodotti basati sull'IA falliscono quando i componenti sembrano impressionanti da soli. Hanno successo quando il sistema si comporta in modo prevedibile sotto il carico reale, bilanciando velocità, affidabilità, governance e costi.
Peter DeSantis ha sollevato questa argomentazione dal punto di vista dell'infrastruttura a re:Invent 2025. I cinque elementi fondamentali su cui AWS si concentra da vent'anni (sicurezza, disponibilità, elasticità, agilità e costi) ora sono più importanti, non meno. I carichi di lavoro basati sull’IA aggravano ogni debolezza dell'architettura. Un sistema scalabile fino a 100 utenti può fallire strutturalmente a 10.000. Un modello di costo che appare ragionevole in fase di prototipo può diventare insostenibile in termini di volume di produzione. E un approccio di governance basato su buone intenzioni non può sopravvivere a una revisione della sicurezza aziendale.
Questo articolo delinea un'architettura di riferimento orientata ai sistemi per i costruttori di modelli e i team SaaS nativi dell'IA che passano dal prototipo alla produzione, composta da cinque livelli che offrono il loro pieno valore quando lavorano insieme.
Pensa ai sistemi, non solo ai servizi
Un errore comune nella progettazione basata sull’IA generativa è l'ottimizzazione di ogni livello in modo indipendente. Un team sceglie il “miglior” modello. Un altro sceglie il “miglior” archivio vettore. Un terzo sceglie un framework di orchestrazione basato sulla familiarità. Ogni decisione può sembrare razionale da sola, ma gli utenti sperimentano il comportamento dell'intero sistema: velocità di recupero, qualità della risposta, durata del flusso di lavoro, applicazione delle policy, isolamento degli inquilini e costi di gestione.
Nel software nativo dell’IA, questi risultati emergono dalle interazioni tra più livelli: come identità e autorizzazioni fluiscono nel recupero e nell'accesso agli strumenti; come la freschezza del contesto modella la qualità dell'output; come l'orchestrazione gestisce i tentativi, lo stato e le fasi di esecuzione di lunga durata; come l'osservabilità copre le chiamate ai modelli, i flussi di lavoro e la logica delle applicazioni; come i costi si aggravano tra archivio, inferenza ed esecuzione del flusso di lavoro.
Il miglior stack basato sull’IA non è quello con le parti più impressionanti dal punto di vista individuale. È quello i cui loop di feedback producono un comportamento del sistema affidabile e prevedibile. Con questo obiettivo, ecco una pratica architettura di riferimento per le moderne startup native dell'IA su AWS.
Livello 1: base di dati e contesto
Ogni prodotto basato sull’IA è costruito su una base per la gestione dei dati. Questo livello determina se il prodotto è in grado di basare il comportamento dell'IA in un contesto duraturo e governato. Nei sistemi di produzione, il contesto modella la qualità del recupero, il comportamento dei modelli, la personalizzazione e la fiducia. Se questo strato è fragile, obsoleto o mal governato, l'instabilità si diffonde verso l'alto.
Nella pratica sono comuni quattro modalità di errore:
- I dati Source-of-Truth devono sopravvivere a qualsiasi modello o strategia di recupero. I team che legano troppo strettamente l'architettura dei dati a uno specifico modello di embedding spesso ricostruiscono le fondamenta ogni volta che il modello o il modello di accesso cambia.
- Il contesto deve essere organizzato per un accesso rapido e pertinente. La latenza di recupero è un problema di qualità del prodotto che si aggrava a tutti i livelli superiori.
- Lo stesso contesto che migliora la precisione può creare rischi se è obsoleto, eccessivamente condiviso o scarsamente isolato tra i tenant. I confini gestiti sono essenziali per la precisione e la fiducia, non solo per la conformità.
- I dati non strutturati di lunga durata, gli embedding vettoriali e lo stato operativo servono a scopi diversi e dovrebbero rimanere distinti dal punto di vista architettonico, anche quando vivono vicini tra loro.
Amazon Simple Storage Service (Amazon S3) rimane il sistema canonico di registrazione per documenti, trascrizioni, artefatti e log. S3 Vectors estende questa base all’archivio vettore nativo su scala di miliardi di vettori, preservando il modello di elasticità, durata e disponibilità di S3. Per un ISV che crea un prodotto ad alta intensità di conoscenze, i contenuti normativi, la cronologia delle interazioni con i clienti e gli embedding che rendono entrambi ricercabili possono risiedere negli stessi bucket con le stesse politiche di accesso, senza un database vettoriale separato da fornire, scalare e proteggere.
