Wie war dieser Inhalt?
- Lernen
- Skalierbare KI-Agenten entwickeln: Eine systemorientierte Referenzarchitektur für Startups
Skalierbare KI-Agenten entwickeln: Eine systemorientierte Referenzarchitektur für Startups

Jede Generation von Entwicklern steht vor einem Abstraktionswandel. Die Assemblersprache ist den Sprachen höherer Ebenen gewichen. Monolithen entwickelten sich zu verteilten Systemen. Die On-Premises-Infrastruktur wich cloudnativen Plattformen. Jetzt wird die Software selbst KI-nativ und wird von Modellen, Kontext, Agenten und adaptiven Workflows geprägt.
Auf der re:Invent 2025 hat Werner Vogels diesen Moment klar umrissen: Erfolgreiche Entwickler konzipieren Systemen und entwickeln mit Präzision. Die Unternehmen, die gewinnen, sind nicht diejenigen, die KI am frühesten eingeführt oder das leistungsfähigste Modell ausgewählt haben. Sie sind diejenigen, die komplette Systeme konzipieren und verstehen, dass sich jede architektonische Entscheidung durch die darüber- und darunterliegenden Ebenen zieht.
Der moderne KI-Stack wird zu oft als Checkliste behandelt: Modell auswählen, Abruf anhängen, Orchestrierung hinzufügen, bereitstellen. KI-gestützte Produkte versagen, obwohl Komponenten für sich genommen beeindruckend aussehen. Sie sind erfolgreich, wenn sich das System unter realer Belastung vorhersehbar verhält und dabei Geschwindigkeit, Zuverlässigkeit, Steuerung und Kosten in Einklang bringt.
Peter DeSantis hat dieses Argument auf der re:Invent 2025 von der Infrastrukturseite aus vorgebracht. Die fünf Grundlagen, von denen AWS seit zwanzig Jahren besessen ist – Sicherheit, Verfügbarkeit, Elastizität, Agilität und Kosten – sind jetzt noch wichtiger, nicht weniger wichtig. KI-Workloads tragen zu jeder architektonischen Schwäche bei. Ein System, das auf 100 Benutzer skaliert werden kann, kann bei 10 000 Benutzern strukturell ausfallen. Ein Kostenmodell, das in der Prototypenphase vernünftig aussieht, kann bei Produktionsvolumen unhaltbar werden. Und ein auf guten Absichten beruhender Governance-Ansatz kann eine Überprüfung der Unternehmenssicherheit nicht überstehen.
Dieser Artikel beschreibt eine systemorientierte Referenzarchitektur für Modellentwickler und KI-native SaaS-Teams auf dem Weg vom Prototyp zur Produktion. Diese Referenzarchitektur besteht aus fünf Ebenen, die ihren vollen Nutzen entfalten, wenn sie zusammenarbeiten.
Denken Sie über Systeme, nicht nur Services.
Ein häufiger Fehler beim generativen KI-Design besteht darin, jede Ebene unabhängig zu optimieren. Ein Team wählt das „beste“ Modell aus. Ein anderes wählt den „besten“ Vektorspeicher aus. Ein Drittes wählt ein Orchestrierungs-Framework, das auf Vertrautheit basiert. Jede Entscheidung mag für sich genommen rational erscheinen, aber die Benutzer erleben das Verhalten des gesamten Systems: Abrufgeschwindigkeit, Reaktionsqualität, Dauerhaftigkeit der Arbeitsabläufe, Durchsetzung von Richtlinien, Isolierung der Mandanten und Servicekosten.
Bei KI-nativer Software ergeben sich diese Ergebnisse aus Interaktionen zwischen Ebenen: wie Identität und Berechtigungen in den Abruf und den Toolzugriff einfließen; wie die Aktualität des Kontextes die Ausgabequalität beeinflusst; wie die Orchestrierung Wiederholungsversuche, Status und lang andauernde Schritte behandelt; wie die Beobachtbarkeit Modellaufrufe, Workflows und Anwendungslogik umfasst; wie sich die Kosten zwischen Speicher, Inferenz und Workflow-Ausführung erhöhen.
