Bagaimana konten ini?
- Pelajari
- Bangun agen AI skala besar: Arsitektur referensi berorientasi sistem untuk startup
Bangun agen AI skala besar: Arsitektur referensi berorientasi sistem untuk startup

Setiap generasi pembangun menghadapi perubahan dalam tingkat abstraksi. Bahasa Assembly digantikan oleh bahasa pemrograman tingkat tinggi. Arsitektur monolitik berevolusi menjadi sistem terdistribusi. Infrastruktur on-premise beralih ke platform cloud-native. Kini, perangkat lunak itu sendiri sedang menjadi AI-native, dibentuk oleh model, konteks, agen, dan alur kerja yang adaptif.
Pada re:Invent 2025, Werner Vogels menegaskan momentum ini secara lugas: developer yang berhasil adalah mereka yang menggunakan pola pikir sistem dan membangun dengan tingkat presisi tinggi. Perusahaan yang unggul bukanlah yang mengadopsi AI paling cepat atau memilih model dengan kapabilitas tertinggi. Mereka adalah perusahaan yang memandang sistem secara menyeluruh, yang menyadari bahwa setiap keputusan arsitektural akan berdampak ke lapisan di atas maupun di bawahnya.
Tumpukan AI modern terlalu sering diperlakukan seperti daftar periksa: pilih model, tambahkan pencarian, tambahkan orkestrasi, lalu lakukan deployment. Produk berbasis AI gagal ketika setiap komponennya tampak mengesankan secara terpisah. Produk tersebut berhasil ketika keseluruhan sistem berperilaku secara konsisten dan dapat diprediksi dalam beban kerja dunia nyata, dengan menyeimbangkan kecepatan, keandalan, tata kelola, dan biaya.
Peter DeSantis menyampaikan argumen ini dari sisi infrastruktur pada re:Invent 2025. Lima fondasi yang telah menjadi fokus AWS selama dua puluh tahun — keamanan, ketersediaan, elastisitas, kelincahan, dan biaya — kini menjadi semakin penting, bukan sebaliknya. Beban kerja AI memperbesar setiap kelemahan arsitektur yang ada. Sebuah sistem yang mampu menangani 100 pengguna dapat mengalami kegagalan struktural saat melayani 10.000 pengguna. Model biaya yang terlihat masuk akal pada tahap prototipe bisa menjadi tidak terkendali pada volume produksi. Selain itu, pendekatan tata kelola yang hanya bermodalkan niat baik tidak akan bisa lolos dari audit keamanan perusahaan.
Artikel ini mengulas arsitektur referensi berorientasi sistem bagi para pengembang model dan tim SaaS AI-native yang sedang beralih dari tahap prototipe ke produksi. Arsitektur ini terdiri dari lima lapisan yang akan memberikan nilai optimal ketika berfungsi secara bersamaan.
Berpikir dalam satu kesatuan sistem, bukan sekadar layanan
Kesalahan umum dalam perancangan AI generatif adalah mengoptimalkan setiap lapisan secara terpisah. Satu tim memilih model "terbaik". Tim lain memilih penyimpanan vektor "terbaik". Tim ketiga memilih kerangka kerja orkestrasi hanya berdasarkan kebiasaan. Setiap keputusan mungkin terlihat rasional jika dilihat secara mandiri, namun pengguna akan merasakan performa dari sistem secara keseluruhan: kecepatan pencarian, kualitas respons, ketahanan alur kerja, penegakan kebijakan, isolasi penyewa, serta biaya layanan.
Pada perangkat AI-native, hasil akhir tersebut lahir dari interaksi antarlapisan: bagaimana identitas dan hak akses mengalir ke dalam proses pencarian serta akses alat; bagaimana kebaruan konteks membentuk kualitas hasil; bagaimana proses orkestrasi menangani kegagalan uji coba ulang, status sistem, dan tahapan kerja yang memakan waktu lama; bagaimana observabilitas mencakup panggilan model, alur kerja, dan logika aplikasi; serta bagaimana biaya membengkak di seluruh aspek penyimpanan, inferensi, hingga eksekusi alur kerja.