Un team che in precedenza gestiva un database vettoriale separato gestiva il provisioning, monitorava lo stato degli indici e pianificava la scalabilità degli eventi separatamente dal resto della propria infrastruttura. S3 Vectors lo rimuove completamente. Eredita le stesse politiche di accesso che già regolano l'archivio dei documenti, quindi non esiste una strategia di scalabilità separata, nessuna gestione aggiuntiva delle credenziali e nessuna nuova superficie di errore da monitorare.
Gli archivi vettori specializzati hanno ancora un posto. OpenSearch è la soluzione migliore quando l'applicazione deve combinare l'esatta corrispondenza delle parole chiave con la pertinenza semantica o quando le prestazioni di recupero devono essere ottimizzate a una latenza inferiore. Gli Embedding multimodaliAmazon Nova diventano importanti quando i dati non sono puramente testo. Una piattaforma di intelligence contrattuale che elabora PDF scansionati insieme a record strutturati, o una piattaforma multimediale che indicizza video con trascrizioni, trae vantaggio da uno spazio vettoriale condiviso anziché da pipeline frammentate.
Servizi chiave: Amazon S3, Amazon S3 Vectors, Servizio OpenSearch di Amazon (accelerato da GPU), Amazon Nova Embedding multimodali, Amazon Bedrock Knowledge Bases.
Punto di partenza: archivia i documenti sorgente in S3 con isolamento dei tenant basato su prefisso sin dal primo giorno, quindi configura una Bedrock Knowledge Base su quel bucket prima di creare qualsiasi logica di recupero personalizzata.
Livello 2: modello e servizio
Questo livello determina in che modo il sistema genera intelligenza e quanto costa farlo. La decisione non è il modello più capace, ma la strategia del modello che offre il giusto equilibrio tra precisione, latenza, costi e controllo per ogni tipo di carico di lavoro.
Un generatore specifico per un dominio (legaltech, assistente alla codifica o classificatore di documenti finanziari) necessita di una precisione proprietaria che un modello di frontiera generico non può fornire in modo coerente o sostenere economicamente. Un ISV moderno necessita di latenza e costi prevedibili in base al volume delle query. Inoltre, chi utilizza l'inferenza deve evitare di pagare prezzi da modello di frontiera per attività di routine come l'instradamento, il riepilogo o l'estrazione di entità, in cui un modello ottimizzato di dimensioni ridotte offre prestazioni equivalenti a una frazione del costo.
Per la maggior parte dei team, Amazon Bedrock è il punto di partenza giusto, una gamma gestita di oltre 18 modelli a peso aperto insieme ai modelli di frontiera di Anthropic, con Nova 2 nel miglior livello costo/prestazioni, senza l'onere operativo della gestione dell'infrastruttura di inferenza. Man mano che il prodotto matura, la domanda giusta passa da “qual è il modello migliore?” a “quanto del nostro vantaggio competitivo deriva dal comportamento dei modelli proprietari rispetto ai flussi di lavoro dei prodotti proprietari?” Bedrock Reinforcement Fine-Tuning (RFT) può migliorare la precisione rispetto ai modelli base su attività specifiche del dominio, rendendo pratiche varianti più piccole, veloci ed economiche a volume di produzione.
Per i team che necessitano di un maggiore controllo, Amazon SageMaker AI è il livello gestito ma controllato per i costruttori che devono approfondire il fine-tuning, la valutazione, le MLOP e la distribuzione personalizzata. È anche la soluzione migliore quando il comportamento del modello proprietario fa parte del prodotto stesso. I team che necessitano di modelli di runtime che una superficie completamente gestita non espone, come lo streaming bidirezionale per esperienze vocali native, troveranno in SageMaker la scelta più pratica. Lo streaming audio in ingresso e le trascrizioni parziali in uscita rendono l'interazione fluida anziché vincolata alla latenza.
Per i team che creano modelli di base da zero, EC2 Trn3 (Trainium3) offre un costo di formazione inferiore del 40% e token di output 5 volte superiori per megawatt, con integrazione nativa di PyTorch in modo che i team possano addestrarsi e implementare senza modificare il codice del modello. Amazon Elastic Kubernetes Service (EKS) si colloca all'estremità dello spettro per i team che necessitano di un controllo completo del runtime o di stack di servizio specializzati.