Der beste KI-Stack ist nicht der mit den individuell beeindruckendsten Teilen. Es ist derjenige, dessen Rückkopplungsschleifen zu einem zuverlässigen, vorhersehbaren Systemverhalten führen. Vor diesem Hintergrund finden Sie hier eine praktische Referenzarchitektur für moderne KI-native Startups in AWS.
Ebene 1: Daten- und Kontextgrundlage
Jedes KI-Produkt basiert auf einer Datengrundlage. Diese Ebene bestimmt, ob das Produkt das KI-Verhalten in einem dauerhaften, kontrollierten Kontext verankern kann. In Produktionssystemen beeinflusst der Kontext die Abrufqualität, das Modellverhalten, die Personalisierung und das Vertrauen. Wenn diese Schicht spröde, abgestanden oder schlecht strukturiert ist, breitet sich die Instabilität nach oben aus.
In der Praxis sind vier Ausfallarten üblich:
- Source-of-Truth-Daten müssen jedes Modell oder jede Abrufstrategie überleben. Teams, die ihre Datenarchitektur zu fest an ein bestimmtes Einbettungsmodell binden, bauen die Grundlage häufig jedes Mal neu auf, wenn sich das Modell oder das Zugriffsmuster ändert.
- Der Kontext muss für einen schnellen, relevanten Zugriff organisiert sein. Die Latenz beim Abrufen ist ein Problem mit der Produktqualität, das sich auf jeder darüber liegenden Ebene verstärkt.
- Derselbe Kontext, der die Genauigkeit verbessert, kann zu Risiken führen, wenn er veraltet, zu stark geteilt oder schlecht von allen Mandanten isoliert wird. Geregelte Grenzen sind für Genauigkeit und Vertrauen unerlässlich, nicht nur für die Compliance.
- Langlebige unstrukturierte Daten, Vektoreinbettungen und Betriebszustand dienen unterschiedlichen Zwecken und sollten architektonisch unterschiedlich bleiben, auch wenn sie nahe beieinander liegen.
Amazon Simple Storage Service (Amazon S3) bleibt das kanonische Aufzeichnungssystem für Dokumente, Transkripte, Artefakte und Protokolle. S3-Vektoren erweitert diese Grundlage um systemeigenen Vektorspeicher im Maßstab von Milliarden von Vektoren, wobei das Elastizitäts-, Haltbarkeits- und Verfügbarkeitsmodell von S3 erhalten bleibt. Für einen ISV, der ein wissensintensives Produkt entwickelt, können regulatorische Inhalte, der Verlauf der Kundeninteraktionen und die Einbettungen, die beide durchsuchbar machen, unter denselben Zugriffsrichtlinien gespeichert werden, ohne dass eine separate Vektordatenbank bereitgestellt, skaliert und gesichert werden muss.
Ein Team, das zuvor eine separate Vektordatenbank verwaltete, kümmerte sich um die Bereitstellung, die Überwachung des Indexzustands und die Planung der Skalierung von Ereignissen getrennt von der übrigen Infrastruktur. S3 Vectors entfernt das vollständig. Es erbt dieselben Zugriffsrichtlinien, die bereits für den Dokumentenspeicher gelten. Es gibt also keine separate Skalierungsstrategie, keine zusätzliche Verwaltung von Anmeldeinformationen und keine neue Fehleroberfläche, die überwacht werden muss.
Spezialisierte Vektorspeicher haben immer noch einen Platz. OpenSearch ist besser geeignet, wenn die Anwendung exakte Schlüsselwort-Übereinstimmung mit semantischer Relevanz kombinieren muss oder wenn die Abrufleistung bei niedrigerer Latenz optimiert werden muss. Amazon Nova Multimodal Embeddings wird wichtig, wenn es sich bei Daten nicht um reine Textdaten handelt. Eine Contract-Intelligence-Plattform, die gescannte PDFs zusammen mit strukturierten Datensätzen verarbeitet, oder eine Medienplattform, die Videos mit Transkripten indexiert, profitieren von einer gemeinsamen Vektorumgebung statt fragmentierter Pipelines.