Tumpukan AI terbaik bukanlah yang memiliki komponen paling mengesankan secara terpisah. Infrastruktur terbaik adalah yang lingkaran umpan baliknya mampu menghasilkan perilaku sistem yang andal dan terprediksi. Dengan sudut pandang tersebut, berikut adalah arsitektur referensi praktis untuk startup AI-native modern di AWS.
Lapisan 1: Fondasi data dan konteks
Setiap produk AI dibangun di atas fondasi data. Lapisan ini menentukan apakah produk tersebut mampu menyelaraskan perilaku AI dengan konteks yang aman, patuh hukum, dan bertahan lama. Dalam sistem produksi, konteks membentuk kualitas pencarian, perilaku model, personalisasi, serta tingkat kepercayaan. Jika lapisan ini rapuh, usang, atau memiliki tata kelola yang buruk, ketidakstabilan tersebut akan menjalar ke lapisan di atasnya.
Ada empat jenis kegagalan yang umum ditemui dalam praktiknya:
- Data acuan utama harus bertahan lebih lama daripada model atau strategi pencarian mana pun. Tim yang mengikat arsitektur datanya terlalu erat pada model penyematan tertentu sering kali harus membangun ulang fondasi tersebut setiap kali model atau pola aksesnya berubah.
- Konteks harus diatur sedemikian rupa demi akses yang cepat dan relevan. Latensi pencarian adalah masalah kualitas produk yang dampaknya akan berlipat ganda di setiap lapisan di atasnya.
- Konteks yang sama yang berfungsi meningkatkan akurasi justru dapat menimbulkan risiko jika data tersebut usang, dibagikan secara berlebihan, atau tidak terisolasi dengan baik antarpenyewa . Batasan tata kelola sangat penting untuk menjaga akurasi dan kepercayaan, bukan sekadar untuk memenuhi kepatuhan hukum.
- Data tidak terstruktur yang berumur panjang, sematan vektor, dan status operasional sistem memiliki fungsi yang berbeda-beda. Oleh karena itu, ketiganya harus tetap dipisahkan secara arsitektur, meskipun ditempatkan di lingkungan yang berdekatan.
Amazon Simple Storage Service (Amazon S3) tetap menjadi acuan utama sistem penyimpanan data untuk dokumen, transkrip, artefak, dan log. Fitur Vektor S3 memperluas fondasi tersebut menjadi penyimpanan vektor bawaan berskala miliaran vektor, dengan tetap menjaga karakteristik elastisitas, ketahanan, dan ketersediaan khas S3. Bagi sebuah ISV yang sedang membangun produk berbasis pengetahuan intensif, konten regulasi, riwayat interaksi pelanggan, serta sematan yang membuatnya dapat dicari, semuanya dapat disimpan di dalam bucket yang sama di bawah kebijakan hak akses yang sama—tanpa memerlukan basis data vektor terpisah yang harus disediakan, ditingkatkan skalanya, dan diamankan secara terpisah.
Tim yang sebelumnya mengelola basis data vektor terpisah harus menangani proses penyediaan, memantau kesehatan indeks, serta merencanakan peningkatan skala secara terisolasi dari infrastruktur mereka yang lain. Fitur Vektor S3 menghilangkan semua beban kerja tersebut sepenuhnya. Fitur ini mewarisi kebijakan hak akses yang sama dengan yang sudah mengatur penyimpanan dokumen Anda. Dengan begitu, tidak ada lagi strategi penskalaan terpisah, tidak ada manajemen kredensial tambahan, dan tidak ada celah titik kegagalan baru yang perlu dipantau.
Penyimpanan vektor khusus tetap memiliki perannya tersendiri. OpenSearch adalah pilihan yang lebih tepat ketika aplikasi perlu menggabungkan pencarian kata kunci yang tepat dengan relevansi semantik, atau ketika performa pencarian harus dioptimalkan pada tingkat latensi yang lebih rendah. Penyematan Multimodal Amazon Nova menjadi sangat penting ketika data yang diolah tidak murni berbentuk teks. Platform kecerdasan kontrak yang memproses pindaian PDF bersama dengan catatan terstruktur, atau platform media yang mengindeks video beserta transkripnya, akan sangat diuntungkan oleh ruang vektor bersama ini dibandingkan harus menggunakan pipeline yang terfragmentasi.