Le decisioni a livello di modello stabiliscono il costo minimo del sistema. Se per impostazione predefinita per ogni richiesta viene utilizzato un modello di frontiera, i costi aumentano rapidamente con l'aggiunta di procedure di recupero, agenti e flussi di lavoro in più fasi. Una strategia basata sui modelli mantiene la capacità allineata ai requisiti delle attività e impedisce che il costo del modello superi silenziosamente l'economia del prodotto.
La pagina dei prezzi di Bedrock fornisce un confronto attuale dei costi modello per modello tra i token di input e output. L'esecuzione di questi calcoli rispetto al volume di richieste previsto è un passaggio utile prima di finalizzare l'architettura.
Servizi chiave: Amazon Bedrock (inferenza serverless, livelli di servizio), famiglia di Amazon Nova 2, Bedrock RFT, SageMaker AI, EC2 Trn3 (Trainium3).
Punto di partenza: identifica quali carichi di lavoro richiedono un modello di frontiera e quali potrebbero essere gestiti da un'alternativa più piccola o più economica, poiché la differenza di costo si aggrava rapidamente su larga scala.
Livello 3: Inferenza e runtime agentico
L'inferenza è il punto in cui l'intento architettonico diventa un comportamento visibile all'utente. Questo livello regola la latenza, il throughput, la concorrenza, lo stato della sessione, i modelli di interazione degli strumenti, la qualità in caso di forte domanda e il costo per interazione con il cliente. La sfida non è la capacità, ma l'affidabilità, l'isolamento e la costanza dei costi in condizioni reali: più tenant, domanda in aumento, chiamate agli strumenti che possono fallire e flussi di lavoro che durano pochi minuti anziché millisecondi.
Questo è il livello che determina se un ISV moderno può vendere alle imprese o solo ai primi che l’hanno adottato. Un'applicazione agentica con eccellenti prestazioni del modello ma senza isolamento dei tenant, nessuna durabilità del flusso di lavoro e nessuna cronologia delle chiamate agli strumenti verificabile fallirà una revisione degli acquisti, non perché tecnicamente sbagliata, ma perché non può essere considerata attendibile a livello di sistema.
Project Mantle, il motore di inferenza alla base di Bedrock, affronta l'affidabilità e l'isolamento a livello di infrastruttura. Il routing a livello di servizio consente a una piattaforma di intelligence contrattuale di indirizzare l'estrazione delle clausole rivolte all'utente verso una corsia prioritaria e i riferimenti normativi di base a una corsia flessibile, ottimizzando i costi senza compromettere l'esperienza utente. L'isolamento della coda per cliente significa che un'interruzione del caricamento dei documenti da parte di un tenant non influisce sulla sessione di revisione attiva di un altro tenant. Il Journal, un'innovazione chiave di Mantle, verifica continuamente lo stato di inferenza, in modo che un flusso di lavoro di due diligence che dura da molto tempo e che non supera i 12 minuti venga ripreso al massimo, non da zero.
Amazon Bedrock AgentCore fornisce il runtime di produzione che la maggior parte dei team impiegherebbe altrimenti mesi a creare: distribuzione di agenti containerizzati in qualsiasi framework (LangGraph, CrewAI, Strands Agents, OpenAI Agents SDK), memoria episodica tra sessioni, accesso agli strumenti basato su MCP con applicazione delle policy Cedar e valutazione continua della qualità rispetto a valutatori in tempo reale. Un team SaaS legale che gestisce la propria infrastruttura di agenti in genere coinvolge più ingegneri per gestire la containerizzazione, la gestione delle sessioni e la sicurezza degli strumenti. AgentCore consolida queste preoccupazioni in un livello gestito, liberando quella capacità ingegneristica per la libreria di clausole, la tassonomia dei rischi e le regole politiche specifiche del cliente che consentono di concludere accordi.