Wichtige Services: Amazon S3, Amazon S3 Vectors, Amazon OpenSearch Service (GPU-beschleunigt), Amazon Nova Multimodal Embeddings, Amazon Bedrock Knowledge Bases.
Ausgangspunkt: Speichern Sie Quelldokumente vom ersten Tag an in S3 mit präfixbasierter Mandantenisolierung und konfigurieren Sie dann eine Bedrock-Wissensdatenbank für diesen Bucket, bevor Sie eine benutzerdefinierte Abruflogik erstellen.
Ebene 2: Modellieren und Bereitstellen
Diese Ebene bestimmt, wie das System Informationen generiert und was es kostet, dies zu tun. Entscheidend ist nicht, welches Modell am leistungsfähigsten ist, sondern welche Modellstrategie für jeden Workload-Typ das richtige Gleichgewicht zwischen Genauigkeit, Latenz, Kosten und Kontrolle bietet.
Ein Domain-spezifischer Builder (Legaltech, Coding-Assistent oder Finanzdokumente-Klassifizierer) benötigt proprietäre Genauigkeit, die ein generisches Frontier-Modell nicht konsistent liefern oder wirtschaftlich aufrechterhalten kann. Ein moderner ISV benötigt vorhersehbare Latenz und Kosten beim Abfragevolumen. Und wer Inferenz nutzt, muss vermeiden, für Routineaufgaben wie Routing, Zusammenfassung oder Entitätsanalyse, bei denen ein kleineres, optimiertes Modell die gleiche Leistung zu einem Bruchteil der Kosten leistet, zu zahlen
Für die meisten Teams ist Amazon Bedrock der richtige Ausgangspunkt, eine verwaltete Palette von mehr als 18 Modellen mit offenem Gewicht neben den Frontier-Modellen von Anthropic, wobei Nova 2 in der besten Preis-/Leistungsklasse ist, ohne den Betrieb einer Inferenzinfrastruktur zu belasten. Je reifer das Produkt wird, desto mehr stellt sich die richtige Frage: „Welches Modell ist das beste?“ zu „Wie viel unseres Wettbewerbsvorteils ergibt sich aus dem Verhalten eines proprietären Modells im Vergleich zu firmeneigenen Produktabläufen?“ Bedrock Reinforcement Fine-Tuning (RFT) kann die Genauigkeit bei Domain-spezifischen Aufgaben im Vergleich zu Basismodellen verbessern, sodass kleinere, schnellere und kostengünstigere Varianten für die Serienproduktion praktikabel sind.
Für Teams, die mehr Kontrolle benötigen, ist Amazon SageMaker AI die verwaltete, aber kontrollierte Stufe für Entwickler, die sich eingehender mit Feinabstimmung, Evaluierung, MLOps und benutzerdefinierter Bereitstellung befassen müssen. Es ist auch besser geeignet, wenn das Verhalten eines proprietären Modells Teil des Produkts selbst ist. Teams, die Laufzeitmuster benötigen, die eine vollständig verwaltete Oberfläche nicht zur Verfügung stellt, wie z. B. bidirektionales Streaming für sprachnative Erlebnisse, werden SageMaker für die praktischere Wahl halten. Durch das Hineinstreamen von Audio und teilweises Auslesen von Transkripten fühlt sich die Interaktion flüssig an und ist nicht latenzgebunden.
Für Teams, die Basismodelle von Grund auf neu erstellen, bietet EC2 Trn3 (Trainium3) 40 % niedrigere Trainingskosten und fünfmal höhere Output-Token pro Megawatt mit nativer PyTorch, sodass Teams trainieren und bereitstellen können, ohne den Modellcode zu ändern. Amazon Elastic Kubernetes Service (EKS) befindet sich am anderen Ende des Spektrums für Teams, die eine vollständige Laufzeitkontrolle oder spezielle Serving-Stacks benötigen.
Entscheidungen auf Modellebene legen die Kostenuntergrenze für das System fest. Wenn für jede Anfrage standardmäßig ein Frontier-Modell verwendet wird, steigen die Kosten schnell, da Abruf, Agenten und mehrstufige Workflows hinzukommen. Eine disziplinierte Modellstrategie sorgt dafür, dass die Fähigkeiten an den Aufgabenanforderungen ausgerichtet sind, und verhindert, dass die Modellkosten die Produktökonomie unbemerkt übersteigen.