Layanan utama: Amazon S3, Amazon S3 Vectors, Amazon OpenSearch Service (dipercepat oleh GPU), Penyematan Multimodal Amazon Nova, Basis Pengetahuan Amazon Bedrock.
Titik mulai: Simpan dokumen sumber di S3 dengan isolasi penyewa berbasis prefiks sejak hari pertama, lalu konfigurasikan Basis Pengetahuan Bedrock pada bucket tersebut sebelum Anda membangun logika pencarian kustom apa pun.
Lapisan 2: Model dan penyajian
Lapisan ini menentukan bagaimana sistem menghasilkan kecerdasan dan berapa biaya yang diperlukan untuk melakukannya. Keputusan yang diambil bukanlah tentang model mana yang paling mumpuni, melainkan strategi model mana yang mampu memberikan keseimbangan tepat antara akurasi, latensi, biaya, dan kendali untuk setiap tipe beban kerja.
Pembangun aplikasi khusus domain (seperti teknologi hukum, asisten pemrograman, atau pengklasifikasi dokumen keuangan) membutuhkan akurasi hak milik yang tidak dapat diberikan secara konsisten atau dipertahankan secara ekonomis oleh model terdepan yang bersifat umum. ISV modern membutuhkan latensi dan biaya yang terprediksi saat volume permintaan tinggi. Selain itu, pengguna proses inferensi harus menghindari pembayaran harga model mutakhir untuk tugas rutin seperti pengalihan permintaan, peringkasan, atau ekstraksi entitas, dengan model kecil yang telah disesuaikan mampu memberikan performa setara dengan sebagian kecil biaya saja.
Bagi sebagian besar tim, Amazon Bedrock adalah titik awal yang paling tepat. Layanan ini menyediakan platform terkelola yang berisi lebih dari 18 model dengan bobot terbuka beserta model terdepan dari Anthropic—dengan Nova 2 berada di tingkatan dengan rasio biaya kinerja terbaik, tanpa beban operasional untuk mengelola infrastruktur inferensi sendiri. Seiring berkembangnya produk, pertanyaan utamanya pun bergeser: bukan lagi "model mana yang terbaik?", melainkan "seberapa besar keunggulan kompetitif kita berasal dari perilaku model bawaan dibandingkan dengan alur kerja produk milik kita sendiri?" Di sinilah Penyempurnaan Penguatan (RFT) Bedrock dapat membantu meningkatkan akurasi model dasar untuk tugas spesifik pada domain tertentu. Hal ini membuat varian model yang lebih kecil, lebih cepat, dan lebih hemat biaya menjadi sangat praktis untuk digunakan dalam skala produksi massal.
Bagi tim yang membutuhkan kendali lebih besar, Amazon SageMaker AI adalah tingkatan terkelola, tetapi terkontrol bagi para pembangun yang perlu mendalami lebih jauh proses penyempurnaan, evaluasi, MLOps, dan deployment kustom. Layanan ini juga menjadi pilihan yang lebih cocok ketika perilaku model kepemilikan merupakan bagian dari produk itu sendiri. Tim yang membutuhkan pola runtime yang tidak disediakan oleh layanan yang sepenuhnya terkelola, seperti pengaliran dua arah untuk pengalaman berbasis suara asli, akan mendapati SageMaker sebagai pilihan yang lebih praktis. Mengalirkan audio masuk dan mengeluarkan transkrip sebagian secara langsung membuat interaksi terasa lancar, alih-alih terbatas oleh hambatan jeda waktu.