Il principio che crea o distrugge questo livello nei cicli di vendita aziendali è la distinzione tra meccanismi e buone intenzioni:
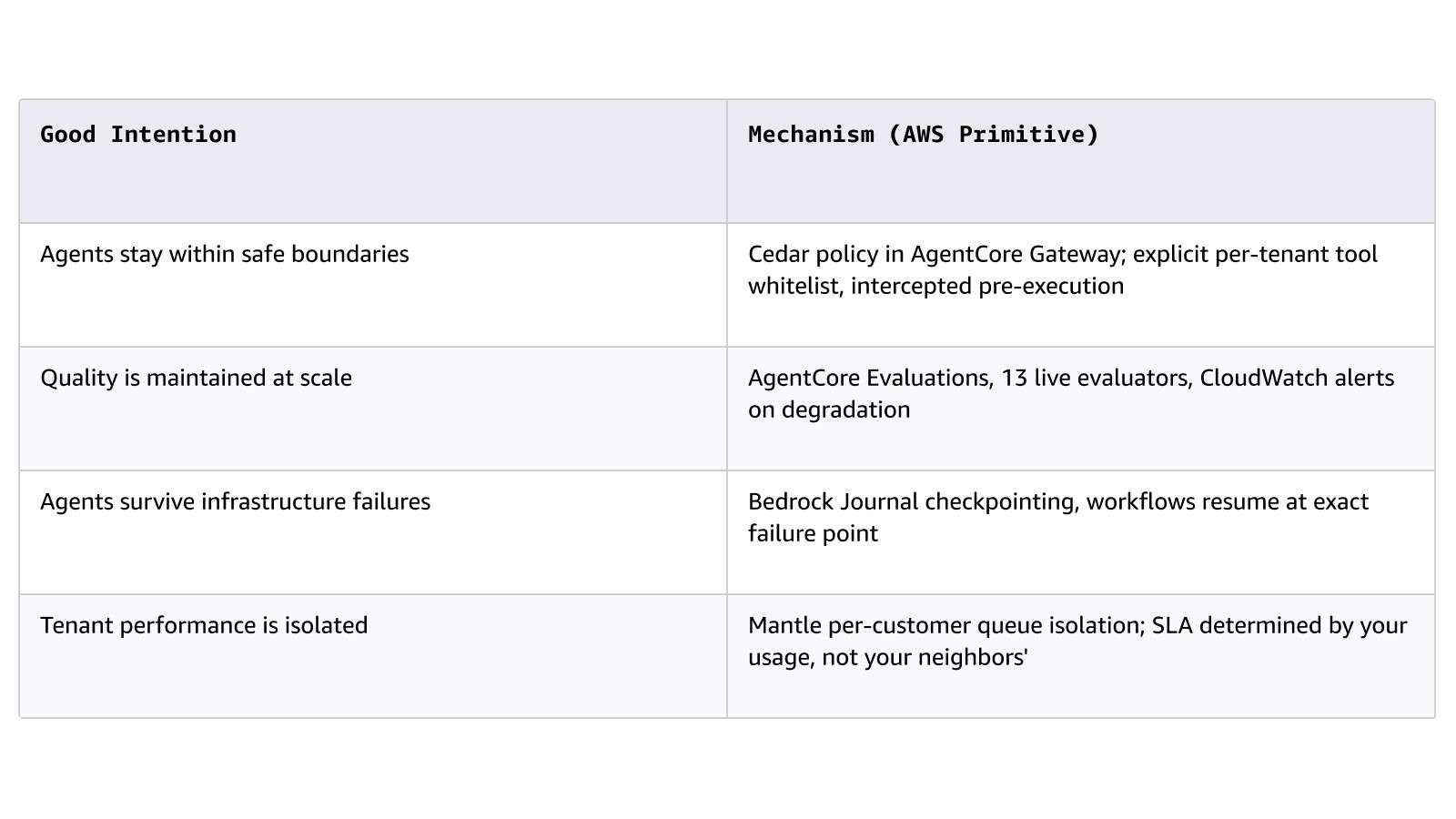
Servizi chiave: Amazon Bedrock (Project Mantle: livelli di servizio, isolamento delle code, Journal), AgentCore (runtime, memoria,gateway, valutazioni, identità), Strands Agents, AWS Step Functions, Amazon Simple Queue Service (SQS).
Punto di partenza: elenca i requisiti aziendali che il tuo agente deve soddisfare e associa ciascuno di essi a un meccanismo concreto, piuttosto che a una strategia suggerita.
Livello 4: orchestrazione e calcolo
Questo è il livello in cui l'IA smette di essere una singola chiamata modello e diventa software. La maggior parte dei prodotti basati sull’IA di produzione sono sistemi in più fasi che recuperano il contesto, richiamano modelli, richiamano strumenti, convalidano gli output, attivano azioni a valle, persistono i risultati e rientrano nei flussi di lavoro in modo asincrono. L'orchestrazione fa parte dell'architettura dell'applicazione principale, non è un dettaglio di implementazione.