Die Preisseite von Bedrock bietet einen aktuellen Modell-für-Modell-Kostenvergleich für Eingabe- und Ausgabe-Token. Es ist ein lohnenswerter Schritt, diese Berechnungen anhand Ihres erwarteten Anforderungsvolumens durchzuführen, bevor Sie Ihre Architektur fertigstellen.
Wichtige Services: Amazon Bedrock (Serverless-Inferenz, Servicestufen), Amazon Nova 2-Familie, Bedrock RFT, SageMaker AI, EC2 Trn3 (Trainium3).
Ausgangspunkt: Identifizieren Sie, für welche Ihrer Workloads ein Frontier-Modell erforderlich ist und welche mit einer kleineren oder billigeren Alternative bewältigt werden könnten, da sich der Kostenunterschied im großen Maßstab schnell vergrößert.
Ebene 3: Inferenz und agentische Laufzeit
Bei Inferenz wird aus architektonischer Absicht ein für den Benutzer sichtbares Verhalten. Auf dieser Ebene werden Latenz, Durchsatz, Parallelität, Sitzungsstatus, Muster der Werkzeuginteraktionen, Qualität bei starker Nachfrage und Kosten pro Kundeninteraktion gesteuert. Die Herausforderung liegt nicht in der Kapazität, sondern in der Zuverlässigkeit, Isolierung und Kostenkonsistenz unter realen Bedingungen: mehrere Mandanten, hohe Nachfrage, fehlgeschlagene Tool-Aufrufe und Workflows, die Minuten statt Millisekunden dauern.
Dies ist die Ebene, die bestimmt, ob ein moderner ISV an Unternehmen oder nur an Erstanwender verkaufen kann. Eine Agentenanwendung mit hervorragender Modellleistung, aber ohne Mandantenisolierung, ohne Dauerhaftigkeit des Workflows und ohne überprüfbare Historie der Geräteabrufe besteht bei einer Beschaffungsprüfung nicht, weil sie technisch falsch ist, sondern weil ihr auf Systemebene nicht vertraut werden kann.
Project Mantle, die Bedrock zugrunde liegende Inferenzmaschine, befasst sich mit Zuverlässigkeit und Isolation auf Infrastrukturebene. Mithilfe von Service Tier Routing kann eine Contract-Intelligence-Plattform die Extraktion nutzerorientierter Klauseln an eine Prioritätsspur weiterleiten und Hintergrundinformationen an eine flexible Leitung weiterleiten, wodurch die Kosten optimiert werden, ohne die Benutzererfahrung zu beeinträchtigen. Die Isolierung der Warteschlangen pro Kunde bedeutet, dass ein übermäßiger Anstieg der Uploads von Dokumenten durch einen Mandanten keinen Einfluss auf die aktive Prüfungssitzung eines anderen Mandanten hat. Das Journal, eine wichtige Innovation innerhalb von Mantle, überprüft kontinuierlich Inferenzdaten, sodass ein lang andauernder Due-Diligence-Workflow, der nach 12 Minuten versagt, nach der 12-Minuten-Marke wieder aufgenommen wird und nicht von Anfang an.
Amazon Bedrock AgentCore bietet die Produktionslaufzeit, die die meisten Teams sonst monatelang entwickeln würden: containerisierte Agentenbereitstellung in einem beliebigen Framework (LangGraph, CrewAI, Strands Agents, OpenAI Agents SDK) sitzungsübergreifendes episodischer Arbeitsspeicher, MCP-basierter Toolzugriff mit Durchsetzung der Cedar-Richtlinie und kontinuierliche Qualitätsbewertung anhand von Live-Evaluatoren. Ein rechtliches SaaS-Team, das seine eigene Agenteninfrastruktur betreibt, beschäftigt in der Regel mehrere Techniker, die sich um die Containerisierung, die Sitzungsverwaltung und die Tool-Sicherheit kümmern. AgentCore konsolidiert diese Bedenken auf einer verwalteten Ebene, sodass diese Engineering-Kapazitäten für die Klauselbibliothek, die Risikotaxonomie und die kundenspezifischen Richtlinienregeln zur Verfügung stehen, mit denen sich Geschäfte abwickeln lassen.