Bagi tim yang membangun model fondasi dari awal, EC2 Trn3 (Trainium3) menawarkan biaya pelatihan 40 persen lebih rendah dan hasil token 5x lebih tinggi per megawatt, dengan integrasi PyTorch asli, sehingga tim dapat melatih dan melakukan deployment tanpa mengubah kode model. Amazon Elastic Kubernetes Service (EKS) berada di ujung terjauh dari spektrum tersebut untuk tim yang membutuhkan kendali runtime sepenuhnya atau tumpukan penyajian khusus.
Keputusan di tingkat model menetapkan batas biaya minimum untuk sistem. Jika setiap permintaan dialihkan secara otomatis ke model terdepan, biaya akan membengkak dengan cepat seiring ditambahkannya proses pencarian, agen, dan alur kerja multiproses. Strategi model yang disiplin menjaga agar kapabilitas tetap selaras dengan kebutuhan tugas, serta mencegah biaya model melampaui keekonomian produk secara diam-diam.
Halaman harga Bedrock menyediakan perbandingan biaya antarmodel saat ini untuk token input dan output. Menjalankan kalkulasi ini berdasarkan perkiraan volume permintaan Anda merupakan langkah yang sangat berguna sebelum memfinalisasi arsitektur Anda.
Layanan utama: Amazon Bedrock (inferensi nirserver, tingkat layanan), keluarga Amazon Nova 2, Bedrock RFT, SageMaker AI, EC2 Trn3 (Trainium3).
Titik mulai: Identifikasi beban kerja mana yang benar-benar memerlukan model terdepan dan mana yang dapat ditangani oleh alternatif yang lebih kecil atau lebih murah, karena perbedaan biaya tersebut akan terakumulasi dengan cepat seiring bertambahnya skala penggunaan.
Lapisan 3: Inferensi dan runtime agentik
Inferensi adalah tempat intensi arsitektur berubah menjadi perilaku yang terlihat oleh pengguna. Lapisan ini mengatur latensi, throughput, konkurensi, status sesi, pola interaksi alat, kualitas di bawah lonjakan permintaan, serta biaya per interaksi pelanggan. Tantangannya bukanlah kemampuan, melainkan keandalan, isolasi, dan konsistensi biaya di bawah kondisi sebenarnya: beberapa penyewa, permintaan yang melonjak tiba-tiba, panggilan alat yang bisa gagal, serta alur kerja yang berjalan selama hitungan menit, bukan milidetik.
Ini adalah lapisan yang menentukan apakah ISV modern dapat menjual produknya ke perusahaan besar atau hanya kepada pengguna awal. Aplikasi berbasis agen dengan performa model yang sangat baik, tetapi tanpa isolasi penyewa, tanpa ketahanan alur kerja, dan tanpa riwayat panggilan alat yang dapat diaudit, akan gagal dalam tinjauan pengadaan, bukan karena secara teknis salah, melainkan karena tidak dapat dipercaya pada tingkat sistem.
Project Mantle, mesin inferensi yang mendasari Bedrock, menangani keandalan dan isolasi pada tingkat infrastruktur. Perutean tingkat layanan memungkinkan platform kecerdasan kontrak mengarahkan ekstraksi klausul yang menghadap pengguna ke jalur prioritas, dan referensi silang regulasi di latar belakang ke jalur fleksibel, mengoptimalkan biaya tanpa menurunkan pengalaman pengguna. Isolasi antrean per pelanggan berarti lonjakan unggahan dokumen oleh satu penyewa tidak akan memengaruhi sesi peninjauan aktif milik penyewa lain. Journal, sebuah inovasi utama dalam Mantle, mencatat titik pemulihan status inferensi secara berkelanjutan sehingga alur kerja uji tuntas yang berjalan lama dan gagal di menit ke-12 dapat dilanjutkan tepat dari menit ke-12 tersebut, bukan dari awal.