Prendi in considerazione una piattaforma SaaS per servizi finanziari che esegue l'analisi dei contratti. Una singola richiesta potrebbe comportare l'acquisizione di documenti, la suddivisione in blocchi, la generazione di embedding, il recupero in base agli accordi precedenti, il ragionamento in più fasi sulle clausole, l'indirizzamento a un revisore umano e l'attivazione di un flusso di lavoro di conformità a valle. Si tratta di un flusso di lavoro applicativo duraturo con logica ramificata, tentativi, transizioni di stato e passaggi asincroni della durata di minuti o ore, non una singola chiamata di inferenza.
Le informazioni strutturali qui riportate rispecchiano ciò che ha reso il serverless computing trasformativo: l'obiettivo non è semplicemente rendere l'infrastruttura più facile da gestire, ma rimuovere intere categorie di gestione dell'infrastruttura. Lambda Managed Instances applica questo principio a una lacuna comune. Alcuni carichi di lavoro richiedono caratteristiche di elaborazione specifiche, memoria elevata per la generazione di embedding, pipeline di preelaborazione dei documenti o inferenza dei modelli che richiedono un uso intensivo della CPU, che sono troppo pesanti per le semplici funzioni serverless ma non giustificano una gestione diretta del parco veicoli. Una startup che elabora migliaia di documenti legali ogni giorno può eseguire tali funzioni su profili di istanze specifici, mentre Lambda gestisce il provisioning, la scalabilità e l'applicazione di patch, mantenendo un'architettura serverless senza ereditare le operazioni del parco EC2.
Per i team che richiedono un controllo più approfondito del runtime, EKS offre la coerenza e il controllo che preferiscono i costruttori di modelli che eseguono server di inferenza personalizzati o i team di piattaforme che standardizzano su Kubernetes.
Amazon DynamoDB si adatta naturalmente come piano di controllo (control-plane) transazionale per lo stato del flusso di lavoro, i metadati delle sessioni, la configurazione dei tenant, le chiavi di idempotenza, i risultati degli strumenti e i riferimenti di audit. È la spina dorsale operativa che mantiene l'applicazione coerente mentre il lavoro si sposta tra servizi e fasi del flusso di lavoro. Questo è diverso dal livello di memoria semantica utilizzato per il recupero.
L’ambiente di sviluppo basato sull'IA Kiro si inserisce in questo livello come acceleratore di distribuzione del software. Il suo ruolo è aiutare i team a tradurre i requisiti del linguaggio naturale in progetti strutturati, specifiche e attività di implementazione, consentendo ai team di muoversi più velocemente mantenendo coerente l'architettura del sistema.
Servizi chiave: Lambda Managed Instances, Lambda Durable Functions, Amazon DynamoDB, Amazon EC2 M9g (Graviton5), AWS Step Functions, Amazon ECS su Graviton5, Amazon EventBridge, Amazon SQS.
Punto di partenza: mappa il tuo flusso di lavoro su carta, identificando ogni fase che potrebbe fallire, ramificarsi o essere eseguita in modo asincrono, prima di scegliere qualsiasi strumento di orchestrazione.
Livello 5: governance, osservabilità e fiducia
È qui che molti stack basati sull’IA si dividono ancora. I team considerano la governance come qualcosa che può essere aggiunto in un secondo momento. Gli agenti con un ampio accesso agli strumenti, un rigore di valutazione limitato e vaghi vincoli basati sui prompt erodono la fiducia e creano barriere all'adozione. Il principio migliore? Meccanismi, non intenzioni.
Gli acquirenti aziendali pongono due domande coerenti prima di adottare un sistema di intelligenza artificiale: puoi dimostrare che i nostri dati non superano mai i confini degli inquilini? E puoi dimostrare che la tua intelligenza artificiale opera entro i limiti dichiarati, con meccanismi che impongono tali limiti e registri che mostrano cosa è successo?
Per un ISV sanitario, ciò significa un agente con ambito HIPAA che non può accedere ai record al di fuori del contesto autorizzato del paziente. Per un fornitore di servizi finanziari SaaS, significa un assistente alla ricerca sugli investimenti le cui chiamate agli strumenti sono vincolate da accordi di accesso ai dati specifici del cliente. Si tratta di requisiti standard per le distribuzioni aziendali regolamentate, non di casi limite.