Das Prinzip, das diese Ebene in den Vertriebszyklen eines Unternehmens ausmacht oder durchbricht, ist die Unterscheidung zwischen Mechanismen und guten Absichten:
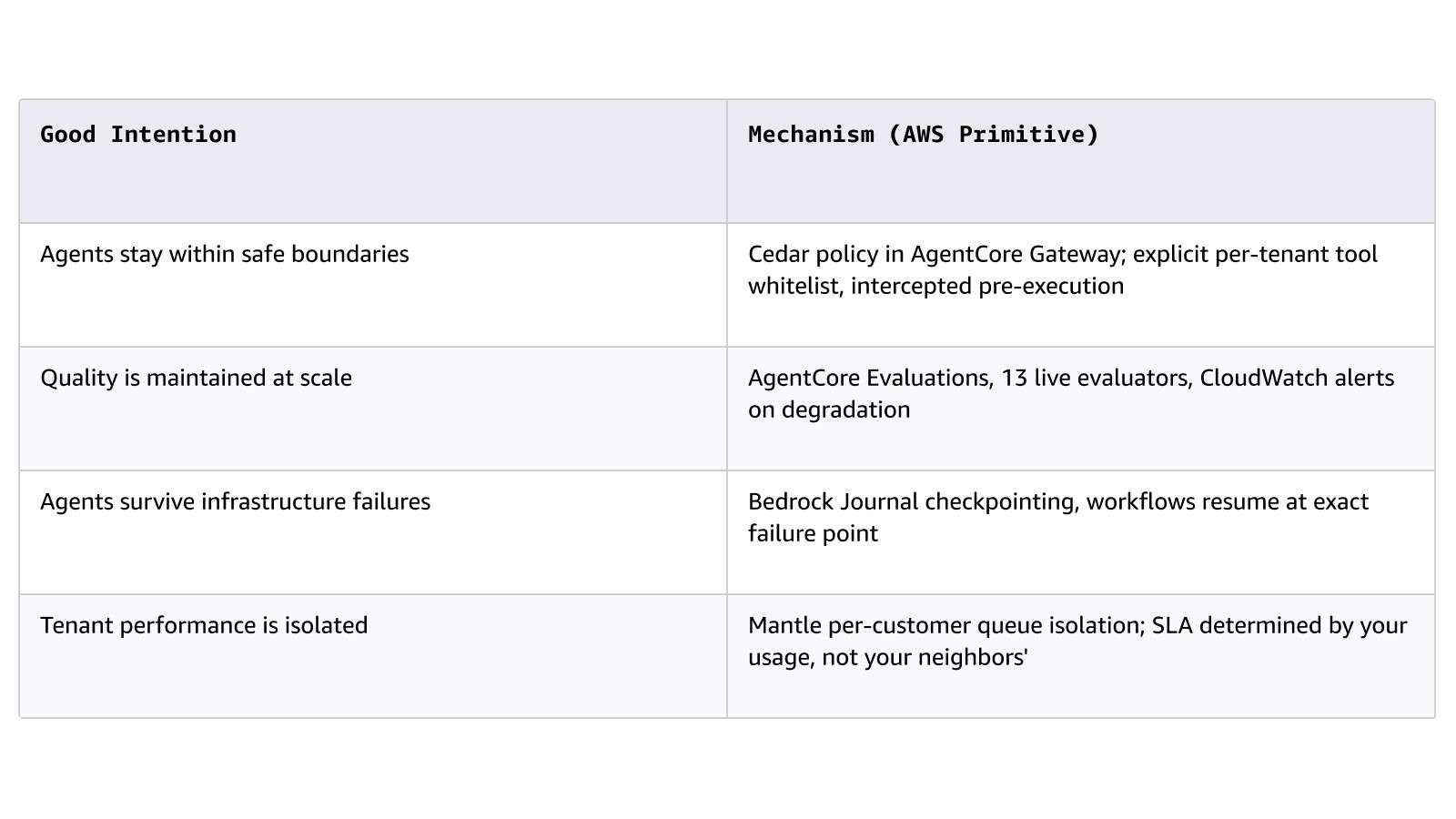
Wichtige Services: Amazon Bedrock (Project Mantle: Service-Stufen, Warteschlangenisolierung, Journal), AgentCore (Runtime, Memory, Gateway, Evaluations, Identity), Strands Agents, AWS Step Functions, Amazon Simple Queue Service (SQS).