Amazon Bedrock AgentCore menyediakan runtime produksi yang biasanya membutuhkan waktu berbulan-bulan bagi tim lain untuk membangunnya sendiri: deployment agen berbasis kontainer di berbagai kerangka kerja (LangGraph, CrewAI, Strands Agents, OpenAI Agents SDK), memori episodik lintas sesi, akses alat berbasis MCP dengan penegakan kebijakan Cedar, serta evaluasi kualitas berkelanjutan terhadap evaluator langsung. Sebuah tim SaaS hukum yang menjalankan infrastruktur agen mereka sendiri biasanya membutuhkan banyak rekayasawan untuk mengelola kontainerisasi, penanganan sesi, dan keamanan alat. AgentCore menyatukan seluruh kebutuhan tersebut ke dalam lapisan terkelola, sehingga membebaskan kapasitas rekayasa tersebut untuk fokus pada pustaka klausul, taksonomi risiko, dan aturan kebijakan khusus klien yang memenangkan kesepakatan bisnis.
Prinsip yang menentukan keberhasilan atau kegagalan lapisan ini dalam siklus penjualan perusahaan besar adalah perbedaan antara mekanisme dan niat baik:
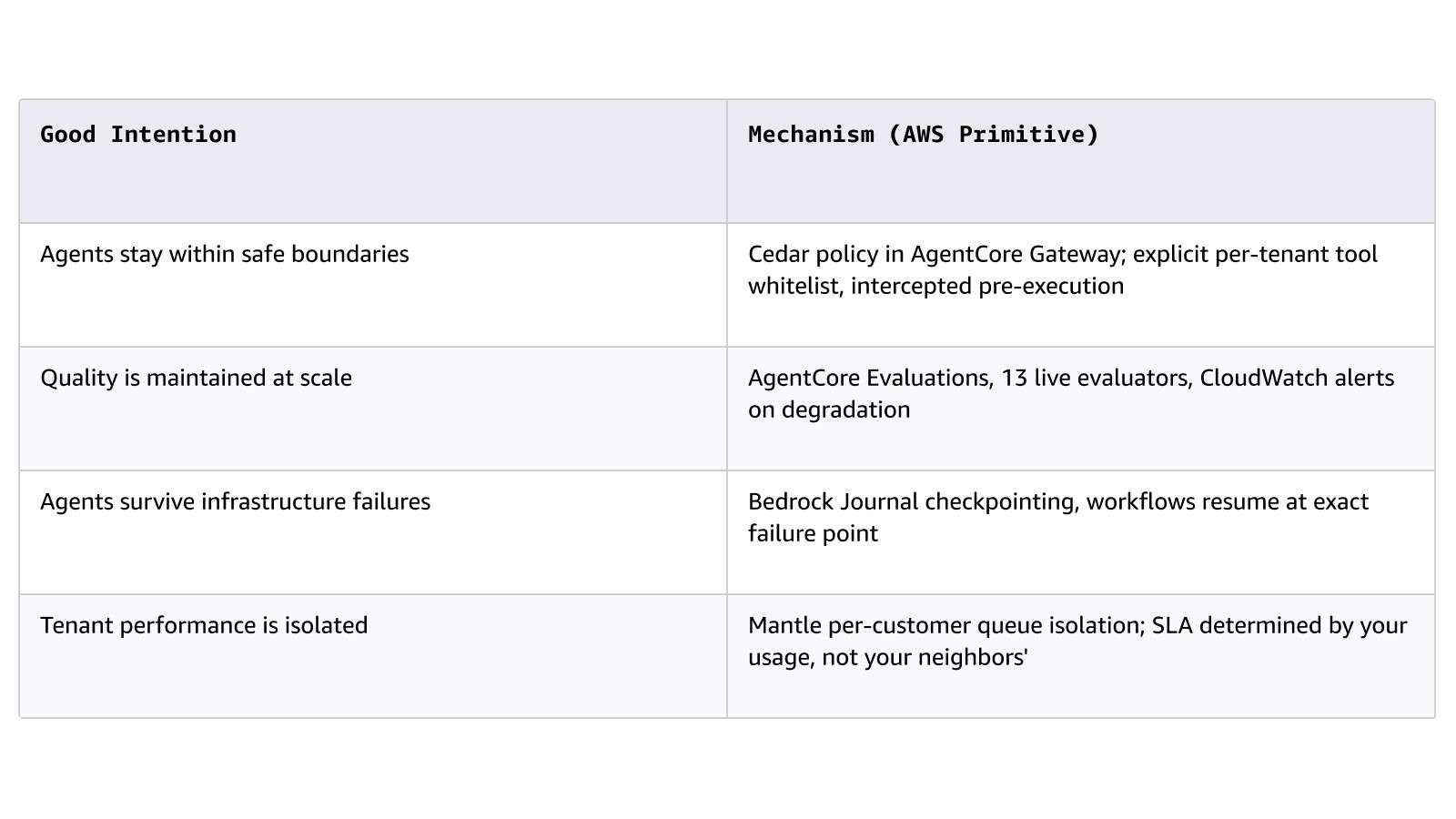
Layanan utama: Amazon Bedrock (Project Mantle: tingkat layanan, isolasi antrean, Journal), AgentCore (Runtime, Memori, Gateway, Evaluasi, Identitas), Strands Agents, AWS Step Functions, Amazon Simple Queue Service (SQS).