Bedrock Confidential Computing risolve la questione dell'isolamento dei dati nel piano di inferenza proteggendo i dati durante l'esecuzione e fornendo un limite di runtime con maggiore affidabilità. Servizi come Bedrock, AgentCore, Lambda e S3 possono operare all'interno di un modello di identità unificato, consentendo di applicare la governance degli accessi in modo coerente a tutti i dati, all'invocazione del modello e all'utilizzo degli strumenti degli agenti, senza creare un sistema di autorizzazione separato per ogni livello. Le stesse politiche che regolano l'accesso ai dati regolano anche le chiamate ai modelli e le autorizzazioni degli strumenti. I log delle chiamate agli strumenti diventano quindi registrazioni verificabili del comportamento del sistema.
La governance a questo livello include anche controlli dei dati sensibili ai tenant, il versionameno di modelli e prompt, la tracciabilità tra le chiamate agli strumenti e ai flussi di lavoro, la visibilità dei costi per ambiente o cliente e l'osservabilità end-to-end tra i livelli di applicazione, flusso di lavoro e modello. Questi non sono lussi architettonici. Sono ciò che consente ai team di ragionare sul comportamento del sistema, indagare sugli incidenti al livello corretto e dimostrare la conformità senza ricostruire gli eventi dai log non elaborati.
Per i team che operano in EMEA, il contesto normativo determina molte di queste decisioni architettoniche. I requisiti del GDPR in materia di residenza dei dati indicano che l'isolamento degli inquilini non è solo un requisito di vendita aziendale, ma anche legale. L'isolamento basato sul prefisso S3 e la crittografia per tenant sono i meccanismi pratici che lo soddisfano. L'EU AI Act introduce ulteriori obblighi in materia di trasparenza e supervisione umana per le applicazioni basate sull’IA ad alto rischio, collegandoli direttamente alla registrazione degli audit e alla tracciabilità delle chiamate degli strumenti.
Tieni presente che la disponibilità dei modelli Bedrock, i vettori S3 e AgentCore non sono disponibili in modo uniforme in tutte le regioni AWS EMEA. I team devono verificare la disponibilità nella regione di destinazione prima di impegnarsi in un'architettura specifica.
I team di avvio dovrebbero inoltre tenere presente che alcuni servizi di cui sopra, tra cui S3 Vectors e AgentCore, sono relativamente nuovi per gli ambienti di produzione. Verifica la maturità per il tuo caso d'uso e la tua regione specifici prima di utilizzarli come infrastruttura principale.
Servizi chiave: Amazon Bedrock (elaborazione riservata), AWS Identity and Access Management (IAM), Amazon CloudWatch, AgentCore Policy (Cedar), AgentCore Evaluations, AWS Security Hub.
Punto di partenza: decidi cosa deve dimostrare il tuo registro di controllo agli acquirenti o ai responsabili della conformità. Quindi procedi a ritroso da quello alle politiche e agli strumenti di cui hai bisogno.
Come funziona l'intero sistema
Una richiesta dell'utente entra nell'applicazione. Il runtime autentica la richiesta e risolve il contesto del tenant. La memoria pertinente e la conoscenza del prodotto vengono recuperate dal livello di contesto. Il livello di orchestrazione determina se l'attività è una semplice interazione con il modello o un flusso di lavoro in più fasi. Il livello di inferenza genera o ragiona sulla fase successiva. Le politiche limitano gli strumenti che possono essere invocati. I passaggi di lunga durata consentono di verificare lo stato e il ripristino in modo corretto in caso di errore. Il sistema emette dati di telemetria in ogni fase. Le valutazioni e i cicli di feedback misurano la qualità nel tempo. I team di prodotto utilizzano questi segnali per perfezionare i prompt, aggiornare le politiche, migliorare il recupero o decidere quando è necessaria una personalizzazione più approfondita del modello.
Questo è il pensiero sistemico in pratica. L'architettura vincente è quella che allinea dati, contesto, inferenza, flusso di lavoro, governance e operazioni in un sistema coerente che si comporta bene con la scalabilità dell'azienda.
Per la maggior parte dei team di startup, il punto di ingresso è il livello 1. Ottieni l'isolamento della base per la gestione dei dati e dei tenant subito prima di affrontare gli agenti o l'orchestrazione. I livelli che seguono sono affidabili solo quanto le fondamenta sottostanti.
Costruiscilo. Rendilo tuo.
Uno stack basato sull’IA ben progettato migliora il time to market, l'affidabilità, la fiducia e la disciplina dei costi, non grazie a un singolo servizio, ma perché i livelli lavorano insieme come un sistema coerente. Quando lo stack è orientato ai sistemi, i team possono evolvere la propria architettura man mano che l'azienda cresce senza doverla ricostruire da zero ogni volta che appare una nuova funzionalità.
Come ti è sembrato il contenuto?