Ausgangspunkt: Führen Sie die Unternehmensanforderungen auf, die Ihr Agent erfüllen muss, und ordnen Sie jede einzelnen Anforderungen einem konkreten Mechanismus zu, nicht einer Anforderungsstrategie.
Ebene 4: Orchestrierung und Berechnung
Dies ist die Ebene, auf der KI nicht mehr ein einziger Modellaufruf ist, sondern zur Software wird. Bei den meisten KI-Produkten für die Produktion handelt es sich um mehrstufige Systeme, die Kontext abrufen, Modelle aufrufen, Tools aufrufen, Ausgaben validieren, nachgelagerte Aktionen auslösen, Ergebnisse beibehalten und Workflows asynchron erneut aufrufen. Die Orchestrierung ist Teil der Kernanwendungsarchitektur und kein Implementierungsdetail.
Ziehen Sie eine SaaS-Plattform für Finanzdienstleistungen in Betracht, die Vertragsanalysen durchführt. Eine einzelne Anfrage könnte das Aufnehmen von Dokumenten, das Chunking, die Erstellung von Einbettungen, den Abruf anhand früherer Vereinbarungen, das mehrstufige Reasoning von Klauseln, die Weiterleitung an einen menschlichen Prüfer und das Auslösen eines nachgelagerten Compliance-Workflows beinhalten. Dabei handelt es sich um einen dauerhaften Anwendungsworkflow mit Verzweigungslogik, Wiederholungsversuchen, Zustandsübergängen und asynchronen Schritten, die sich über Minuten oder Stunden erstrecken, und nicht um einen einzigen Inferenzaufruf.
Die strukturellen Erkenntnisse hier spiegeln wider, was Serverless-Computing transformativ gemacht hat: Das Ziel besteht nicht nur darin, die Infrastruktur einfacher zu verwalten, sondern ganze Kategorien des Infrastrukturmanagements abzuschaffen. Lambda Managed Instances wendet dieses Prinzip auf eine häufig auftretende Lücke an. Manche Workloads erfordern spezielle Recheneigenschaften, viel Speicher für die eingebettete Generierung, Pipelines zur Dokumentenvorverarbeitung oder CPU-intensive Modellinferenz. Diese Ressourcen sind für einfache Serverless-Funktionen zu umfangreich, rechtfertigen aber kein direktes Flottenmanagement. Ein Startup, das täglich Tausende von Rechtsdokumenten verarbeitet, kann diese Funktionen auf bestimmten Instance-Profilen ausführen, während Lambda die Bereitstellung, Skalierung und das Patchen verwaltet und so eine Serverless-Architektur beibehält, ohne den Betrieb der EC2-Flotte zu übernehmen.
Für Teams, die eine umfassendere Laufzeitkontrolle benötigen, bietet EKS die bevorzugte Konsistenz und Kontrolle für Modellentwickler, die benutzerdefinierte Inferenzserver betreiben, oder Plattformteams, die auf Kubernetes standardisieren.
Amazon DynamoDB eignet sich auf natürliche Weise als transaktionale Kontrollebene für Workflow-Status, Sitzungsmetadaten, Mandantenkonfiguration, Idempotenzschlüssel, Tool-Ergebnisse und Audit-Referenzen. Es ist das betriebliche Rückgrat, das dafür sorgt, dass die Anwendung während der Arbeit über Services und Workflow-Schritte hinweg kohärent bleibt. Dies unterscheidet sich von der semantischen Speicherschicht, die für den Abruf verwendet wird.