Titik mulai: Buat daftar persyaratan perusahaan besar yang harus dipenuhi oleh agen Anda dan petakan masing-masing ke dalam mekanisme yang konkret, alih-alih menggunakan strategi pembuat prompt.
Lapisan 4: Orkestrasi dan komputasi
Ini adalah lapisan tempat AI berhenti menjadi sekadar satu panggilan model dan berubah menjadi perangkat lunak. Sebagian besar produk AI siap produksi adalah sistem multiproses yang mengambil konteks, menginvokasi model, menjalankan alat, memvalidasi hasil, memicu tindakan lanjutan, menyimpan hasil secara permanen, dan masuk kembali ke alur kerja secara asinkron. Orkestrasi adalah bagian dari arsitektur aplikasi inti, bukan sekadar detail implementasi.
Bayangkan sebuah platform SaaS layanan keuangan yang melakukan analisis kontrak. Satu permintaan saja dapat melibatkan penyerapan dokumen, pemotongan teks, pembuatan sematan, pencarian terhadap perjanjian sebelumnya, penalaran multiproses atas klausul-klausul, pengalihan ke peninjau manusia, dan pemicuan alur kerja kepatuhan lanjutan. Itu merupakan alur kerja aplikasi yang tangguh dengan logika percabangan, percobaan ulang, transisi status, dan langkah-langkah asinkron yang memakan waktu bermenit-menit atau berjam-jam, bukan sekadar satu panggilan inferensi tunggal.
Wawasan struktural di sini mencerminkan apa yang membuat komputasi nirserver menjadi transformatif: tujuannya bukan sekadar membuat infrastruktur lebih mudah dikelola, melainkan untuk menghilangkan seluruh kategori manajemen infrastruktur. Instans yang Dikelola Lambda menerapkan prinsip tersebut pada celah kebutuhan yang umum terjadi. Beberapa beban kerja memerlukan karakteristik komputasi tertentu, seperti memori tinggi untuk pembuatan instruksi sematan, jalur pemrosesan awal dokumen, atau inferensi model yang padat CPU, yang terlalu berat untuk fungsi nirserver biasa, tetapi tidak memerlukan manajemen armada server secara langsung. Sebuah startup yang memproses ribuan dokumen hukum setiap hari dapat menjalankan fungsi-fungsi tersebut pada profil instans spesifik, sementara Lambda mengelola penyediaan, penskalaan, dan perbaikan sistem, sehingga arsitektur tanpa server tetap terjaga tanpa perlu mengambil alih operasional armada EC2.
Bagi tim yang memerlukan kontrol runtime yang lebih mendalam, EKS menyediakan konsistensi dan kendali yang disukai oleh para pembangun model yang menjalankan server inferensi kustom atau oleh tim platform yang melakukan standarisasi pada Kubernetes.
Amazon DynamoDB sangat cocok sebagai bidang kontrol transaksional untuk status alur kerja, metadata sesi, konfigurasi penyewa, kunci idempotensi, hasil alat, dan referensi audit. Ini adalah tulang punggung operasional yang menjaga koherensi aplikasi saat pekerjaan berpindah antarlayanan dan tahapan alur kerja. Lapisan ini berbeda dari lapisan memori semantik yang digunakan untuk pencarian.
Lingkungan pengembangan berbasis AI Kiro masuk ke dalam lapisan ini sebagai akselerator pengiriman perangkat lunak. Perannya adalah membantu tim menerjemahkan persyaratan bahasa alami menjadi desain terstruktur, spesifikasi, dan tugas implementasi, sehingga tim dapat bergerak lebih cepat sambil menjaga arsitektur sistem tetap koheren.
Layanan kunci: Instans yang Dikelola Lambda, Fungsi Persistensi Lambda, Amazon DynamoDB, Amazon EC2 M9g (Graviton5), AWS Step Functions, Amazon ECS di Graviton5, Amazon EventBridge, Amazon SQS.
Titik mulai: Petakan alur kerja Anda di atas kertas, identifikasi setiap langkah yang dapat gagal, bercabang, atau berjalan secara asinkron, sebelum memilih alat bantu orkestrasi apa pun.
Lapisan 5: Tata kelola, observabilitas, dan kepercayaan
Di sinilah banyak tumpukan teknologi AI masih mengalami kegagalan. Banyak tim memperlakukan tata kelola sebagai sesuatu yang bisa ditambahkan belakangan. Agen dengan akses alat yang luas, pengujian yang kurang ketat, dan batasan samar yang hanya berbasis prompt dapat mengikis kepercayaan dan menciptakan hambatan adopsi. Prinsip yang lebih baik? Mekanisme nyata, bukan sekadar niat baik.
Pembeli dari kalangan perusahaan besar selalu mengajukan dua pertanyaan yang sama sebelum mengadopsi sistem AI: Dapatkah Anda menunjukkan bahwa data kami tidak pernah melewati batas antarpenyewa? Dan dapatkah Anda membuktikan bahwa AI Anda beroperasi dalam batasan yang Anda klaim, dilengkapi dengan mekanisme yang menegakkan batasan tersebut serta log yang menunjukkan apa yang telah terjadi?
Bagi sebuah ISV layanan kesehatan, ini berarti agen yang tercakup dalam cakupan HIPAA tidak dapat mengakses rekam medis di luar konteks resmi pasien. Bagi penyedia SaaS layanan keuangan, ini berarti asisten riset investasi yang panggilan alatnya dibatasi oleh perjanjian akses data khusus klien. Ini merupakan persyaratan standar untuk deployment di perusahaan besar yang teregulasi, bukan kasus pengecualian.
Komputasi Rahasia Bedrock menjawab pertanyaan isolasi data pada bidang inferensi dengan melindungi data selama eksekusi dan menyediakan batas runtime dengan jaminan yang lebih tinggi. Layanan termasuk Bedrock, AgentCore, Lambda, dan S3 dapat beroperasi dalam model identitas terpadu, memungkinkan tata kelola akses diterapkan secara konsisten di seluruh data, invokasi model, dan penggunaan alat agen, tanpa perlu membangun sistem otorisasi terpisah untuk setiap lapisan. Kebijakan yang sama yang mengatur akses data juga mengatur panggilan model dan izin alat. Log panggilan alat kemudian menjadi catatan perilaku sistem yang dapat diaudit.
Tata kelola pada lapisan ini juga mencakup kontrol data yang mengenali penyewa, penentuan versi model dan prompt, keterlacakan di seluruh panggilan alat dan alur kerja, visibilitas biaya berdasarkan lingkungan atau pelanggan, serta observabilitas ujung ke ujung di seluruh lapisan aplikasi, alur kerja, dan model. Ini semua bukanlah kemewahan arsitektur. Hal-hal inilah yang memungkinkan tim memahami perilaku sistem, menyelidiki insiden pada lapisan yang tepat, dan menunjukkan kepatuhan tanpa harus menyusun ulang rangkaian kejadian dari log mentah.