Die KI-gestützte Entwicklungsumgebung Kiro passt als Beschleuniger für die Softwarebereitstellung in diese Ebene. Ihre Aufgabe besteht darin, Teams dabei zu unterstützen, Anforderungen natürlicher Sprache in strukturierte Designs, Spezifikationen und Implementierungsaufgaben umzusetzen, sodass Teams schneller vorankommen und gleichzeitig die Systemarchitektur kohärent bleibt.
Wichtige Services: Lambda Managed Instances, Lambda Durable Functions, Amazon DynamoDB, Amazon EC2 M9g (Graviton5), AWS Step Functions, Amazon ECS auf Graviton5, Amazon EventBridge, Amazon SQS.
Ausgangspunkt: Stellen Sie Ihren Arbeitsablauf auf Papier dar und identifizieren Sie jeden Schritt, der fehlschlagen, verzweigen oder asynchron ausgeführt werden könnte, bevor Sie sich für ein Orchestrierungs-Tool entscheiden.
Ebene 5: Unternehmensführung, Beobachtbarkeit und Vertrauen
Hier brechen immer noch viele KI-Stacks zusammen. Teams betrachten Governance als etwas, das später hinzugefügt werden kann. Mitarbeiter mit umfassendem Zugang zu Tools, begrenzter Genauigkeit bei der Bewertung und vagen, Prompt-basierten Einschränkungen, untergraben das Vertrauen und schaffen Hindernisse bei der Einführung. Das bessere Prinzip? Mechanismen, keine Absichten.
Unternehmenskäufer stellen zwei konsistente Fragen, bevor sie ein KI-System einführen: Können Sie nachweisen, dass unsere Daten niemals Mietergrenzen überschreiten? Und können Sie nachweisen, dass Ihre KI innerhalb der von Ihnen angegebenen Grenzen arbeitet, mit Mechanismen, die diese Grenzen durchsetzen, und Protokollen, die zeigen, was passiert ist?
Für einen ISV im Gesundheitswesen bedeutet dies einen HIPAA-spezifischen Agenten, der außerhalb des autorisierten Kontextes eines Patienten nicht auf Aufzeichnungen zugreifen kann. Für einen SaaS-Anbieter von Finanzdienstleistungen ist das ein Assistent für Investmentanalysen, dessen Nutzung durch kundenspezifische Datenzugriffsvereinbarungen eingeschränkt ist. Dies sind Standardanforderungen für regulierte Unternehmensbereitstellungen, keine Randfälle.
Bedrock Confidential Computing befasst sich mit der Frage der Datenisolierung auf der Inferenzebene, indem es Daten während der Ausführung schützt und eine Laufzeitgrenze mit höherer Sicherheit bietet. Dienste wie Bedrock, AgentCore, Lambda und S3 können innerhalb eines einheitlichen Identitätsmodells betrieben werden, sodass die Zugriffskontrolle konsistent auf Daten, Modellaufruf und Nutzung der Agenten-Tools angewendet werden kann, ohne dass für jede Ebene ein separates Autorisierungssystem eingerichtet werden muss. Dieselben Richtlinien, die den Datenzugriff regeln, regeln auch Modellaufrufe und Tool-Berechtigungen. Die Protokolle der Werkzeuganrufe werden dann zu überprüfbaren Aufzeichnungen des Systemverhaltens.
Die Steuerung auf dieser Ebene umfasst auch mandantenorientierte Datenkontrollen, Modell- und Prompt-Versionierung, Rückverfolgbarkeit von Toolaufrufen und Workflows, Kostentransparenz nach Umgebung oder Kunde sowie durchgängige Beobachtbarkeit auf Anwendungs-, Workflow- und Modellebenen. Dies ist kein architektonischer Luxus, sondern ermöglicht es Teams, über das Systemverhalten nachzudenken, Vorfälle auf der richtigen Ebene zu untersuchen und die Einhaltung der Vorschriften nachzuweisen, ohne Ereignisse anhand von Rohprotokollen rekonstruieren zu müssen.
Für Teams, die in EMEA tätig sind, beeinflusst der regulatorische Kontext mehrere dieser architektonischen Entscheidungen. Die DSGVO-Anforderungen im Zusammenhang mit der Datenspeicherung bedeuten, dass die Isolierung von Mietern nicht nur eine Vertriebsanforderung für Unternehmen ist, sondern auch eine gesetzliche. Die auf S3-Präfixen basierende Isolierung und die Verschlüsselung pro Mandant sind die praktischen Mechanismen, mit denen diese Anforderung erfüllt wird. Mit dem EU-Gesetz über künstliche Intelligenz werden weitere Verpflichtungen in Bezug auf Transparenz und menschliche Aufsicht für KI-Anwendungen mit hohem Risiko eingeführt, die sich direkt auf die Protokollierung von Audits und die Rückverfolgbarkeit von Tool-Calls Aufrufen.
Beachten Sie, dass Bedrock Model Availability, S3 Vectors und AgentCore nicht in allen AWS-EMEA-Regionen einheitlich verfügbar sind. Teams sollten die Verfügbarkeit in ihrer Zielregion überprüfen, bevor sie sich auf eine bestimmte Architektur festlegen.
Startup-Teams sollten auch beachten, dass einige der oben genannten Services, darunter S3 Vectors und AgentCore, in Produktionsumgebungen relativ neu sind. Prüfen Sie den Reifegrad für Ihren speziellen Anwendungsfall und Ihre Region, bevor Sie diese als Kerninfrastruktur festlegen.
Wichtige Services: Amazon Bedrock (vertrauliche Datenverarbeitung), AWS Identity and Access Management (IAM), Amazon CloudWatch, AgentCore Policy (Cedar), AgentCore Evaluations, AWS Security Hub.
Ausgangspunkt: Entscheiden Sie, was Ihr Auditprotokoll Käufern oder Compliance-Beauftragten nachweisen muss. Arbeiten Sie dann rückwärts zu den Richtlinien und Tools, die Sie benötigen.
So kommt das gesamte System zusammen
Eine Benutzeranfrage geht in die Anwendung ein. Die Laufzeit authentifiziert die Anfrage und löst den Mandantenkontext auf. Relevantes Speicher- und Produktwissen wird aus der Kontextebene abgerufen. Die Orchestrierungsebene bestimmt, ob es sich bei der Aufgabe um eine einfache Modellinteraktion oder um einen mehrstufigen Workflow handelt. Die Inferenzschicht generiert oder begründet im nächsten Schritt. Richtlinien schränken ein, welche Tools aufgerufen werden können. Bei lang andauernden Schritten wird der Status überprüft und bei einem Ausfall sauber wiederhergestellt. Das System sendet in jeder Phase Telemetrie aus. Bewertungen und Feedback-Schleifen messen die Qualität im Laufe der Zeit. Produktteams nutzen diese Signale, um Aufforderungen zu verfeinern, Richtlinien zu aktualisieren, den Abruf zu verbessern oder zu entscheiden, wann eine umfassendere Modellanpassung gerechtfertigt ist.
Das ist Systemdenken in der Praxis. Die überzeugende Architektur ist diejenige, die Daten, Kontext, Inferenz, Arbeitsabläufe, Steuerung und Abläufe in einem kohärenten System zusammenführt, das sich gut an die Skalierung des Unternehmens anpasst.
Für die meisten Startup-Teams ist der Einstiegspunkt Ebene 1. Isolieren Sie Ihre Datenbasis und Mandanten, bevor Sie sich mit Agenten oder der Orchestrierung befassen. Die darauf folgenden Ebenen sind nur so zuverlässig wie das Fundament, das ihnen zugrunde liegt.
Entwickeln Sie es. Besitzen sie es.
Ein gut durchdachter KI-Stack verbessert die Markteinführungszeit, die Zuverlässigkeit, das Vertrauen und die Kostendisziplin, nicht aufgrund eines einzelnen Services, sondern weil die Ebenen als kohärentes System zusammenarbeiten. Wenn der Stack systemorientiert ist, können Teams ihre Architektur an das Wachstum des Unternehmens anpassen, ohne jedes Mal, wenn eine neue Funktion auftaucht, von Grund auf neu aufbauen zu müssen.
Wie war dieser Inhalt?