Bagi tim yang beroperasi di wilayah EMEA, konteks regulasi memengaruhi beberapa keputusan arsitektur ini. Persyaratan GDPR seputar residensi data mengartikan bahwa isolasi penyewa bukan sekadar kebutuhan penjualan perusahaan besar, melainkan kewajiban hukum. Isolasi berbasis prefiks S3 dan enkripsi per penyewa adalah mekanisme praktis yang memenuhi tuntutan tersebut. Undang-Undang AI Uni Eropa memperkenalkan kewajiban lebih lanjut terkait transparansi dan pengawasan manusia untuk aplikasi AI berisiko tinggi, yang dipetakan secara langsung ke pencatatan audit dan keterlacakan panggilan alat.
Perhatikan bahwa ketersediaan model Bedrock, Vektor S3, dan AgentCore tidak seragam di semua region AWS EMEA. Tim harus memverifikasi ketersediaan di region target mereka sebelum berkomitmen pada arsitektur tertentu.
Tim startup juga harus memperhatikan bahwa beberapa layanan yang disebutkan di atas, termasuk Vektor S3 dan AgentCore, relatif baru dalam lingkungan produksi. Validasi tingkat kematangan layanan tersebut untuk kasus penggunaan dan region spesifik Anda sebelum menetapkannya sebagai infrastruktur inti.
Layanan utama: Amazon Bedrock (komputasi rahasia), AWS Identity and Access Management (IAM), Amazon CloudWatch, Kebijakan AgentCore (Cedar), Evaluasi AgentCore, AWS Security Hub.
Titik mulai: Tentukan apa yang perlu dibuktikan oleh log audit Anda kepada pembeli atau petugas kepatuhan. Kemudian, susun langkah mundur dari target tersebut untuk menentukan kebijakan dan alat bantu yang perlu Anda siapkan.
Bagaimana sistem yang utuh berpadu
Sebuah permintaan pengguna masuk ke dalam aplikasi. Runtime mengautentikasi permintaan tersebut dan menyelesaikan konteks penyewa. Memori dan wawasan produk yang relevan diambil dari lapisan konteks. Lapisan orkestrasi menentukan apakah tugas tersebut merupakan interaksi model sederhana atau alur kerja multiproses. Lapisan inferensi menghasilkan atau menalar langkah berikutnya. Kebijakan membatasi alat mana saja yang boleh diinvokasi. Langkah-langkah yang berjalan lama mencatat titik pemulihan status dan pulih dengan aman saat terjadi kegagalan. Sistem memancarkan telemetri di setiap tahapan. Evaluasi dan siklus umpan balik mengukur kualitas dari waktu ke waktu. Tim produk menggunakan sinyal-sinyal tersebut untuk menyempurnakan prompt, memperbarui kebijakan, meningkatkan pencarian, atau memutuskan kapan kustomisasi model yang lebih mendalam diperlukan.
Itulah penerapan pemikiran sistem dalam praktik sebenarnya. Arsitektur pemenang adalah arsitektur yang menyelaraskan data, konteks, inferensi, alur kerja, tata kelola, dan operasional menjadi sebuah sistem terpadu yang bekerja dengan baik seiring perkembangan skala perusahaan.
Bagi sebagian besar tim startup, titik awalnya adalah Lapisan 1. Selesaikan fondasi data dan isolasi penyewa Anda dengan benar sebelum menangani agen atau orkestrasi. Keandalan lapisan berikutnya sangat bergantung pada seberapa kokoh fondasi yang menopangnya di bawah.
Bangun. Kuasai.
Tumpukan AI yang dirancang dengan baik meningkatkan waktu peluncuran ke pasar, keandalan, kepercayaan, dan disiplin biaya. Hal ini terjadi bukan karena layanan tunggal, melainkan karena lapisan-lapisan di dalamnya bekerja bersama sebagai sebuah sistem yang padu. Ketika tumpukan teknologi tersebut berorientasi pada sistem, tim dapat mengembangkan arsitektur mereka seiring pertumbuhan bisnis tanpa harus membangun ulang dari awal setiap kali ada kemampuan baru yang muncul.
Bagaimana konten ini?